
分子設計、材料設計、プロセス設計、プロセス管理・制御において、データセットを用いて解析したり、機械学習したりします。データセットの可視化をしたり、クラスタリングをしたり、クラス分類をしたり、回帰分析をしたり、予測をしたり、予測結果に基づいて設計したり、といった感じです。少し複雑なデータ解析や機械学習をしようとすると、自分でプログラムを作ってそれを実行することで解析した方が効率的です。ちなみに、わたしをはじめとして金子研の人たちは、主に Python でプログラムを作成しています。
自分でプログラムを作って、そのプログラムを実行しようとすると、エラーになって実行できないときがあると思います。プログラミング言語の文法的には正しくても、エラーが起こることもあります。そのようなエラーが起きたとき、エラーメッセージを読んでも原因がわからない場合、まずは解析しているデータセットの中身を、直接自分の目で見て確認するとよいです。感覚的な経験では、9 割以上が、データセットが原因で起こるエラーです。
Jupyter notebook では、セルに確認したい変数の名前を打ち込んで実行すれば、確認できます
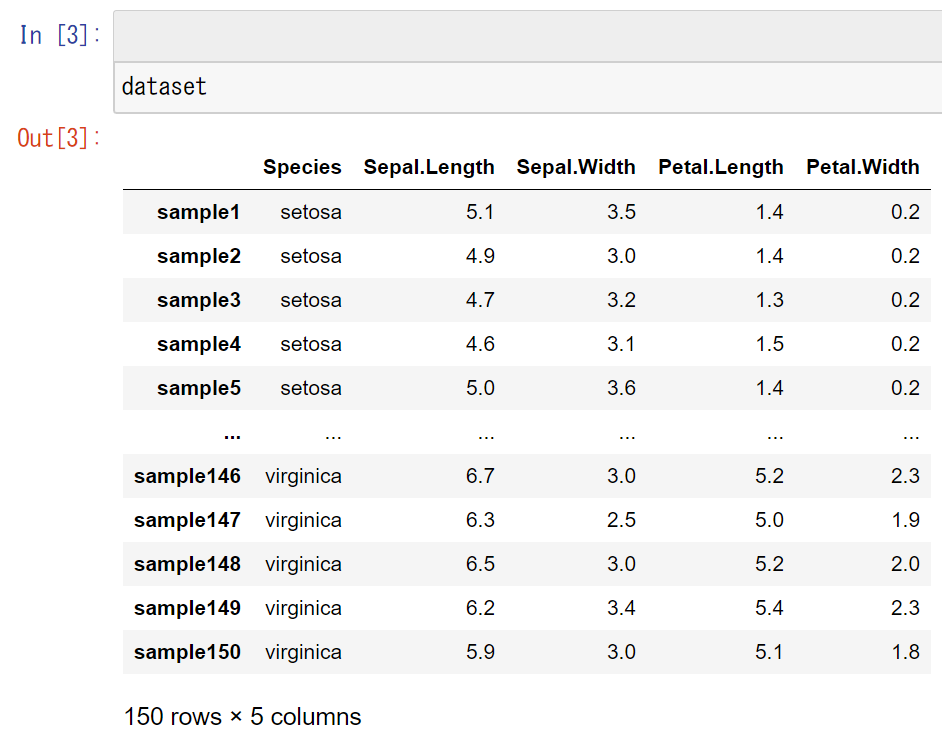
DataFrame の変数であれば、「変数名.head()」 を実行して、最初の 5 サンプルだけを確認できます。

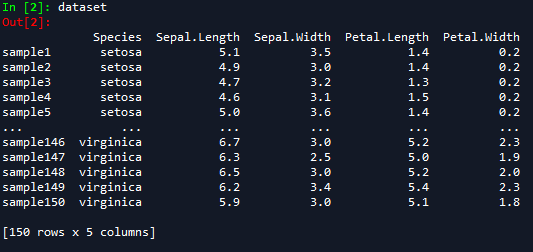
Spyder を使用している場合は IPython コンソールに変数名を打ち込んで実行したり、
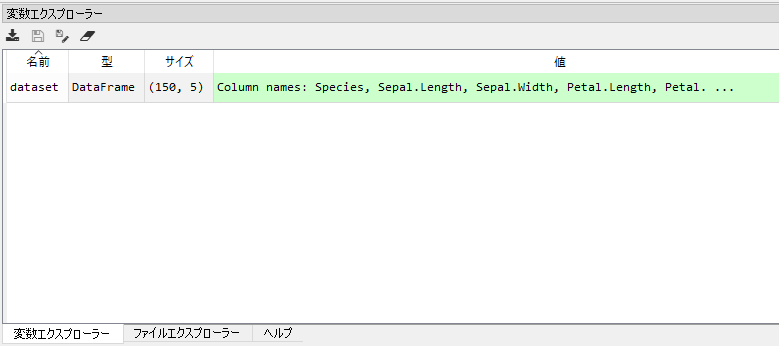
変数エクスプローラーで対象の変数名をダブルクリックして、内容を確認したりするとよいと思います。
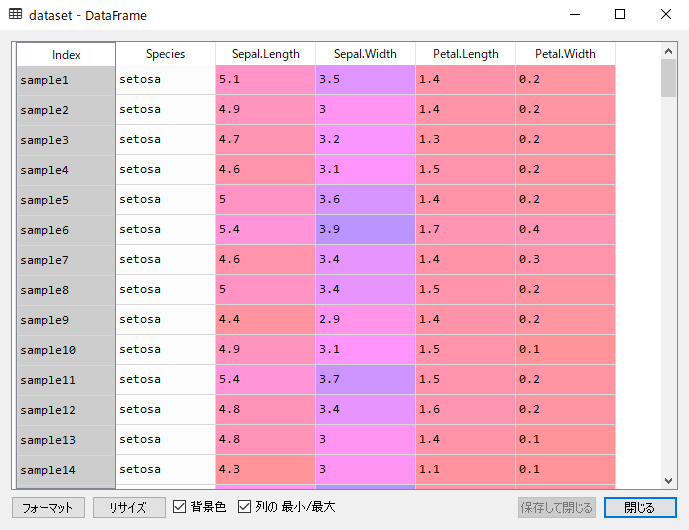
データセットの内容を見ると、エラーが起きた原因が分かると思います。たとえば、どこかに NaN が入っていたり、数値だけと思っていた特徴量に文字列が入っていたり、非常に大きい (もしくは負の方向に非常に大きい) 値があったり、ある特徴量で値がすべて同じであったり、といったことです。
サンプルの数が非常に大きかったり、特徴量の数が非常に大きかったりすると、特徴量ごとの平均値を計算して確認すると、すべてのサンプルを見るより確認しやすいかもしれません。とにかく、エラーの起きた要因がデータセットに関係していることが多いですので、まずはデータセットを自分の目で確認するのがよいと思います。
ご自身でプログラムを作成してデータ解析・機械学習をする方々にとっては、データセットの内容を確認することは当たり前のことと思います。ただ、入門者・初学者にとって、エラーの原因がわからず解決できないままデータ解析・機械学習を諦めてしまう方もいらっしゃると思い、今回の記事としました。参考になれば幸いです。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

