
分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y = f(x) を構築し、構築したモデルに x の値を入力して y の値を予測したり、y が目標値となる x の値を設計したりします。
クラス分類において、クラスごとのサンプル数に偏りがあるとき、サンプルの多いクラスをアンダーサンプリングしたり、サンプルの少ないクラスをオーバーサンプリングしたりして、不均衡を解消してからモデリングすることがあります。ちなみに、オーバーサンプリングは “偽” のサンプルを追加することになりますので、そのようなデータを用いる妥当な理由がない限りは、控えた方がよいでしょう。
回帰分析においては、不均衡データを解消しても効果がないことはこちらで述べた通りです。

ただし、こちらのように
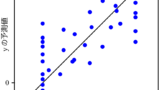
0 や 1 (もしくは 100) のサンプルについては、うまく対処すると予測精度が向上することがあります。
クラス分類においてアンダーサンプリングで不均衡データを解消しようとしたり、回帰分析において 0 や 1 のサンプルを削除したりすることがありますが、このとき注意するのは、モデルの適用範囲 (Applicability Domain, AD) です。

サンプルを削除することにより予測精度が向上しても、同時に AD は狭くなります。しっかりと AD を設定して、狭くなった AD を認識しておくことが重要です。
クラス分類のとき、アンダーサンプリングをしてモデル構築することを繰り返すことでアンサンブル学習をすることもあります。AD を設定することを考えたとき、アンサンプル学習だけでは AD は広く取られてしまいますので、

例えばデータ密度に基づく AD と組み合わせることが重要です。
アンダーサンプリングをはじめとして、サンプルを削除した後も適切に AD を設定するようにしましょう。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

