
回帰モデルやクラス分類モデルを構築したら、モデルの逆解析を行うことで、目的変数の目標値を達成すると考えられる説明変数の値を推定できます。ただ、モデルの逆解析をするときは、いくつか注意点がありますので、チェックリストとしてまとめました。モデルの逆解析をするときはぜひご活用ください。
□ 目的変数 y の目標値もしくは目標範囲がある
□ 逆解析するモデルを構築するための手法を選択した明確な理由がある
□ 用いるモデルは、(トレーニングデータとテストデータとを合わせた) すべてのサンプルを用いて構築された
□ モデルの適用範囲を設定した

説明変数 x の値をモデルに入力して y の値を推定し、推定値が y の目標値に近い もしくは y の目標範囲内のサンプルを選択するタイプの逆解析のとき、
□ 入力する x を、モデルを構築したデータセットの x でオートスケーリング (標準化) した
□ 推定された y の値のスケールを、(モデルを構築したデータセットの y の標準偏差をかけて、平均値を足すことで) オートスケーリング前に戻した
□ アンサンブル学習でモデルの適用範囲を設定したり、ベイズ最適化をしたりするとき、y の標準偏差のスケールを、(モデルを構築したデータセットの y の標準偏差をかけることで) オートスケーリング前に戻した
y の目標値をモデルに入力して x の値を推定するタイプの逆解析のとき、
□ 入力する y の目標値を、モデルを構築したデータセットの y でオートスケーリング (標準化) した
□ 推定された x の値のスケールを、(モデルを構築したデータセットの x の標準偏差をかけて、平均値を足すことで) オートスケーリング前に戻した
決定木やランダムフォレストで構築された回帰モデルを用いるとき、
□ モデルの逆解析では、モデル構築に用いたデータセットの y の最大値を超えず、y の最小値を下回らないことを認識している
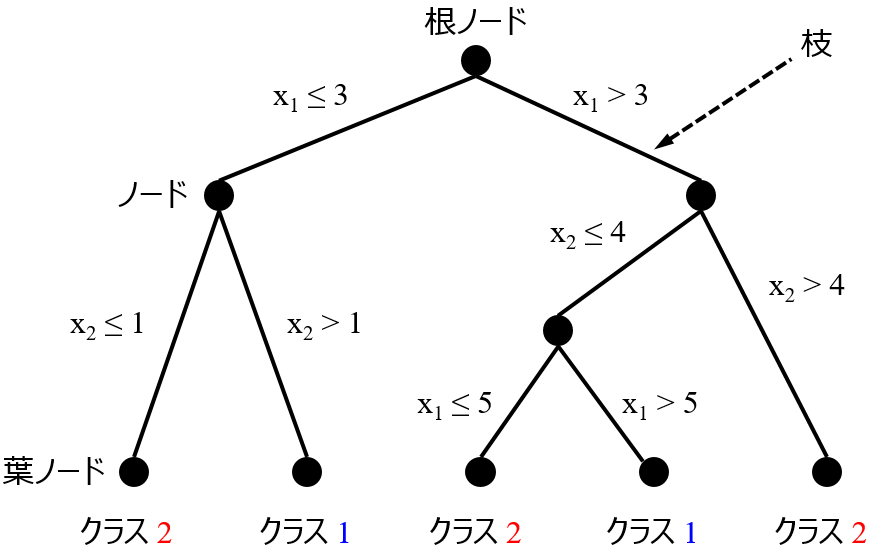
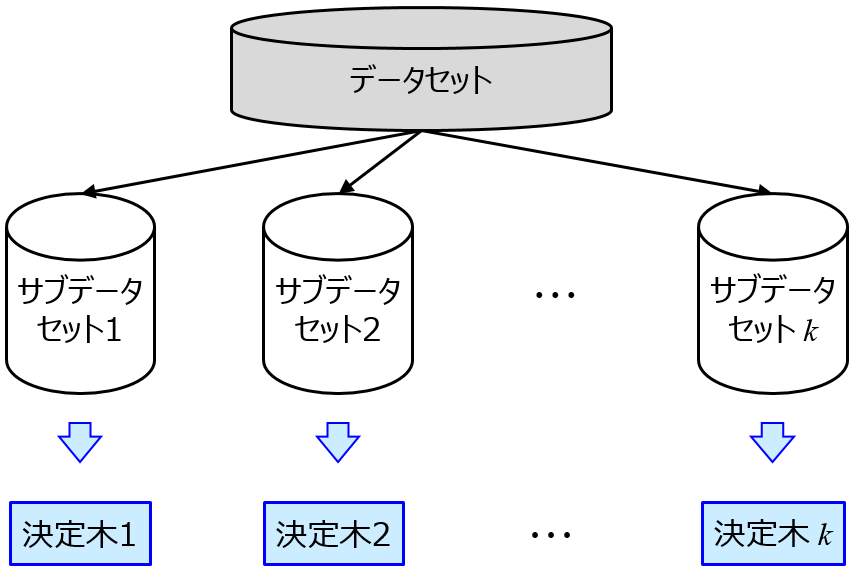
クラス分類モデルの適用範囲をアンサンブル学習で設定するとき、
□ モデルの適用範囲が広くなってしまう問題を認識していて、データ密度などのモデルの適用範囲を設定する別の方法も用いてモデルの適用範囲を設定している
化学構造を用いたモデルの逆解析のとき、
□ (標準偏差が 0 の記述子などの) 記述子を削除する前に設定したモデルの適用範囲 (universal AD) を用いている
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

