欠損値のないサンプルがデータセットにないときの iGMR の使い方 データセットの中に欠損値があるときは、iGMR が有効であることはこちらに書きました。たとえば、論文や特許からデータを取得したときなど、他のデータ (研究室内や社内のデータなど) と合わせようとしたときに、論文や特許ではいくつかの実験条件が... 2021.02.21 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
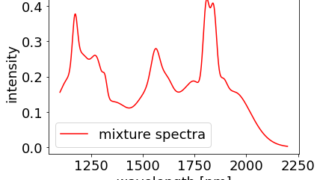
DCEKit に新機能追加 [v2.6.1]!トレーニングデータなしでスペクトルから濃度を推定する方法 DCEKit への新機能追加です。こちらの Iterative Optimization Technology (IOT) を実装しました。IOT では、純成分のスペクトルと混合物のスペクトルのみから、混合物における各純成分の濃度 (モル分... 2021.02.14 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
DCEKit に新機能追加 [v2.5.2]!Variational Bayesian Gaussian Mixture Regression(VBGMR)とクロスバリデーションによるGMR最適化 DCEKit に今回追加したのは Variational Bayesian Gaussian Mixture Regression (VBGMR) と、GMR や VBGMR におけるクロスバリデーションによるハイパーパラメータ最適化です。... 2021.02.11 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
「パターン認識と機械学習 下 ~ベイズ理論による統計的予測~」 データ解析・機械学習の中級者以上向けの、より深く学ぶための本 C.M. ビショップ 編, 「パターン認識と機械学習 下 ~ベイズ理論による統計的予測~」, 丸善出版, 2012丸善出版: Amazon: こちらの下巻です。Pattern Recognition and Machine Learning... 2021.02.07 データ解析研究室
「パターン認識と機械学習 上 ~ベイズ理論による統計的予測~」 データ解析・機械学習の中級者以上向けの、より深く学ぶための本 C.M. ビショップ 編, 「パターン認識と機械学習 上 ~ベイズ理論による統計的予測~」, 丸善出版, 2012丸善出版: Amazon: Pattern Recognition and Machine Learning、いわゆる PRM... 2021.01.31 研究室
ガウス過程による潜在変数モデルでプロセスデータの可視化やプロセス状態推定をしました![金子研論文] 金子研の論文が Analytical Science Advances に掲載されましたので、ご紹介します。タイトルはEstimation and visualization of process states using latent v... 2021.01.31 ケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー化学工学研究室論文
「化学のためのPythonによるデータ解析・機械学習入門(改訂2版)」 化学・化学工学のデータ解析・機械学習をしたい方へ 金子弘昌, 「化学のためのPythonによるデータ解析・機械学習入門(改訂2版)」, オーム社, 2023オーム社: Amazon: 自分の本の紹介で恐縮です。ただ、データ解析や機械学習による分子設計、材料設計、プロセス設計、プロセス管理・... 2021.01.24 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー化学工学研究室
単体・化合物と実験条件・製造条件の両方が変わるデータセットの解析の仕方 データセットを用いて説明変数 X と目的変数 Y との間でモデル Y = f(X) を構築するときの話です。材料のデータセットを扱うときは、X が化合物の化学構造や結晶構造や金属の特徴量だったり、単体や化合物の組成比だったり、その他の実験条... 2021.01.24 ケモインフォマティクスケモメトリックスデータ解析研究室
「統計学入門 (基礎統計学Ⅰ)」 統計学について学びたい方へ 東京大学教養学部統計学教室 編, 「統計学入門 (基礎統計学Ⅰ)」, 東京大学出版会, 1991東京大学出版会: Amazon: 統計学の入門書です。データ解析や機械学習をやる上で、必要な統計学の内容を学べます。他にもいろいろと統計学の本を... 2021.01.17 データ解析研究室
オーバーフィッティング(過学習)の本質を理解して実用的な議論をする 回帰分析やクラス分類を行うとき、オーバーフィッティング(過学習)をしないことが重要といわれます。オーバーフィッティングを防ぐため、クロスバリデーションでハイパーパラメータを決めたり、テストデータを用いて回帰分析手法やクラス分類手法を選んだり... 2021.01.17 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室