共同研究やコンサルティングなどで、いろいろな方々とお話していると、データ解析・機械学習に関連した誤解があることに気づきます。確かに、一見妥当そうな内容ですので、誤解するのは仕方ないと思いますし、実際、中にはわたしも昔に同じことを考えており、実際にやってみたりよく考えたりして、「誤解だった」と気付いた経緯があるものも存在します。
今回はそのような 「よくある誤解」 について、いくつか取り上げてまとめます。
- 回帰分析においてサンプルのバランスを整えることで、モデルの予測精度が上がる
- ハイパーパラメータの最適化をするとき、クロスバリデーションにおける誤差をひたすら下げればよい
- サンプル数を増やすとモデルの予測精度が上がる
- 数値で表されていれば、どんな変数でも説明変数 X にすることができる
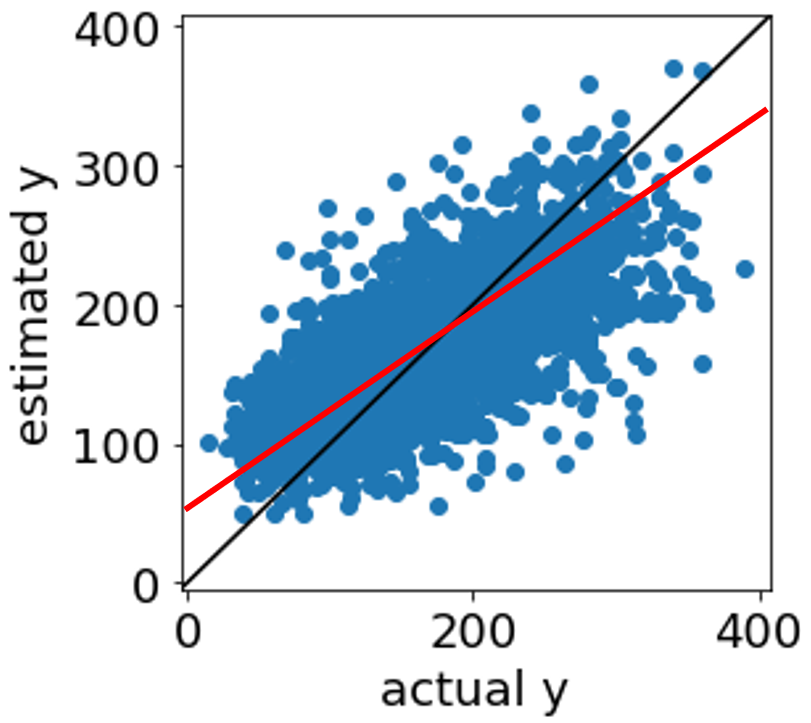
よくある誤解1「回帰分析においてサンプルのバランスを整えることで、モデルの予測精度が上がる」 → 基本的にそのようなことは起こりません!
回帰分析を行うときに、目的変数 Y の値ごとのサンプル数のバランスが悪い場合があります。たとえば、Y の値が平均値くらいのサンプルが非常に多く、Y の値が大きいサンプルや値が小さいサンプルが少ない場合です。このとき、平均値付近のたくさんのサンプルにおける Y の誤差を小さくするばかりで、Y の値の大きいサンプルの誤差や、Y の値の小さいサンプルの誤差を小さくすることが疎かになってしまっている、と考えた方もいらっしゃるのではないでしょうか?そして、平均値付近で同じような Y の値をもつサンプルを減らし、Y の値の大きいサンプルの数や Y の値が小さいサンプルの数と同じくらいの数にすることで、サンプル数のバランスを整い、Y の値が大きいサンプルの誤差やY の値が小さいサンプルの誤差が小さくなると期待するかもしれません。しかし実際は、基本的にそうなるわけではありません。たとえばニューラルネットワークの学習率・学習回数が小さく、十分に学習されていないサンプルがある場合は別ですが (その場合でも学習回数を大きくすればよいですね)、基本的にそのような、サンプルバランスを整えることで予測精度が上がることはありません。回帰分析では、Y の値の大小やサンプルの数にかかわらず全体の誤差が小さくなるように学習が行われます。バランスを整えるために削除したサンプルが外れサンプルのような場合は予測精度が上がるかもしれませんが、サンプルのバランスを整えるよりも、Y の値の大きいサンプルや Y の値の小さいサンプルを X でどのように説明するか考えるとよいです。
よくある誤解2「ハイパーパラメータの最適化をするとき、クロスバリデーションにおける誤差をひたすら下げればよい」 → クロスバリデーションの結果にオーバーフィットしてしまうため、やめたほうがよいです!
ハイパーパラメータを最適化するとき、よくクロスバリデーションが用いられます。クロスバリデーションをした後、回帰分析であれば決定係数 r2 が最大となるハイパーパラメータの候補を選択しますし、クラス分類であれば正解率が最大のハイパーパラメータの候補を選びます。サポートベクター回帰における C, ε, γ のように

ハイパーパラメータが連続的な値のとき、最適化しようと思えば、いくらでも細かく最適化できます。たとえば、遺伝的アルゴリズムにおける染色体をハイパーパラメータでコーディングし、目的関数をクロスバリデーションの後の r2 や正解率として、それが最大となるようなハイパーパラメータの値を探索することもできます。しかし、(クロスバリデーションにおける予測精度) = (外部データに対する予測性能) ではありません。クロスバリデーションにおける予測精度は、あくまでもトレーニングデータに対しての予測性能であるため、ハイパーパラメータがクロスバリデーションの結果にオーバーフィッティングしてしまう危険があります。そうなると、たとえばテストデータに対する予測精度が低くなります。クロスバリデーションの結果にそこまでこだわることなく、ざっくりとクロスバリデーションでハイパーパラメータを決めるくらいの感覚でいた方がよいです。
よくある誤解3「サンプル数を増やすとモデルの予測精度が上がる」 → サンプル数ではなく、サンプルの多様性が大事です!
もちろん、予測精度の高い回帰モデルやクラス分類モデルを構築するとき、サンプル数は重要です。しかし、ただサンプルを増やしたからといって、モデルの予測精度が上がるわけではありませんので、注意しましょう。同じサンプルをいくら追加したとしても、構築されたモデルは変わりません。大事なのはサンプルの多様性でり、サンプルを増やしたことでデータセットの情報量が向上するかどうかです。モデルの適用範囲が広がることを意識して、サンプルを収集するとよいでしょう。
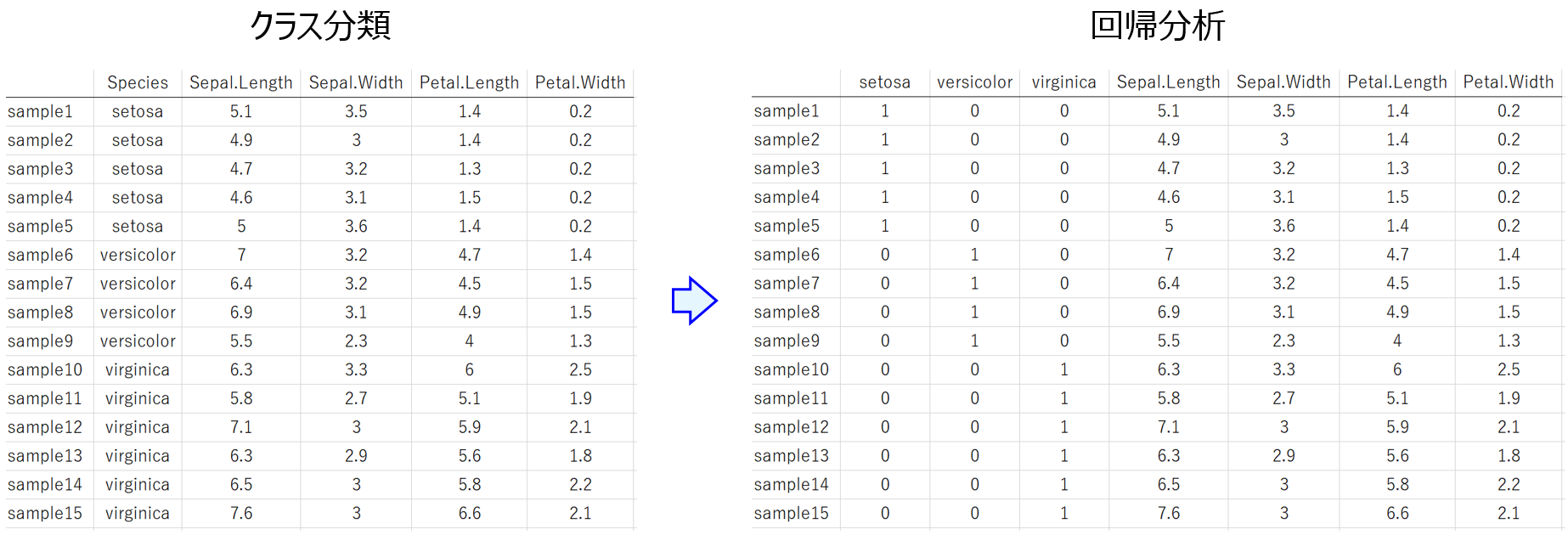
よくある誤解4「数値で表されていれば、どんな変数でも説明変数 X にすることができる」 → 間隔尺度もしくは比例尺度である必要があります!
間隔尺度や比例尺度をはじめとした尺度については、こちらをご覧ください。

データ解析に用いる場合は、間隔尺度や比例尺度にしましょう。そうでない場合は、こちらのように変換しましょう。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。