
回帰分析やクラス分類でモデルを作ったあと、多くの場合において、そのモデルを逆解析します。モデルの逆解析についてはこちらをご覧ください。

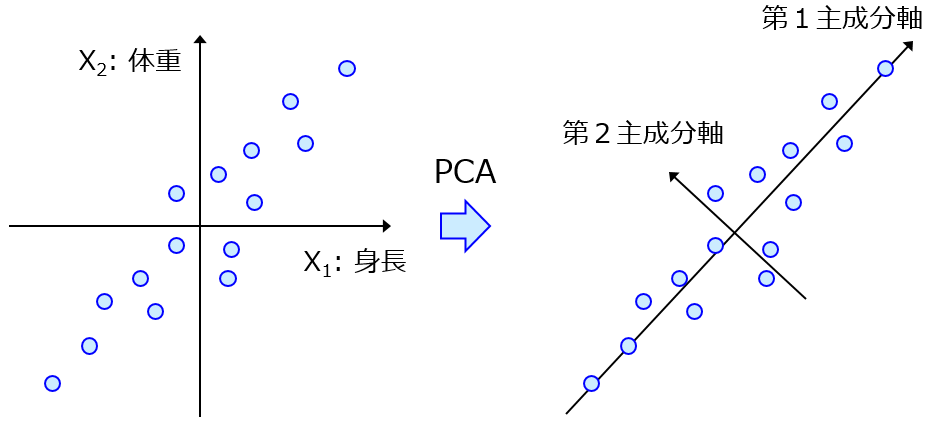
回帰モデルを構築するとき、部分的最小二乗回帰 (Partial Least Squares Regression, PLS) を用いる人もいるはずです。今回は PLS モデルの逆解析をすることのメリットについてです。
それは、
モデルの適用範囲 (Applicability Domain, AD) を考慮しやすい
ことです。AD についてはこちらをご覧ください。

一言でいうと AD とは、モデルが本来のパフォーマンスを発揮できる、説明変数 (記述子・特徴量など) X の領域のことです。AD 内であれば、その目的変数 y の推定値は ある程度信頼できるわけです。
モデルの逆解析においても AD は大切です。必ず AD を設定しなければなりません。なぜなら、目標の y の値を実現する X の値を、モデルの逆解析により計算できても、その X の値で本当に目標の y の値を実現できるか、誰もわからないためです。結果をどれくらい信用してよいのか、確認する必要があります。また、一般的に y の変数の数は X の変数の数より少ないため、ある y の値となる X の値の組み合わせは複数個得られます。その中で、どの X の値であれば信頼できるのか検討しなければなりません。
もちろん、回帰モデルを構築し、また別に AD を設定することで、十分に対応できます。ただ、PLS で回帰モデルを構築すると、AD を設定しやすく、また PLS モデルにとってより適切な AD を設定できるようになります。
PLS では、X と y との間で最小二乗法により回帰モデルを構築するわけではなく、X を主成分 T に変換してから、T と y との間において最小二乗法により回帰モデルを構築します。X を低次元化してから、回帰モデルを構築するわけです。
T の成分の数は X の変数の数より小さく、さらに T の間は無相関 (相関係数が0) です。これらの特徴によって、より適切な AD を設定できるようになります。
PLS モデルの AD は、X ではなく T で設定しましょう。変数の数が多くなればなるほど、次元の呪いによってサンプル間の距離を比較できなくなってしまいます。X より T のほうが次元の呪いの影響を受けにくいのです。また、T の成分の間は無相関なので、ユークリッド距離を用いたとしても、マハラノビス距離のように相関関係を考慮した距離のようになります。
新しいサンプルにおける AD の指標を計算するときには、PLS モデルのローディング P を用いることで T に変換できますので、その値を用いて計算します。
PLS モデルの逆解析を行うときには、ぜひ PLS の主成分 T でAD を設定しましょう!
ちなみに、これはデータの前処理として主成分分析 (Principal Component Analysis, PCA) や Generative Topographic Mapping (GTM) などの低次元化手法を組み合わせた回帰分析を行うときでも有効です。PCA や GTM についてはこちら。
ぜひ活用しましょう!
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

