
分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y = f(x) を構築し、構築したモデルに x の値を入力して y の値を予測したり、y が目標値となる x の値を設計したりします。
予測精度の高いモデル構築を妨げる要因の一つに、モデルの過学習 (オーバーフィッティング) があります。新しいサンプルに対する予測性能を向上させるためには、このオーバーフィッティングとうまく付き合う必要があります。例えば、ノイズを含むデータセットにおいて、そのノイズにも過度に適合してしまった場合には、アンサンブル学習によりノイズの影響を軽減できます。ランダムフォレストや各種のブースティングの考え方です。
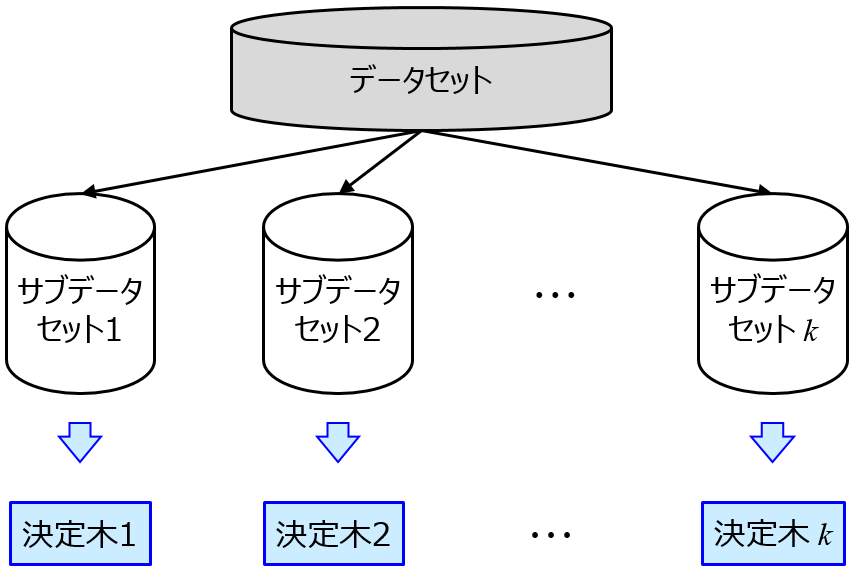


一方で、例えばソフトセンサーにおいて複数の銘柄 (品番など) を扱うプロセスで、ある銘柄に過度に適合するようなモデルが構築されることがあります。この場合に割り切って、それぞれの銘柄に “オーバーフィットした” モデルを (複数) 構築しておき、それらの複数のモデルを使い分けながら、y を予測することも重要です。もちろん、銘柄の切り替え時を予測するために、別途工夫する必要があります。
ソフトセンサーに限らず、実験系のデータ、材料のデータでも、事前に似たようなサンプル郡を分類しておくことができれば、それぞれのサンプル群ごとに特化したモデルを構築しておき、予測する時にはそれらのモデルを使い分けながら予測することができます。
事前に分類できない時には、クラスタリングと回帰分析を組み合わせることで、クラスターごとの予測精度に特化したモデル構築も検討できます。
この場合には、予測する時にどのモデルを使うかを選択することはできないので、y の予測に使用するのではなく、モデルの逆解析 (y から x の予測) に使用することになります。
以上のように、人工にモデルの過学習、オーバーフィッティングと言っても、状況によって対策が異なりますので、機械学習モデルを構築する目的やデータセットに基づいて状況整理しつつ、うまく付き合うのが良いでしょう。
以上です。
質問やコメントなどありましたら、X, facebook, メールなどでご連絡いただけるとうれしいです。
