
金子研オンラインサロンにおいて、
メンバーの方からクロスバリデーションのとき変数の標準化 (オートスケーリング) に関して質問がありました。とても大事な視点であり、一言では回答できない内容でしたので、ブログで取り上げさせていただきました。
質問の内容は、回帰分析のプログラミング課題において、

テストデータを予測するときは、トレーニングデータの平均値・標準偏差を用いてテストデータのオートスケーリングをするのに、クロスバリデーションでは最初にトレーニングデータでオートスケーリングしているだけなのはどうして?クロスバリデーションの分割ごとにオートスケーリングしないの?、といったものです。
解析の流れを整理しながら、回答します。データセットが与えられたら、トレーニングデータとテストデータに分けます。テストデータにおける目的変数の値は未知と仮定して、いろいろな回帰分析手法でモデルを作ってみて、それぞれのモデルでテストデータを推定します。その後、実際はテストデータの目的変数の値 (正解) はわかっていますので、正解を用いてそれぞれのモデルの推定性能を検証します。推定性能の高かったモデルを構築した回帰分析手法を実際に使おう!、となるわけです。
テストデータを推定する目的は、目的変数が未知のサンプルに対するモデルの推定性能を検証することで最終的に用いる回帰分析手法を決めること
ということです。推定したいデータ (テストデータ) における目的変数の値は未知であることが前提ですので、トレーニングデータとテストデータとを合わせた平均値・標準偏差でオートスケーリングすると、テストデータの目的変数の値が事前にわかっていることになってしまい、おかしな話ですので、目的変数の値がわかっている (と仮定した) トレーニングデータの平均値・標準偏差でオートスケーリングします。
もちろん、説明変数に関しては値がわかっていますので、説明変数に限っては、トレーニングデータとテストデータとを合わせた平均値・標準偏差を用いてオートスケーリングできます。ただ、推定したいデータ (テストデータ) が変われば、平均値・標準偏差が変わり、オートスケーリングの結果が変わりますので、そのサンプルを用いて構築されたモデルも変わってしまいます。推定したいデータの外れ値によってモデルが不安定になる可能性がありますので、基本的には説明変数もトレーニングデータの平均値・標準偏差でオートスケーリングします。
また、部分的最小二乗回帰(Partial Least Squares Regression, PLS)
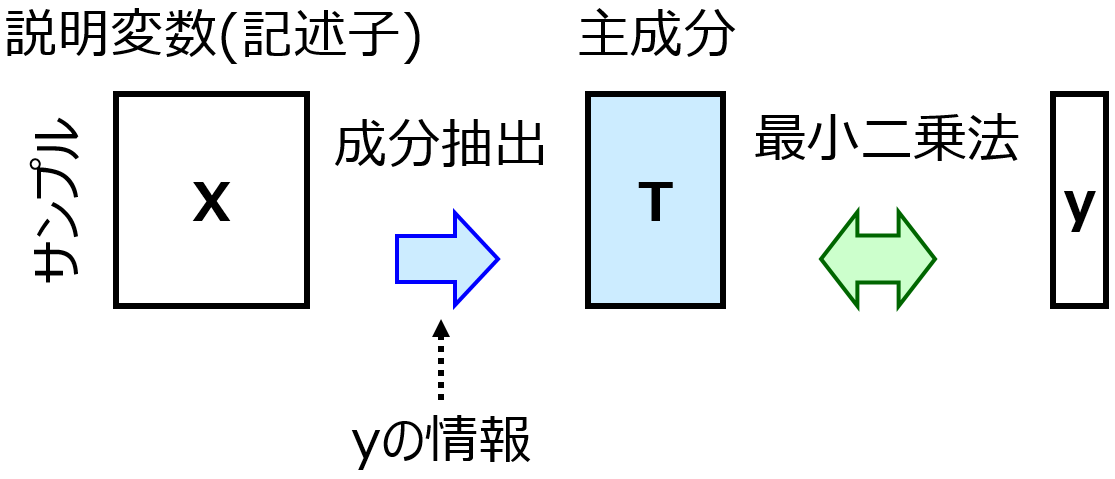
のように、トレーニングデータの説明変数 (と目的変数) の平均値が 0 であることが前提の手法では、トレーニングデータとテストデータとを合わせた平均値・標準偏差でオートスケーリングすると、トレーニングデータのみでの平均値が 0 からズレてしまい問題です。
続いてクロスバリデーションについて考えます。上ではトレーニングデータでモデルを構築して、テストデータの推定を行う、といった話をしましたが、回帰分析手法によっては、モデルを構築する前に決めなければならないパラメータ (ハイパーパラメータ) があります。多くの場合、ハイパーパラメータを決めるのにクロスバリデーションが用いられます。

このような文脈で用いられるクロスバリデーションの目的はもちろん、ハイパーパラメータの値を決めること、です
目的変数の値が未知のデータに対する推定性能はテストデータで検証されますので、クロスバリデーションでは、適当なハイパーパラメータの値さえ決まってしまえば OK です。クロスバリデーションで分割した、すべてのグループにおいて目的変数の値がわかっていると仮定しても問題ないわけです。
これを踏まえて、クロスバリデーションにおけるオートスケーリングのやり方には、以下の 2 通りがあります。
- クロスバリデーションにおいて分割して得られる一部のトレーニングデータの平均値・標準偏差を用いて、同じく分割して得られるバリデーションデータのオートスケーリングをする
- クロスバリデーション前に、トレーニングデータ全体の平均値・標準偏差を用いて、トレーニングデータ全体のオートスケーリングをする
1. は、トレーニングデータとテストデータに分割したときのオートスケーリングに似ていてよさそうです。2. では、クロスバリデーションにおいて分割して得られるバリデーションデータの目的変数の値もわかっていること前提で、しかもクロスバリデーションにおいて分割して得られる一部のトレーニングデータの平均値は 0 からズレてしまいます。1. にはメリットしかなく、2. にはデメリットしかないのでしょうか。
実は 1. にもデメリットがあります。それは、
分割することでサンプルが少なくなり、それによりトレーニングデータで標準偏差が 0 の説明変数が出たときに、それを削除する必要がある
ことです。分割ごとに、分割して得られたトレーニングデータごとに説明変数のセットが変わることになり、説明変数の異なるモデルによる推定結果を評価することで適切なハイパーパラメータの値を決定できるのか、という疑問が残ります。
もちろん、クロスバリデーションで分割することで削除されそうな説明変数を、事前に削除することも考えられます。これでよい気もしますが、クロスバリデーションの有無で用いる説明変数が異なるのも変な気がします。
というわけで、1. の方法にも、2. の方法にも、メリット・デメリットがあり、どちらが正解というわけでもありませんが、総合的に考えて 2. の方法を採用しています。
ちなみに、プログラミング課題の解答例としては、なるべくどんなデータセットでもエラーが発生しないような方法にしている、といった理由もあります。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

