分子設計や材料設計をするときや、プラントにおいてソフトセンサーを検討しようとするとき、
(分子設計・材料設計・ソフトセンサーについてはこちら)
それぞれ、何らかの数値モデルを構築することになります。データ解析・機械学習を駆使してモデルを構築するとき、データが必要となるため、データベースを作成することになります。モデル構築用のサンプルを集めるわけですね。サンプルを集めるときに意識するとよいことについて説明します。
データベースを作るときの基本的なスタンスは、なるべく多くのデータを集める、です。サンプルも、特徴量も、数多く集めるということです。エクセルのシートでいえば、縦の行も、横の列も多いほうがよいですね。サンプルが多いことがよいのはもちろんのこと、特徴量も多い方がよいのです。
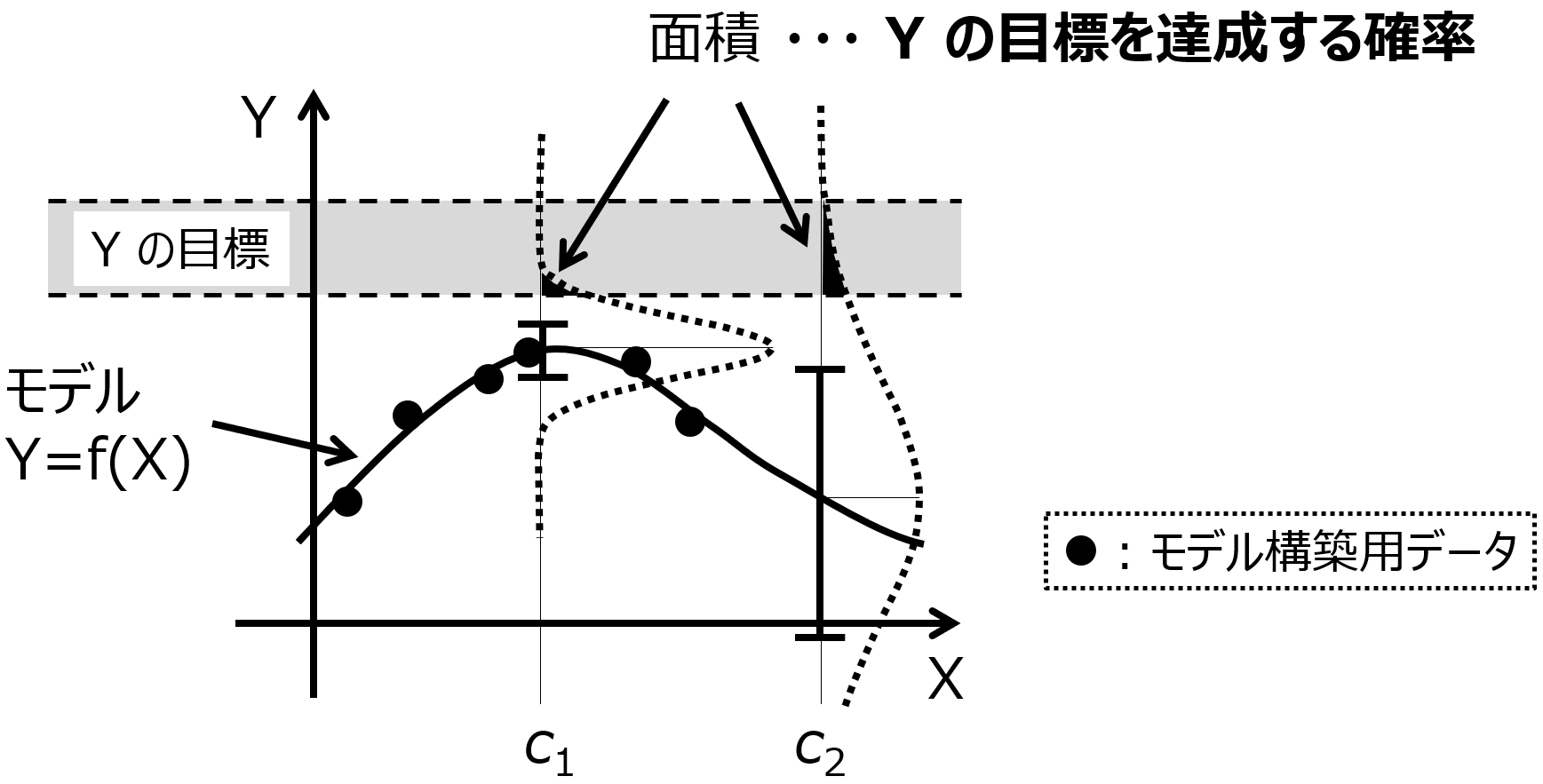
たとえば、材料設計でしたら製品品質としての活性・物性・特性 Y と、実験レシピ、つまり実験条件や製造条件 X との間で数値モデル Y=f(X) を構築することになります。また、ソフトセンサーでしたら測定が困難なプロセス変数 Y と簡単に測定可能なプロセス変数 X との間で数値モデル Y=f(X) を構築します。このモデルを構築するとき、サンプルが多い方が、モデルの適用範囲の広いモデルを構築できます。

より広い X の範囲で安定的に Y の値を予測できるわけですね。いろいろなサンプルにおいて Y の推定値を信頼できてうれしいです。そのため、データ収集をするとき、なるべく多くのサンプルがあったほうがよいです。まったく同じ目的、実験系でなく、すこし毛色の違ったサンプルがあるときには、それらも集めておけば、たとえば転移学習を検討することも可能です。

背景が似ているようであれば、そのようなサンプルも集めておくとよいと思います。
モデル Y=f(X) は、X で Y を説明する必要がありますので、Y を説明するための情報量が X に含まれていないと、そもそもモデルを構築できません。そのため、X の特徴量も多いほうがよいです。もちろん、Y と関係のない特徴量が X にあると、モデルを作るときにはノイズになりますので、Y とぜったい関係ないことがわかっていれば、そのような特徴量は省いたほうがよいです。ただ、ノイズになることを恐れて特徴量を最初から減らすことで、モデルを構築するための情報が失われる可能性があるよりは、ノイズになるかもしれませんが、必要な情報になる可能性があるということで、まずは多くの特徴量を準備しておいた方がよいです。
もちろん、最初のサンプルが少ないほど、特徴量は減らした方がよいのですが、Boruta のように Y と関係のない特徴量を削除してくれる手法もあります。

また特徴量が多いときには、特徴量が多いときとそれから減らしたときとの両方でモデルの検証ができます。yランダマイゼーションのような偶然の相関も検証できます。


このような状況ですので、大事な特徴量はもちろんのこと、もしかしたら不要と考えられるような特徴量に関しても、とりあえず集めておいた方がよいと思います。
データベースに基づいて統計的にモデルを構築するということは、理論や人の頭の中では説明できないような現象がある、ということですので、そのような一見不要と考えられる特徴量の中にも、実際は Y に効いているものが見つかるかもしれません。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。