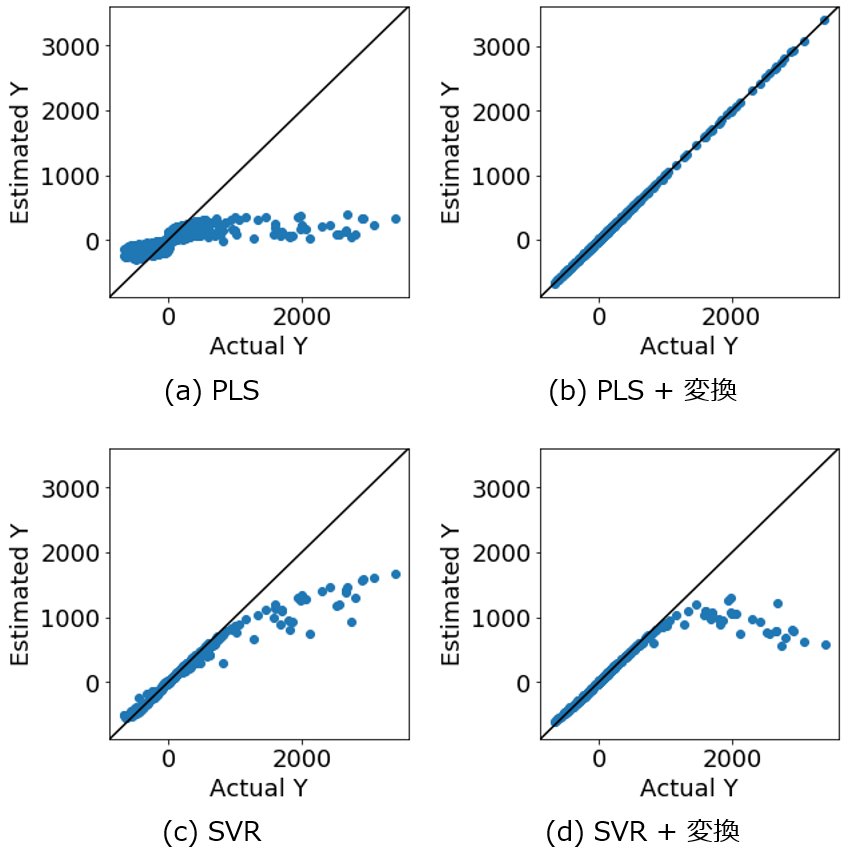
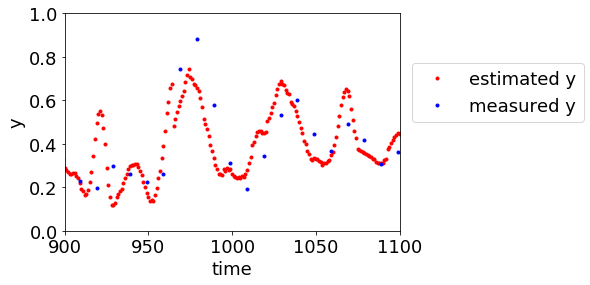
回帰モデルやクラス分類モデルが得られたあとの話です。
よくやるのは、説明変数 (記述子・特徴量・パラメータ・入力変数) X の値を回帰モデルやクラス分類モデルに入力して、目的変数 Y の値を推定することです。これをモデルの順解析とよびます。
その逆の解析のことを、モデルの逆解析とよびます。つまり、Y の値を回帰モデルやクラス分類モデルに入力して、X の値を推定することです。目標としている物性や活性などを達成するための、説明変数・記述子・特徴量・パラメータ・入力変数の値を求めるために使われます。
今回は、そのモデルの逆解析について説明するスライドを作りました。pdfもスライドも自由にご利用ください。
pdfファイルはこちらから、パワーポイント(pptx)ファイルはこちらからダウンロードできます。
興味のある方はぜひ参考にしていただき、どこかで使いたい方は遠慮なくご利用ください。
モデルの逆解析とは?
- Y (物性・活性など) の値を回帰モデルやクラス分類モデルに入力して、X (記述子・特徴量・パラメータ・入力変数) の値を推定すること
- 大きく分けて2つの方法がある
- 順解析を繰り返す
- ベイズの定理を利用する
スライドのタイトル
- モデルの逆解析とは?
- 順解析と逆解析
- モデルの逆解析のやり方
- 全通りの X の候補を用いる (グリッドサーチ)
- ランダムに X の値を生成する
- 最適化手法を用いる
- ベイズの定理を利用する
- ベイズの定理を利用した逆解析
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。