応化先生と生田さんが論文 “Automatic outlier sample detection based on regression analysis and repeated ensemble learning” について話しています。
応化:今日は外れサンプル検出についてです。
生田:外れ値検出ではなくて、外れサンプル検出?
応化:はい、そうです。データ分布から外れた “値” を検出するのではなく、他のサンプルとは大きく異なる “サンプル” を検出する内容です。
生田:わかりました。
応化:外れ値検出や外れサンプル検出の基礎についてはこちらをご覧ください。
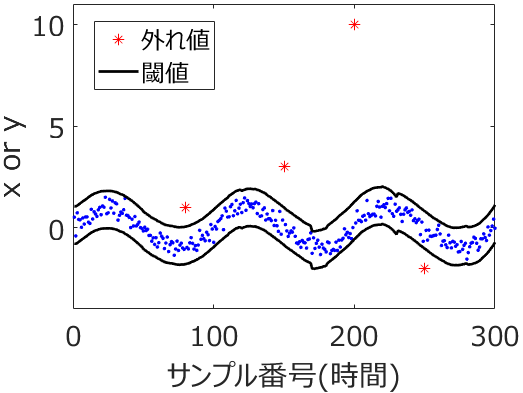
生田:たとえば、One-Class Support Vector Machine (OCSVM) でも外れサンプルを検出できそうです。今回の手法はそれとどう違うのですか?
応化:まず前提として、回帰分析をするときの外れサンプル検出です。OCSVMでは説明変数Xにおける外れサンプルを検出する手法ですが、今回のはXと目的変数yがあるときに、Xとyの間の関係が他のサンプルと異なるサンプルを検出する手法です。
生田:へー。普通にXとyの間で回帰分析して、誤差の小さいサンプルを検出するのだとダメなのですか?
応化:そうですね、その方法ですと、適切に外れサンプルを検出することはできません。回帰分析では誤差を小さくするようにモデリングが行われるため、モデルがトレーニングデータにオーバーフィット (過学習) してしまい、外れサンプルが検出できないのです。これは論文中でも確認されています。
生田:なるほど。今回の手法ではどうやってその問題点を克服したのですか?
応化:アンサンブル学習を活用しました。
生田:たくさんモデル作るやつ?
応化:そうです。たくさんモデルを作るので、一つのサンプルあたり、たくさんのyの推定値が得られます。なので、yの平均値と標準偏差が計算できます。正規分布をつくれるのです。yの実測値がその正規分布から外れたとき、外れサンプルとみなします。
生田:なんとなくわかりました。データセットがあって、Xとyがあったら外れサンプルを検出できるんですよね。
応化:そういうことです。
生田:詳しいことはどこに書いてありますか?
応化:ぜひ論文を読んでください。金子研のオンラインサロンに入れば論文をお渡しします。質問も自由です。また、DCEKit でこの手法を実行できます。

以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。