分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y = f(x) を構築し、構築したモデルに x の値を入力して y の値を予測したり、y が目標値となる x の値を設計したりします。
サンプルの特徴量として x の形で表現されていれば問題ありませんが、データセットによっては、(統一的に) x の形で表現するのが困難で、サンプル間の類似度の形の方が表現しやすい状況もあります。例えば、バッチ時間の異なるバッチプロセスの時系列データを含むデータセットでは、単純に時間を x にするとサンプルごとに x の数 (時間の長さ) が揃わないため、統一的に x とするには工夫が必要です。例えば、フーリエ変換や補間をする方法があります。

一方で、例えば Dynamic Time Warping (DTW) によって時系列データ間、すなわちサンプル間の類似度を計算できます。

分子構造のデータでも、例えばフィンガープリントを計算した後のタニモト係数などの類似度を用いる状況もあります。文字列のデータでも、文字列間の類似度で表現する場合があります。
そのような場合には、カーネル関数に基づく手法や多次元尺度構成法が向いています。カーネル関数は、サンプル間の類似度と考えると理解しやすいです。

一般的には x からカーネル関数に基づいてサンプル間でカーネル行列を計算し、それを例えばサポートベクターマシンやガウス過程回帰の入力として使用します。
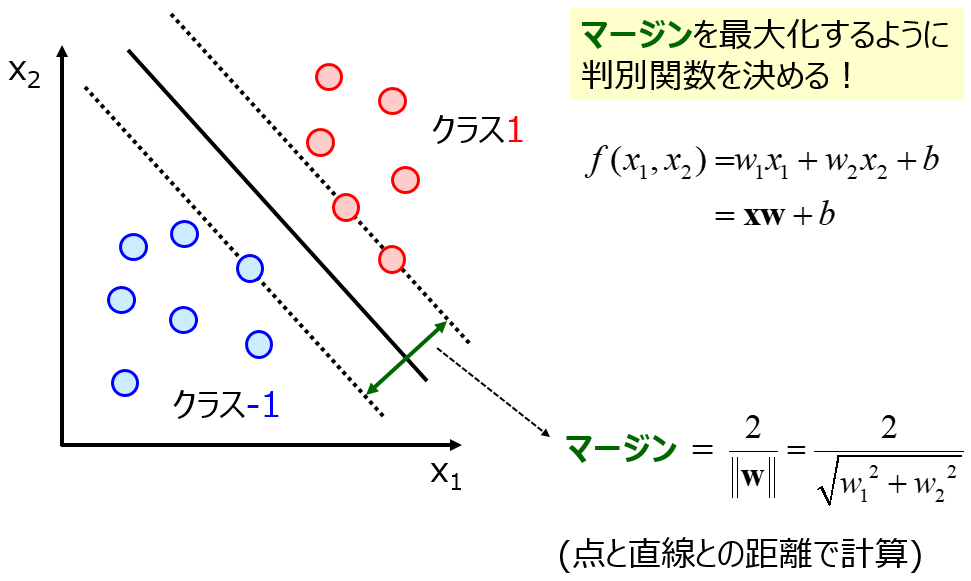


このカーネル行列を、サンプル間で計算した類似度の行列で置き換えます。これにより x にする必要はなく、類似度行列すなわちカーネル行列だけでモデル構築が可能になります。
サンプル間の類似度行列のみから、x を計算したい場合には、多次元尺度構成法 (Multi-Dimensional Scaling, MDS) があります。主成分分析では、x の分散共分散行列を固有値分解することで主成分を計算していますが、
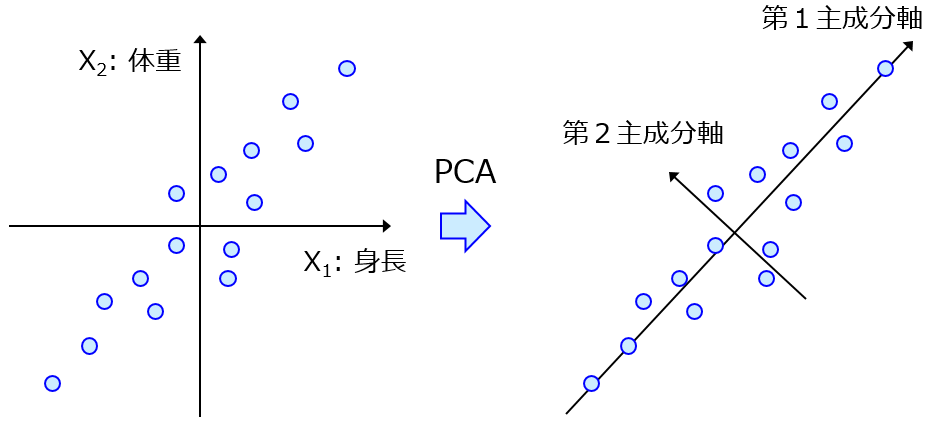
MDS では、共分散を類似度として捉えて、主成分分析における分散共分散行列を類似度行列に置き換え、類似度行列を固有値分解して “主成分”、すなわち x の形で表現します。MDS により、類似度行列のみから、基本的にサンプル数までの特徴量の数を持つ x を計算できます。
サンプルを x で表現しにくい一方で、サンプル間の類似度なら計算できる場合には、カーネル関数に基づく手法や MDS による類似度行列から x の計算によって解析を進めると良いでしょう。
以上です。
質問やコメントなどありましたら、X, facebook, メールなどでご連絡いただけるとうれしいです。

