分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y = f(x) を構築し、構築したモデルに x の値を入力して y の値を予測したり、y が目標値となる x の値を設計したりします。
回帰分析やクラス分類を行う時に、データセット、特に x の中に欠損値があることがあります。いわゆる「穴あきのデータセット」です。実験条件の一部が記載されていなかったり、分析・測定されていなかったりするサンプルがある状況や外れ値を検出した後の状況です。欠損値を含むデータセットのイメージは以下になります。
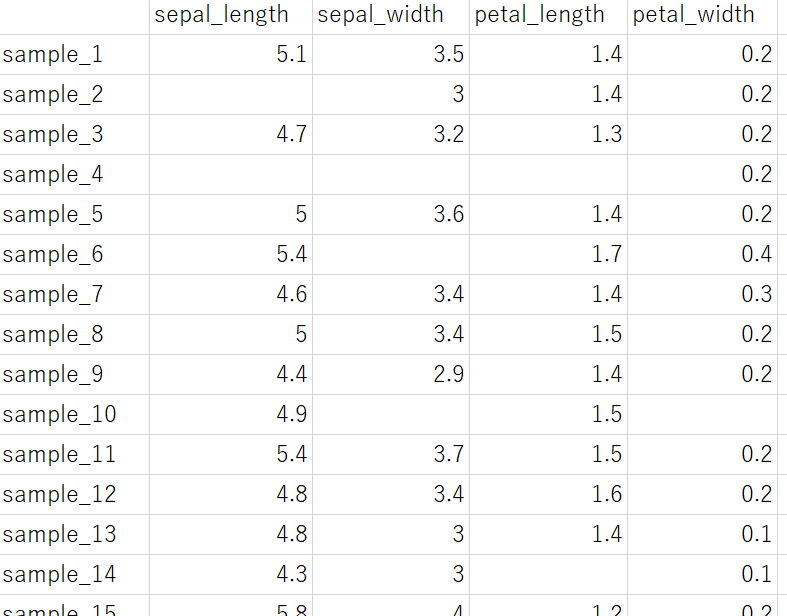
このようなデータセットを用いて回帰分析やクラス分類をする時、前処理の方法として以下の選択肢があります。
- 欠損値を含むサンプルを削除する
- 欠損値を含む x を削除する
- 欠損値を補完する
ちなみに、欠損値の補完は iGMR が良いでしょう。

上の3つの選択肢のどれが良いかは、データセットによって異なります。そのため、データセットごとに3つとも比較検討して、最良のものを選択する必要があります。それぞれ、トレーニングデータ・テストデータの分割やダブルクロスバリデーションによって、回帰モデルやクラス分類モデルの予測性能を評価し、最良のものを選択します。
注意点としては、欠損値を含むサンプルを削除すると、欠損値を含む x を削除した場合や欠損値を補完した場合と比較して、サンプルの内容が変わってしまいます。そのため、トレーニングデータとテストデータに分割する際には、テストデータは欠損値を含まないサンプルにして、3つ全てでサンプルを揃えます。またダブルクロスバリデーションする際には、評価に用いるサンプルを欠損値を含まないサンプルのみにする(例えば、欠損値を含む x を削除して回帰分析でダブルクロスバリデーションを行った時、r2 の計算は欠損値を含むサンプルを削除した場合のサンプルと合わせる)必要があります。
上記の3通りそれぞれのモデルの予測性能を比較して、最適な方法で欠損値の処理を行いましょう。
以上です。
質問やコメントなどありましたら、X, facebook, メールなどでご連絡いただけるとうれしいです。