[無料公開] 「化学のためのPythonによるデータ解析・機械学習入門」 の “はじめに” と目次の詳細 こちらの書籍には改訂2版がございます。改訂2版でも無料公開の部分の内容は変わらない一方で、一章分+α を改訂2版では追記しておりますので、以下で興味を持っていただけましたら、改訂2版の購入をオススメいたします。2019 年 10 月 23 ... 2019.10.23 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー化学工学研究室
カーネル関数って結局なんなの?→サンプル間の類似度と理解するのがよいと思います! サポートベクターマシン (Support Vector Machine, SVM) や サポートベクター回帰 (Support Vector Regression, SVR) や ガウス過程回帰 (Gaussian Process Regr... 2019.10.21 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
一般的なモデルの逆解析とベイズ最適化を使い分けるために、両者の特徴や違いを説明します モデルの逆解析 (Inverse Analysis) について、ベイズ最適化 (Bayesian Optimization, BO) と一緒にお話しいたします。データセットがあるとき、いろいろな回帰手法を検討して、推定精度の最も高い回帰モデ... 2019.10.07 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
人を成長させる人工知能 以前に、人工知能が本質的に何をしているかを書きました。人工知能をつくったら、それを使わない手はありません。うまく使うことで、人工知能によって人が成長できるようになります。たとえば高機能性材料を開発しているとき、実験条件 x を決めて、実験し... 2019.09.22 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
[デモのプログラムあり] ガウス過程回帰(Gaussian Process Regression, GPR)におけるカーネル関数を11個の中から最適化する (scikit-learn) こちらのガウス過程による回帰 (Gaussian Process Regression, GPR)において、カーネル関数をどうするか、というお話です。そもそも GPR のカーネル関数はサポートベクター回帰 (Support Vector R... 2019.09.16 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
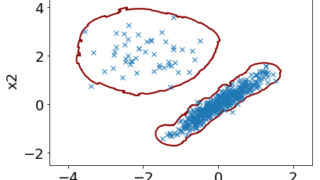
[デモのプログラムあり] Local Outlier Factor (LOF) によるデータ密度の推定・外れサンプル(外れ値)の検出・異常検出 Local Outlier Factor (LOF) について、パワーポイントの資料とその pdf ファイルを作成しました。LOF は k-nearest neighbor algorithm (k-NN) の発展版のようなもので、データ密... 2019.09.15 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
データ解析・機械学習のしやすいデータセットの作り方 データ化学工学研究室 (金子研) では、分子のデータや材料のデータやプロセスの時系列データなど、化学データ・化学工学データを扱ってデータ解析・機械学習をしています。データ解析の基本的な流れは、ある程度固まっていることから、データ解析を成功さ... 2019.09.10 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
人工知能は本質的に何をしているのか データ化学工学研究室 (金子研) では、基本的に化学データ・化学工学データを用いて、データ解析・統計解析・機械学習によって、数理モデル・数値モデル (人工知能) を作ったり、それを有効に使ったりする研究をしています。人工知能を作ところのイメ... 2019.09.08 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
DCEKit にバギングによるアンサンブル学習の機能を追加!scikit-learn の BaggingRegressor や BaggingClassifier との違いとは? データ解析・機械学習のためのツールキット DCEKit にバギングによるアンサンブル学習の機能を追加しました。アンサンブル学習というのは、回帰モデルだったりクラス分類モデルだったり、モデルをたくさん作って推定性能を上げよう!、といった手法で... 2019.09.02 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー研究室
ポリマーとモノマーのデータセットがあれば、こんなことができるようになりました! [金子研論文] 昨年度の金子研の四年生が主に研究していたテーマの成果が、Journal of Computer Chemistry, Japan にて論文公開になりました。タイトルは高屈折率および高ガラス転移温度をもつ高分子材料のモノマー設計です。下の U... 2019.09.01 ケモインフォマティクスケモメトリックスデータ解析化学工学研究室研究発表論文