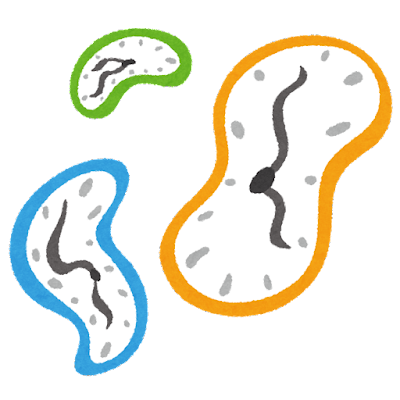
分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y = f(x) を構築し、構築したモデルに x の値を入力して y の値を予測したり、y が目標値となる x の値を設計したりします。
特に化学・産業プラントにおけるソフトセンサーでは、x が容易に測定可能なプロセス変数、y が測定困難なプロセス変数であり、ソフトセンサー y = f(x) を用いることで、測定困難なプロセス変数でもオンラインでリアルタイムに推定できます。y の実測値の代わりに推定値を用いることで、迅速な制御が達成されます。

化学・産業プラントのデータは分子や材料のデータとは異なり、時系列データであったり、x と y のデータ数が大きく異なることがあったりと、特徴があります。そのような特徴を考慮することで、より予測精度の高いモデル構築や信頼性のある予測ができるようになります。このあたりを説明します。
特徴として、時系列データであることを踏まえた上でのポイントは以下をご覧ください。
もう一つの大きな特徴として、y のデータに比べて x のデータが非常に多いことが挙げられます。例えば、x が毎分 (1分に1回) 測定されていて、y が3時間 (180分) に1回測定されていると、x のデータ数は y のデータ数の180倍になります。基本的には x と y の揃ったデータを使用しますので、サンプル数を単純に計算すると、x のデータ数の 180分の1 (1/180) になります。残りの 180分の179 (179/180) は無駄になってしまいます。
これらのデータを無駄にせず、有効に活用することで、モデルの予測精度が向上することがあります。ポイントは 4 つです。
1. x の時間遅れ変数として使用する
上の URL 先にある、時系列データの特徴を踏まえた上でのポイントにもある通り、y に対する x の時間差を考慮することでモデルの予測精度が向上することがあります。ある時刻のプロセス変数だけでなく、1 分前、2分前、3分前、、、のプロセス変数を x として用いることで、y と時刻の揃ったデータだけでなく その付近の時刻に測定された (毎分の) x のデータを有効に活用します。
2. スムージング (平滑化) をする
時系列データは、プロセス変数ごとに時間的に前後の値は似ています。データの特徴としては、波長もしくは波数の前後の値が似ているスペクトルデータと同じであり、その特徴を考慮してスムージング (平滑化) をすることでノイズを低減できます。

x のデータとして、y が測定された時刻のデータだけを使うのではなく、すべてのデータ (毎分測定されたデータ) を使うことで、より連続的なデータになるため、適切にスムージングできます。
3. 半教師あり学習に使う
半教師あり学習にもいろいろな手法がありますが、例えば y が測定された時刻のデータだけではなく、すべてのデータ (毎分測定されたデータ、180倍) を用いて、主成分分析を行ったり Autoencoder のモデルを構築したりして、x から潜在変数 z を計算します。この z を x として用いることで、180 倍もの大量のデータで特徴量抽出ができます。また、y と揃ったデータのみを使う場合と比較して、頑健に低次元化できます。
4. プロセス状態の推定モデルを構築する
データが測定されるプロセスの状態は、時々刻々と変化します。モデルを用いて y を推定しているプロセスの状態が、モデルを構築したデータが測定された時間帯のプロセス状態と同じであれば、y の予測値は実測値と合うと考えられます。ただ、これまでにない新たなプロセス状態に遷移 (トランジション) したときは、予測結果は合わない可能性があります。このようなプロセス状態の変化を事前に検知できれば、新たなプロセス状態の時間帯におけるモデルの y の予測値は信用しない、といった判断ができます。
モデルの適用範囲や異常検出モデルと同様の考え方を用いて、

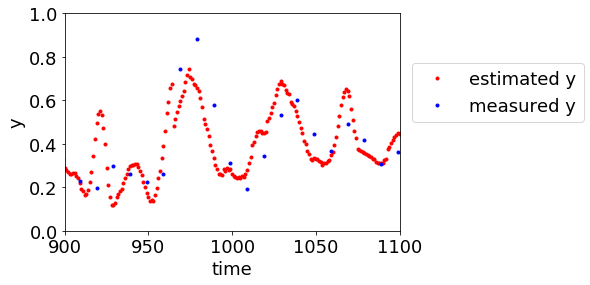
プロセス状態を推定するモデルを構築しておくことで、y の予測値の信頼性を考慮した上でソフトセンサーを運用できます。例えば、毎分の y の予測値に対して、エラーバーのように予測値がばらつきうる範囲を一緒に出力することが可能になります。新たなプロセス状態に推移するときにエラーバーが大きくなるイメージです。これにより適切にソフトセンサーの管理ができます。
以上のように、ソフトセンサーを構築するときは基本的に x と y の揃ったデータのみを用いますが、そのデータだけでなく x しか測定されていないデータも活用することで、モデルの予測精度や信頼性の向上のための様々な検討が可能です。ぜひ上のポイントを参考にしていただければと思います。
以上です。
質問やコメントなどありましたら、X, facebook, メールなどでご連絡いただけるとうれしいです。