分子設計でも材料設計でもプロセス設計でも、説明変数 X と目的変数 Y のそろったデータセットを準備して、X と Y の間でモデル Y = f(X) を構築します。構築したモデルを用いて、Y が目標の値となるような X の候補を設計します。多くの場合では、X のサンプル候補をたくさん (100 万個など) 生成して、それらをモデルに入力して Y の値を予測します。ベイズ最適化 (Bayesian Optimization, BO) では、獲得関数の値を計算します。
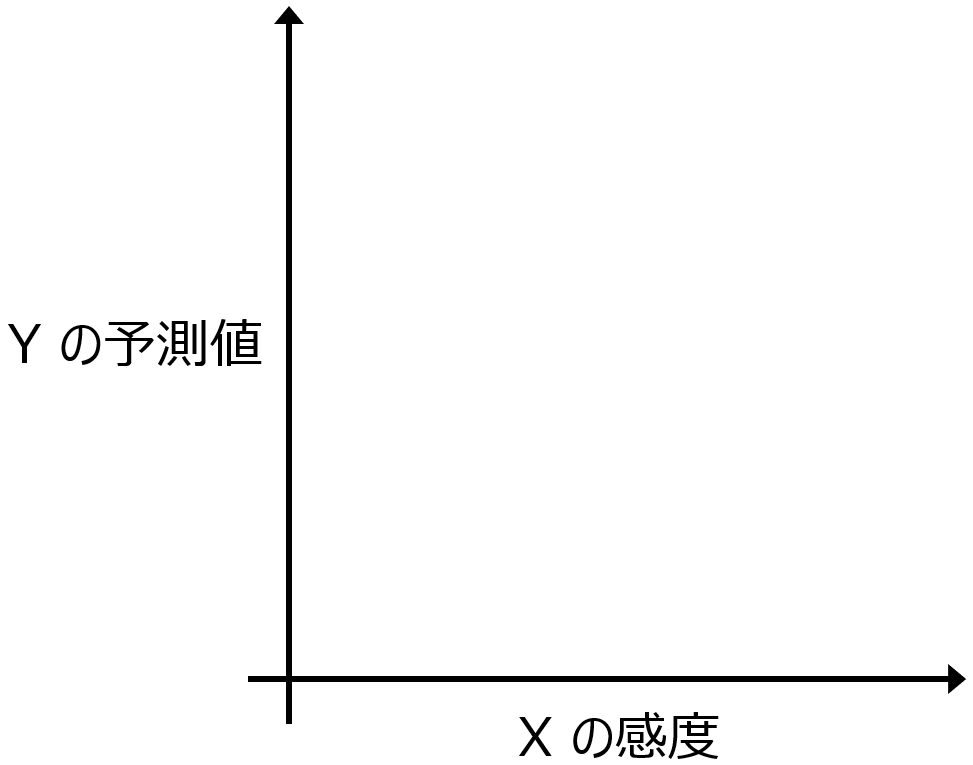
予測値や獲得関数の値が望ましい値となるような、X の候補を選択して、それで実験します。
モデルを利用するときには、モデルの適用範囲 (Applicability Domain, AD) が重要という話をしました。

モデルには本来の予測性能を発揮できるデータ領域があり、それを AD としてあらかじめ設定します。X のサンプルが AD 内であれば、その Y の予測値は信頼でき、AD 外であれば、その予測値は信頼できない、というわけです。
AD の設定方法はいろいろあります。トレーニングデータの中心からの距離とか、データ密度とか、予測値の標準偏差を計算する方法とかです。トレーニングデータの中心からの距離が ある値以下を AD 内と設定したり、データ密度の値が ある値以上を AD 内としたり、予測値±標準偏差内 (予測値±2×標準偏差や予測値±3×標準偏差とかも) を実際の値の範囲と設定したりです。
AD を設定することは、モデルの守備範囲を決めることです。守りを固めることで、AD の範囲内であればモデルが機能することがわかりますので、その範囲内で分子設計・材料設計・プロセス設計をしたり、ソフトセンサーだったら予測値を信頼したりします。
一方で、守っているだけでは、らちが明かない場合もあると思います。材料の目標値がとても高いところにあり、AD 内では目ぼしい設計ができないこともあるでしょう。
攻めに転じる必要があります。ここで活用できるのが BO です。
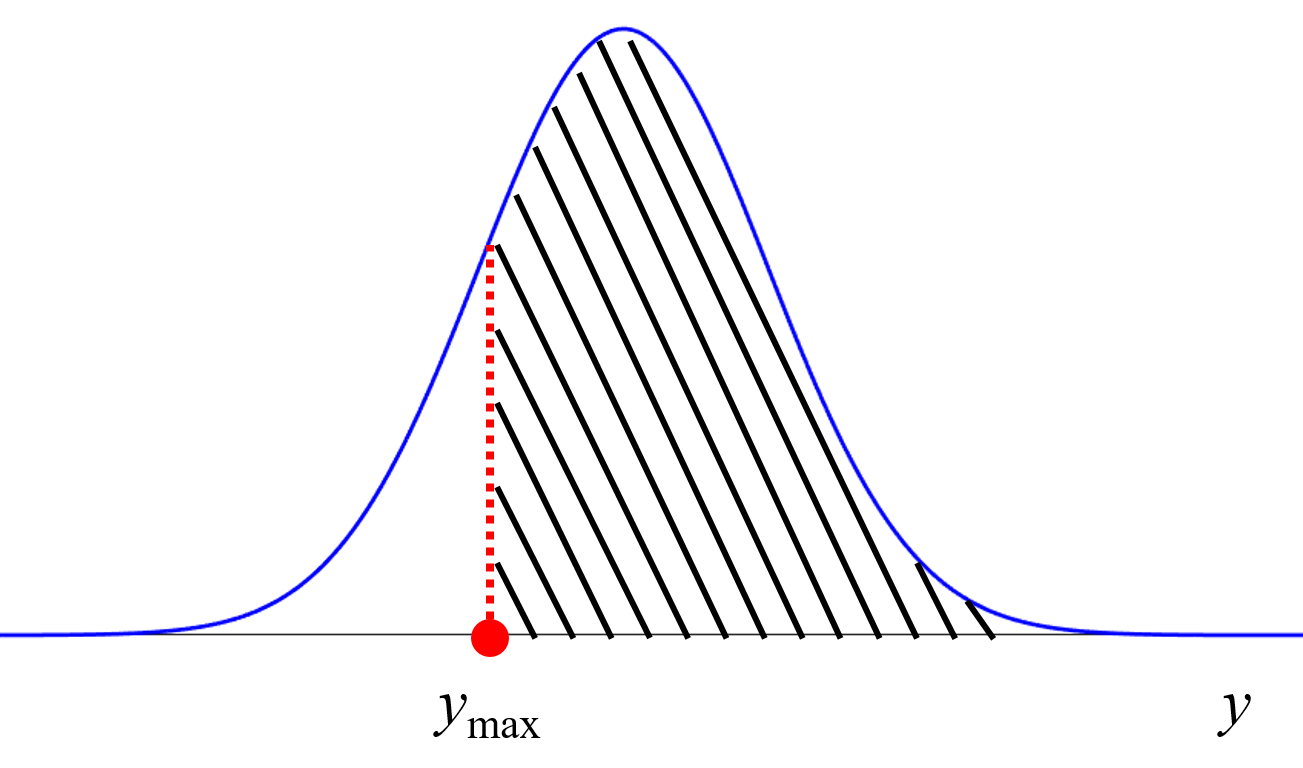
AD の考え方と BO を比較しますと、AD では予測値の標準偏差を、その範囲内で実測値が得られる可能性が高いといったように、標準偏差が小さい方がよいという使われ方をします、ベイズ最適化では逆に、標準偏差が大きい X のサンプルが選ばれる傾向が強いです。AD の外を選択する、という感じです。もちろん AD の外は非常に広いですので、その中でもどこが Y の目標を達成できる確率が高そうか、といったことを BO では計算しています。
BO では攻めの分子設計・材料設計・プロセス設計を行える一方で、実測値が実測値から外れる可能性も高いです。そのため、こちらでも書いていますように、BO では繰り返し実験をすることが前提になります。
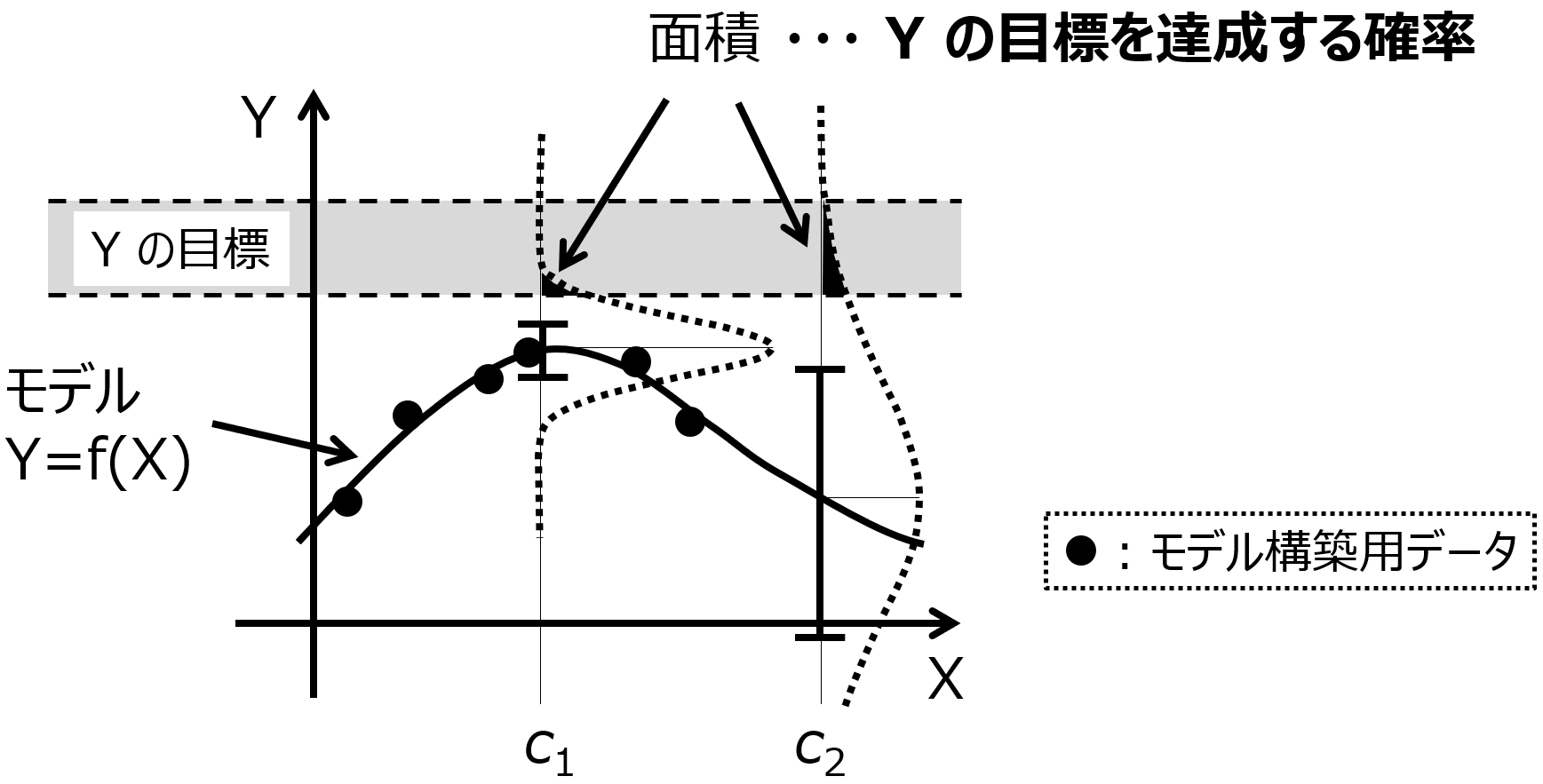
守りの AD 攻めの BO をうまく使い分けるとよいと思います。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。