
分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y = f(x) を構築し、構築したモデルに x の値を入力して y の値を予測したり、y が目標値となる x の値を設計したりします。
構築したモデルに対して、特徴量(変数)の重要度や、y への寄与を計算し、モデルを解釈したり、次の解析に役立てたりすることがあります。変数重要度 (特徴量重要度) としては、任意の回帰分析手法で安定的かつ、x 間の相関を考慮しながら検討できる Cross-validated Permutation Feature Importance(CVPFI) がオススメです。
y への x の寄与度としては、y を変化させるのに寄与する局所的な x の寄与度を求められる Local Slope of Model Prediction (LOMP) がオススメです。
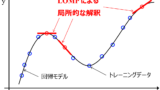
それでは、これらの方法で特徴量(変数)の重要度や y への寄与を計算したのちに、計算結果をどのように検証したらよいのでしょうか。
モデルの予測精度の検証でしたら、トレーニングデータとテストデータに分割して、トレーニングデータで構築したモデルの予測精度をテストデータで検証したり、ダブルクロスバリデーションしたときの予測精度を検証したりすることができます。これは、y の実測値という正解があるため、正解とどれだけ近いかという検証ができるためです。
一方で変数重要度や y への寄与度には正解がありません。そもそも、重要な x や y に寄与しているx がわからない状況なので、データ解析・機械学習を行っているともいえます。
ある x が y に対して重要であるかどうか確認するためには、確認したい x 以外の x をすべて固定して、その x のみ値を変化させたときに、y がどれくらい小さくなるか、大きくなるかを検証する必要があります。このようなデータが手持ちのデータセットの中にあればよいですが、基本的には実験計画法で x を振っていたり、収集したデータセットの中にはちょうどある一つの x のみ振ったようなデータはなかったりすると思います。
そのため、変数重要度や y への寄与度を本当に検証したいのであれば、上のような状況を実験で検証する必要があります。変数重要度であれば、重要度の大きい変数のみ値を変化させ、それ以外の x は固定した条件で実験を行い、y がどれくらい変化するか検証します。局所的な y への寄与度であれば、あるサンプルから寄与度の分だけ x の値を変えて実験を行い、y の変化を検証します。
以上のように変数重要度や y への寄与度には正解がありませんので、その結果を検証するためには、変数重要度や y への寄与度の検証ができるように意図的に実験条件を振り、実験で検証する必要があります。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

