
化学プラント・産業プラントにおける測定が難しいプロセス変数の値を、機械学習・人工知能で推定しよう! というのがソフトセンサーですが、
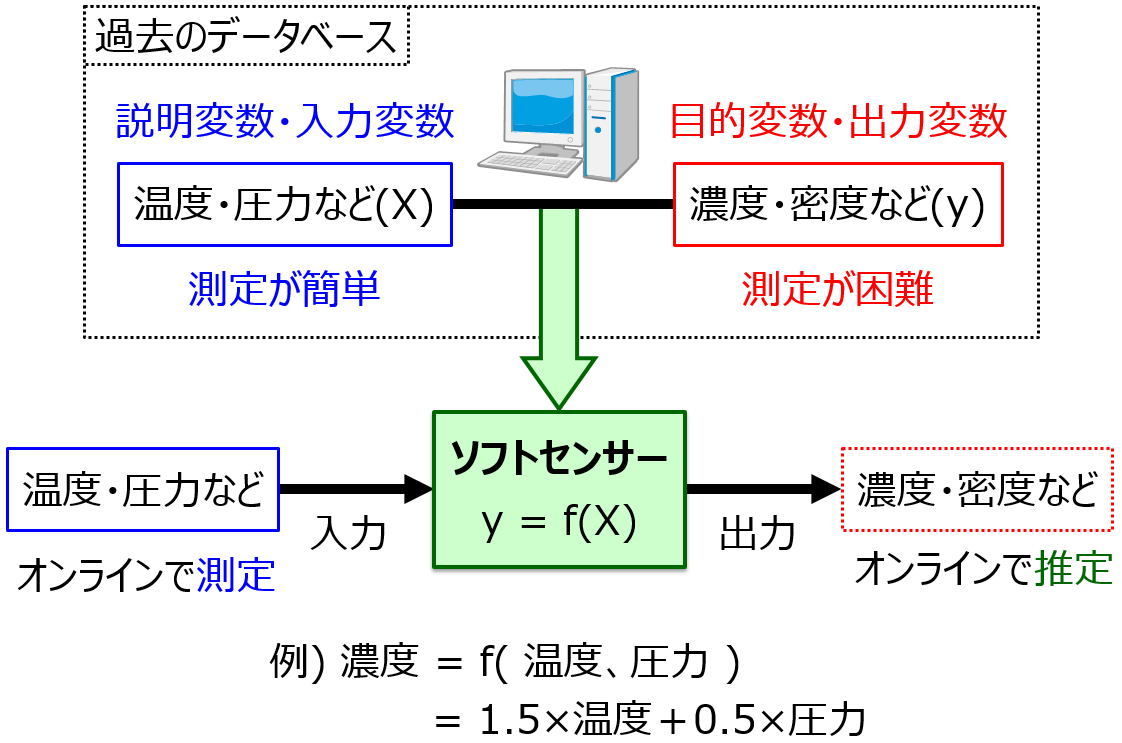
プラントでソフトセンサーを用いるときは、基本的に適応型ソフトセンサー (Adaptive Soft Sensor) として用います。プラントでは時々刻々とプロセスの状態が変化していますので、自動的に状態変化に合わせる仕組みを搭載させたのが適応型ソフトセンサーです。詳しくはこちらをご覧ください。
ただ、適応型ソフトセンサーというものを理解できて、使えそうだと思っても、対象のプラントのデータで、適応型ソフトセンサーの検証をしないと、実際のところはわかりません。適応型ソフトセンサーで、実際のプラントと同じ状況において、どのくらいの精度で目的のプロセス変数の値を推定できるのか、確認したいのではないでしょうか?
というわけで、いくつかの適応型ソフトセンサーを実際に検討できる Python プログラムを作成しました。こちらにあります。
実行用のファイルは demo_of_adaptive_soft_sensors.py です。実行するときは、functions.py も同じフォルダ (ディレクトリ) に置いてください。functions.py では非線形項(二乗項・交差項) を追加するときに処理する関数や、時間遅れ変数を追加するときに処理する関数や、LWPLS (Locally-Weighted Partial Least Squares) を実行する関数があります。debutanizer_y_10.csv がサンプルデータセットであり、functions.py と同様に置いてください。
下の図のようなデータセット (csv ファイル) があれば、実際にソフトセンサーの検討ができます。
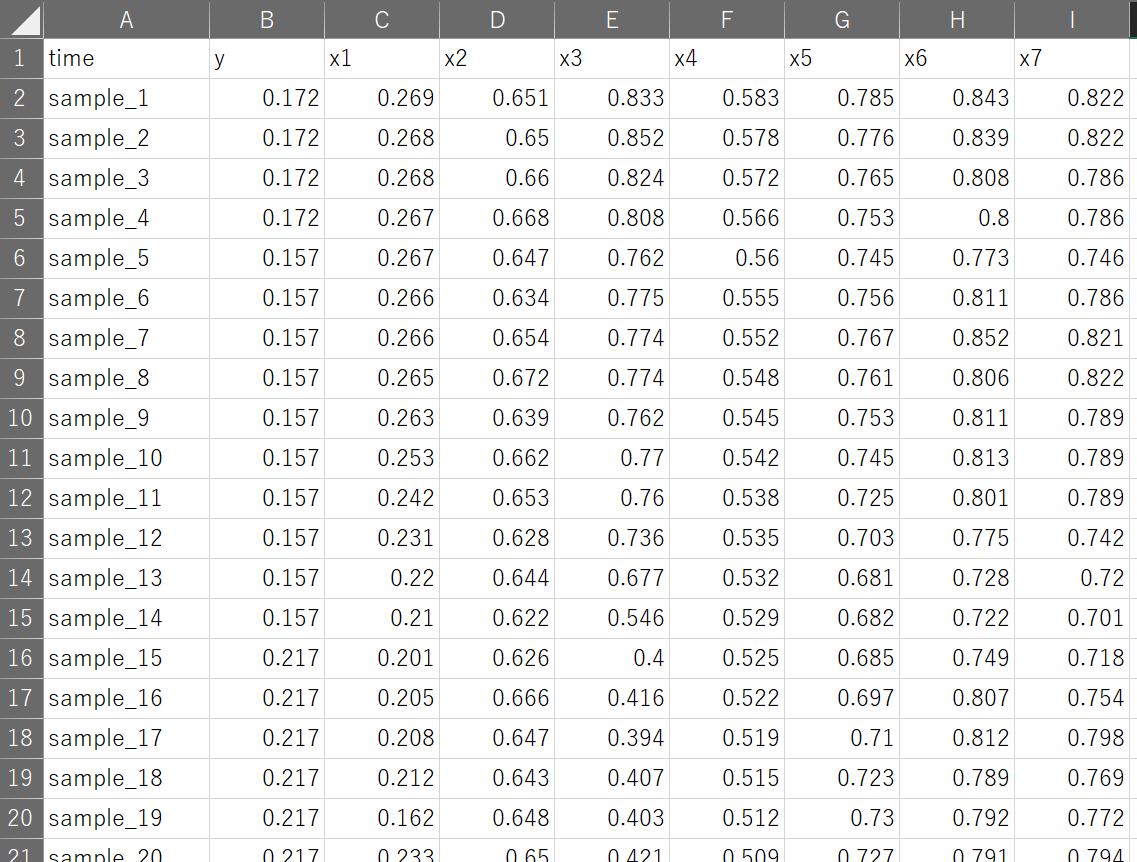
一番左の列がサンプル名であり、その次が目的変数 y であり、これをソフトセンサーで推定します。さらに説明変数 x1, x2, … と並びます。一番上の行は変数の名前であり、サンプルが時系列順に並びます。ちなみに、デモンストレーション用のデータセットはこちらの本 [1] にあるデブタナイザーのデータセットです。y が測定されていない時刻には、直近の時刻における測定値 (同じ値) が入っています。デモ用のデータセットでは説明変数の数は 7 ですが、それより多くても少なくても構いません。
[1] Fortuna, L., Graziani, S., Rizzo, A., Xibilia, M.G., Soft Sensors for Monitoring and Control of Industrial Processes, Springer, 2007
number_of_test_samples でテストデータのサンプル数を設定できます。一番うしろから、number_of_test_samples だけテストデータとして選択され、ソフトセンサーでこのサンプルの y の値が推定されます。推定値は、estimated_y_test.csv というファイルに保存され、実測値 vs. 推定値プロットや実測値と推定値との時間プロットが描画されたり、r2、RMSE、MAE などの統計量が表示されたりします。
どんな検討ができるの??
7 つのソフトセンサーでの検討
今のところ、搭載されているソフトセンサーは以下の 7 つです。なお PLS (Partial Least Squares) や SVR (Support Vector Regression) について詳しく知りたい方はこちらをご覧ください。

- ‘pls’ : 最初のトレーニングデータで構築した PLS モデル (これは適応的ソフトセンサーではありません)
- ‘svr’ : 最初のトレーニングデータで構築した SVR モデル (これは適応的ソフトセンサーではありません)
- ‘mvpls’ : Moving Window PLS (MWPLS)、直近のデータセットで構築された PLS モデル
- ‘mvsvr’ : Moving Window SVR (MWSVR)、直近のデータセットで構築された SVR モデル
- ‘jitpls’ : Just-In-Time PLS (JITPLS)、予測用サンプルに近いサンプルのデータセットで構築された PLS モデル
- ‘jitsvr’ : Just-In-Time SVR (JITSVR)、予測用サンプルに近いサンプルのデータセットで構築された SVR モデル
- ‘lwpls’ : Locally-Weighted PLS (LWPLS)、詳細はこちら
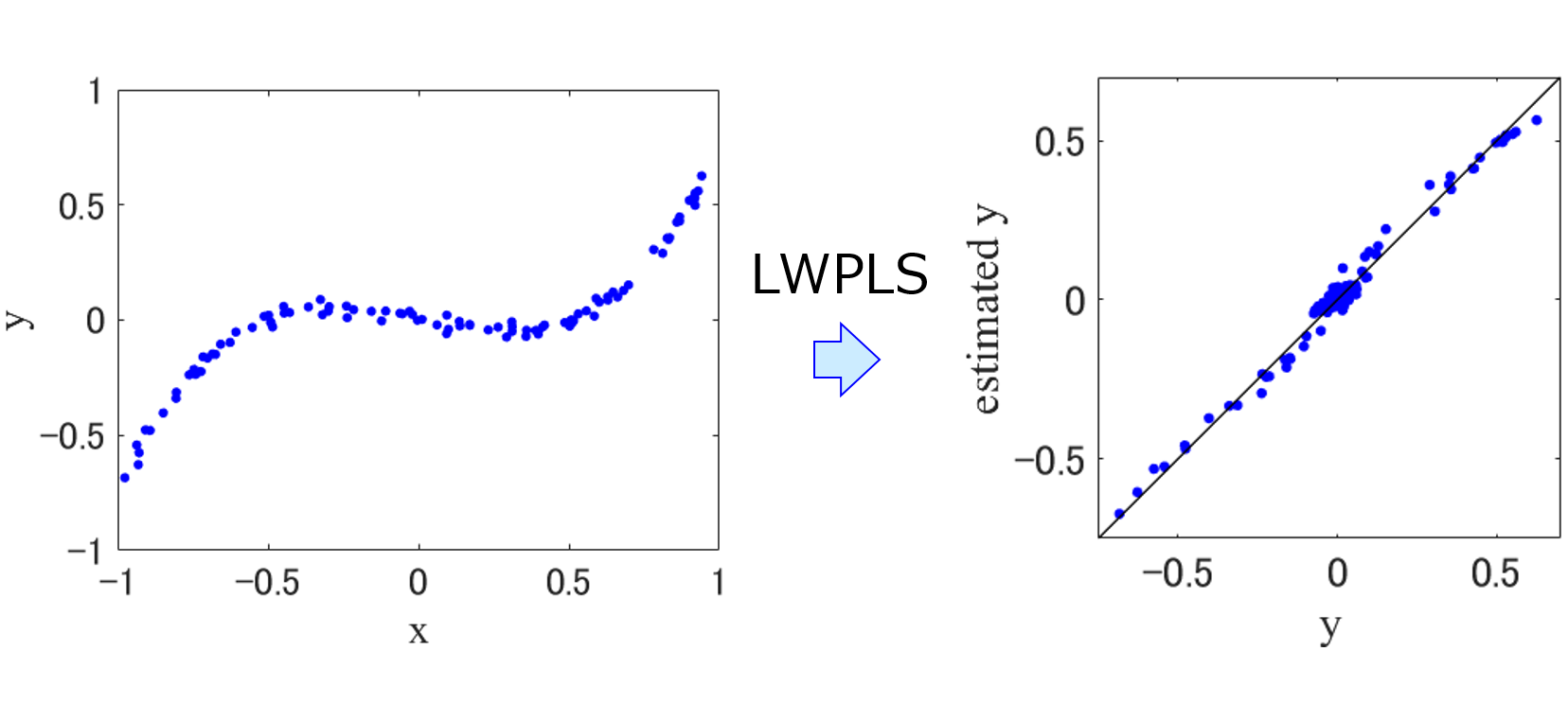
method_name という変数で、7 つの中からソフトセンサーを設定できます。
MW や JIT におけるモデル構築用データセットのサンプル数を変更して検討
MW モデルでは直近に y が測定されたサンプルを用いて回帰モデルを構築します。JIT モデルの中で JITPLS と JITSVR では、予測用サンプルに近いサンプルをトレーニングデータの中から集めて回帰モデルを構築します。それぞれ number_of_samples_in_modeling という変数で、1 つ 1 つのモデルを構築するときに用いられるサンプル数を設定できます。
実際の y の測定間隔で検討
上の図でも示しましたデブタナイザーのデータセット debutanizer_y_10.csv では、y の列において、値が同じものが 10 個ずつ並んでいます。これは、基本的にソフトセンサーが用いられる対象は、説明変数 x1, x2, … と比べて、測定頻度が低く、y の値が測定されていない時刻においては、直近に測定された y の値がそのまま入っているためです。10 分ごとのサンプルでしたら、y は 100 分に一度測定されている、ということです。
今回のプログラムでは、このようなデータセットでも、y が測定された時刻のサンプルのみ集めてモデルを構築したり、y が測定されていない時刻の y の値を推定したりできます。
実際に y の測定にかかる時間で検討
y にあたるプロセス変数は、測定間隔が低いだけでなく、y の測定にある程度の時間がかかることが多いです。そのためソフトセンサーでリアルタイムに (もしくはある程度先を予測して) 値を予測したい、となるわけです。MW モデルや JIT モデルにおいて、y が測定されたサンプルはデータベースに追加されますが、y の測定にかかる時間を考慮しないと、実際にはまだ y の測定が終わっていないようなありえないタイミングで、データベースが更新されてしまいます。もちろん最終的な推定結果はよく見えるのですが、実際とはかけ離れているため、無意味です。
今回のプログラムでは、y_measurement_delay という変数で、y の測定にかかる時間、つまりデータベースへのサンプルの追加を遅らせる時間を設定できます。たとえば、10 分ごとのサンプルで y_measurement_delay = 6 とすれば、y の測定には 60 分かかる状況を想定してソフトセンサーの検討ができます。
説明変数 x1, x2, … について、目的変数 y に対する時間遅れを検討
こちらに書いたように、
ある時刻における説明変数 X の値と y の値とが関係しているのではなく、ある時刻における y の値と関係しているのは、時間的に過去の X の値であることがあります。そのため、ソフトセンサーの検討をするときには、X としてある時間を遅らせたプロセス変数を用いることが一般的です。
今回のプログラムでは、dynamics_max という変数でどれくらい時間を遅らせるかの最大を、dynamics_span でその間隔を設定できます。たとえば dynamics_max = 10, dynamics_span = 2 のとき、2, 4, 6, 8, 10 と遅らせた X の変数が追加されます。時間を遅らせない X の変数とあわせて、変数の数が 6 倍になるわけです。5 分ごとのサンプルでしたら、10 分、20 分、30 分、40 分、50 分 遅らせた X の変数を、時間を遅らせない変数に追加できるということです。
説明変数 X と目的変数 y の間の非線形性を検討
SVR で X と y の間の非線形性を検討することはできますが、さらに、もちろん PLS の場合でも、X の変数を二乗した変数 (二乗項) やすべての変数の組み合わせてかけ合わせた変数 (交差項) を追加することができます。
add_nonlinear_terms_flag という変数を True にすると、二乗項と交差項が追加されます。
たとえば、
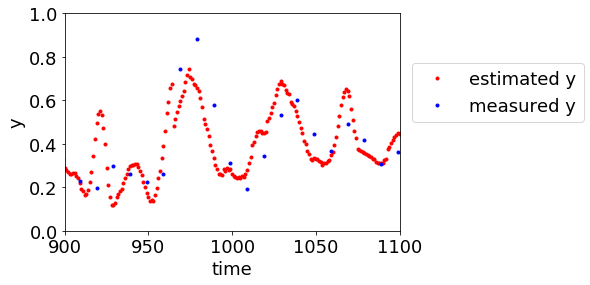
今回のプログラムで、デブタナイザーのデータセットにおいて後半の 1000 サンプルをテストデータとして、適応型ソフトセンサーの検討をすると、MWPLS ではこんな感じになります↓
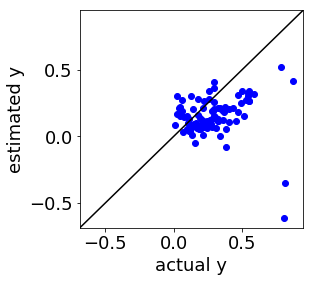
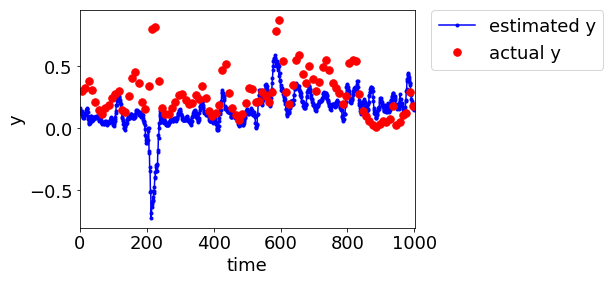
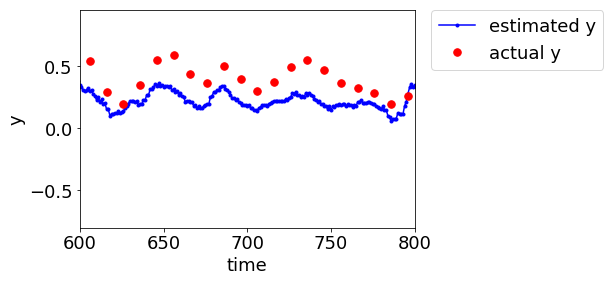
LWPLS ではこんな感じです↓
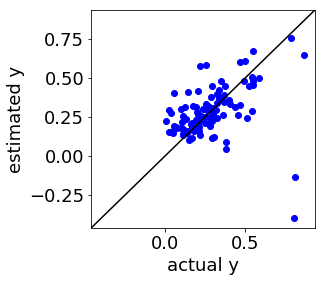
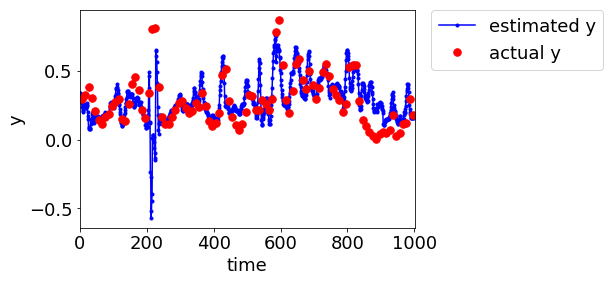
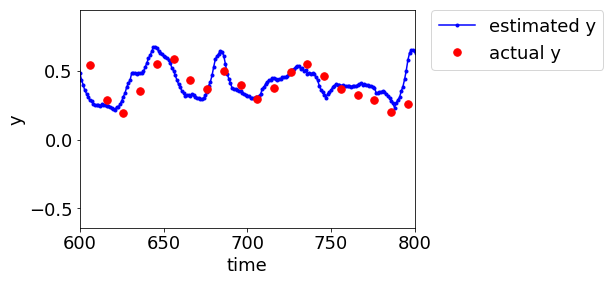
ぜひプログラムを活用して、ご自身のプラントデータで適応型ソフトセンサーを検討していただけたらと思います!
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

