
変数がたくさんある多変量データを解析する前に、変数の標準化 (オートスケーリング) をすることは、こちらに書きました。

データセットの可視化手法であり低次元化手法でもある主成分分析 (Principal Component Analysis, PCA) の前も例外ではありません。変数の標準化を行ってから PCA をすることになります。PCA についてはこちらをご覧ください。
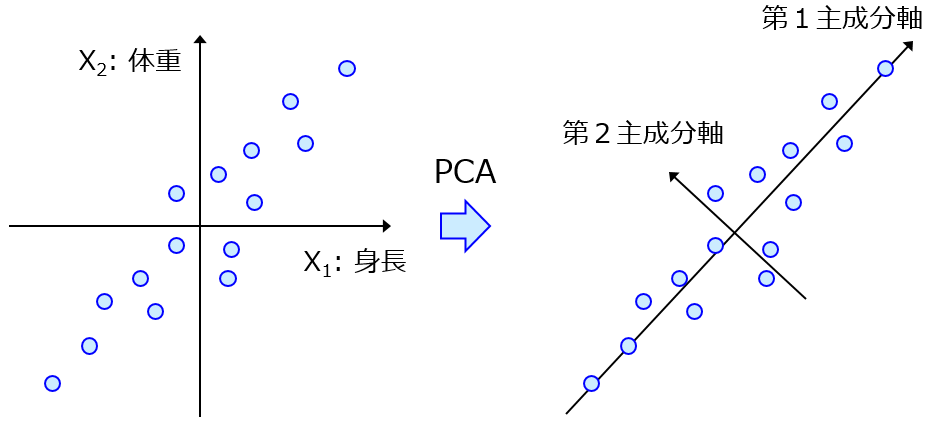
PCA の説明をすると、変数の標準化をすることについての質問がよくきます。これこれこういうデータセットなのですが、変数の標準化をする必要はありますか、といった感じです。
今回は変数の標準化をするかしないかの判断について書きます。まずはじめに、
変数のセンタリング (平均値を 0 にする操作) はどの変数も必ず行いましょう!
変数の標準化は、センタリング (平均値を 0 にする操作) + スケーリング (標準偏差を 1 にする操作) です。
センタリングを必ずしなければならない理由について説明します。PCA では、分散が最大化になるように主成分軸を決める、とうたっていますが、実際に行っていることは、主成分スコアの二乗和を最大化することです。分散は、それぞれの値から平均値を引いたものを二乗して足し合わせて、最後に (サンプル数-1) で割ることで計算できます。二乗和とは異なりますね。主成分の分散の最大化と、主成分スコアの二乗和の最大化とが同意になるためには、主成分の平均値が 0 でなければなりません。主成分の平均が 0 であれば、分散は主成分スコアの二乗和を (サンプル数-1) で割ったものになりますので、(サンプル数-1) は最大化には関係なく、主成分の分散の最大化 = 主成分スコアの二乗和を最大化 になります。主成分は、変数の線形結合 (ローディングが結合の重み) で表現されますので、すべての変数の平均値が 0 であれば、主成分の平均値も 0 です。主成分の平均値を 0 にするため、変数のセンタリングが必要になるわけです。
変数が 0, 1 で表現されるバイナリの変数やダミー変数のときでも、センタリングをしましょう。もちろん、0, 1 の変数における平均値は 1 の数の割合であり、その値を引くことに意味はないと考えるかもしれません。しかし、主成分は 0, 1 に基づく変数の、線形結合で表されます。元の変数は 0, 1 の変数だとしても、主成分は連続的な変数であり、正規分布に従うかもしれません。そのようになったときにも、主成分の平均値が 0 になるように、元の変数が 0, 1 の変数であったとしても、センタリングを行いましょう。
ちなみに同じ理由で、部分的最小二乗回帰 (Partial Least Squares Regression, PLS) を行う前にも、説明変数も目的変数もセンタリングを行う必要があります。
次にスケーリング (標準偏差を 1 にする操作) についてです。まず、
単位系が異なるときはスケーリングも必ず行いましょう!
温度や長さや重さなど、また同じ長さでも km と mm など、いろいろな単位系があるときには、変数ごとにスケールが全く異なります。センタリングだけでなく、スケーリングも必ず行いましょう。
そして最後に、
単位系がすべて同じのときでも、特別な理由がない限りはスケーリングを行いましょう!
すべての変数の単位が温度だったり、すべての変数が 0, 1 のバイナリ変数やダミー変数であったりしても、基本的にはスケーリングを行ってください。PCA のアルゴリズム的に、分散の大きな変数の主成分に対する影響が大きくなってしまいます。主成分を見たときに、たまたま分散の大きかった変数とほとんど同じ、といった状況も起こります。分散の大きな変数も小さな変数も、同じように見てデータセット全体の様子を可視化できるようにするため、すべての変数にスケーリングを行うわけです。
逆に、分散の大きさに比例して、主成分に対する変数の重みを大きくしたいときには、スケーリングは行いません。ただ、わたしの経験の中では、ほとんどスケーリングを行わないほうがよいケースはありません。少しでも迷ったら、センタリングに加えてスケーリングも行いましょう。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

