分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y = f(x) を構築し、構築したモデルに x の値を入力して y の値を予測したり、y が目標値となる x の値を設計したりします。
金子研において、学生が研究室配属になった後は、新人研修として Python プログラミングを学んだり 色々なデータ解析・機械学習をしたりします。そして毎週、進捗の状況を報告してもらっています。その報告する資料の作り方として、データ解析・機械学習の結果は図表にしましょう、ということは、こちらに書いた通りです。

例えば図で表したときに、何らかの散布図で表されることが多いです。例えば、回帰分析を行った後の y の実測値 vs. 予測値のプロットや主成分分析などで特徴量の低次元化をしたあとの第一主成分 vs. と第二主成分の散布図などです。散布図は、文字通り “点” が散らばっている図になり、学生にはよく、それぞれの “点” が何を意味するのか考えるように伝えています。
というのも、Python コードを作り、それを実行して結果が出てくると、それだけで嬉しくなってしまい、結果としての図を丁寧に見なかったり、図に基づく次の検討に進めなかったりすることがあります。図を作って満足してしまったり、それっぽい図ができただけで終えてしまったりします。
しかし、データ解析・機械学習はあくまで手段の一つであり、その結果を使って何か別に達成したい目的があるはずです。数理モデルを構築するのが目的ではなく、数理モデルを使って何かをすることが目的です。解析結果である散布図の中で、単に数値データを扱う上では、点と認識するだけで問題ないかもしれませんが、その結果を使って (別の) 目的を達成するためには、その各点が何を意味するか理解しながら考察する必要があります。
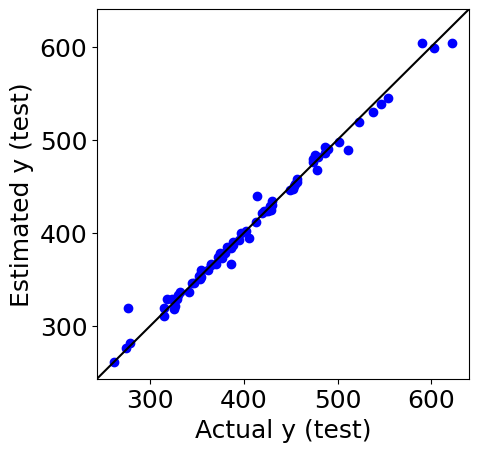
例えば、下の実測値 vs. 予測値プロットは、プログラミング課題

にもある、水溶解度の測定された化合物のデータを使って得られた結果です。
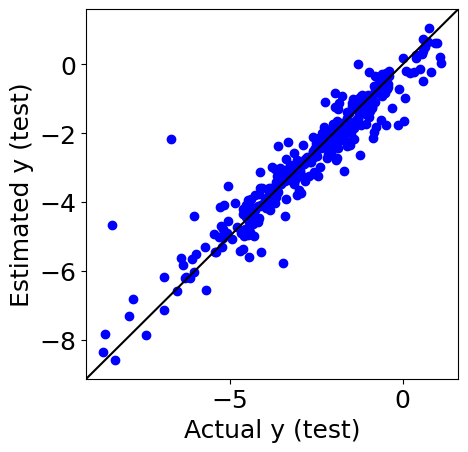
もちろん、各点は水溶解度の実測値とモデルによって予測された値とで描画されていますが、その裏には、それらの点一つ一つは有機化合物である、という意味があります。その上で結果をながめると、化合物ごとに誤差が異なることに気付いたり、誤差の大きな化合物はどんな化合物なのか、といったことを考えたり、その化学構造を確認したりできるようになります。
下の図は、上と同じ実測値 vs. 予測値プロットを表しますが、これは臨界温度の測定された超伝導体のデータを使って得られた結果です。
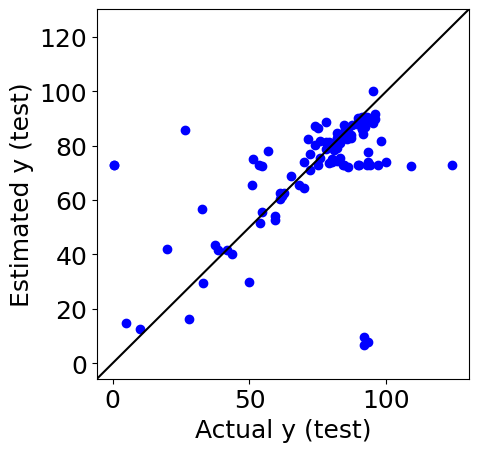
各点は金属酸化物を表す、という意味があります。これを踏まえると、次の考察に移れます。
このように、図をただの点や線としてみるのではなく、その裏にどんな意味があるのかを念頭に入れて図を見たり考察したりすることが重要です。そして、そのような考察ができるようになると、データ解析や機械学習を余すことなく有効に活用でき、当初の目的達成に繋がると考えられます。
以上です。
質問やコメントなどありましたら、X, facebook, メールなどでご連絡いただけるとうれしいです。