2021 年 5 月 1 日に、金子弘昌著の「Pythonで気軽に化学・化学工学」が出版されました。
丸善: https://www.maruzen-publishing.co.jp/item/?book_no=304108
Amazon: https://www.amazon.co.jp/dp/4621306154
Amazon(Kindle): https://www.amazon.co.jp/dp/B096TGPDYP/
こちらの本は、前著の 「化学のための Pythonによるデータ解析・機械学習入門」 と同じようにデータ解析・機械学習の初学者向けの内容であり、さらにプログラミングについては、ソフトウェア (Jupyter Notebook) の使い方を解説したり、Python のコードを一行ずつ説明したりしているなど、より Python やプログラミングの未経験者向けの内容になっています。そのため、金子研に配属になった学生は、まず最初にこの本でトレーニングしています。
データ解析・機械学習やプログラミングの内容については、金子研の学部生、修士過程の学生、博士課程の学生にも確認してもらいながら精査しました。その精査も経て、よい仕上がりになったと思います。
さらに本書は、化学工学会の学会誌「化学工学」において全 12 回連載した「プログラミング未経験者のためのデータ解析・機械学習」に (大幅に) 加筆・修正をしたものとなっており、連載している際にいただいたフィードバックも反映されております。
ここでは本書の “まえがき”、目次の詳細、そしてなんと第1章から第3章まで、無料公開します (およそ 20000 字 + 図)。これらの無料公開をご快諾いただきました丸善の皆さまに感謝申し上げます。自信のある本だからこそ、ここまで無料公開できます。本書をご購入するときの参考になれば幸いです。それでは、よろしくお願いいたします。
[講演会やります!] 購入者限定の無料講演会「教えて金子先生!『Pythonで気軽に化学・化学工学』をうまく活用するにはどうしたらいいの?」
まえがき
本書のねらい
読者の皆さんは,社内や研究室内にデータをお持ちではないでしょうか?データを解析・分析した結果を活用することで,ご自身の研究や開発における壁を乗り越えたり,進捗を加速させたりできる可能性があります.本書では,データを持っていたり,収集する予定だったりする方が,プログラミングが未経験でもデータ解析・機械学習をできるようになることを目指しています.データを最大限に活用して研究・開発・設計・運転を促進することを期待しています.
データ解析・機械学習を応用できる分野は多種多様であり,必要となる知識・技術は分野によって異なります.一般的なデータ解析・機械学習の解説では,そうした分野特有の話題やノウハウが十分に説明されていなことが大半です.本書では,特に化学・化学工学分野において重要な内容を扱います.私はこれまで化学・化学工学分野において,
- 化合物の物性・特性・活性と化学構造との間の関係を明らかにする
- 高機能性が期待できる新しい化学構造を設計する
- 過去の実験データから次に行うべき実験の内容を提案する
- 化学プラントで製品を効率的・安定的に生産し続けるための制御手法を開発する
といった研究を通して,プログラミングを駆使しながら一般的なデータ解析・機械学習を行ったり,新たな手法を開発したりしてきました.研究の中には企業や大学などとの共同研究もあります.そのような経験の中で,化学・化学工学分野の研究者・開発者がデータ解析・機械学習をするうえで必要な知識・技術が整理されました.その内容を本書でお伝えします.
データ解析や機械学習に習熟すると,たとえば,次のようなことが可能になります.高機能性材料を開発していると,化合物の化学構造と物性・特性・活性の値が蓄積されます.化合物群を分子量や部分構造の数などの複数の変数で表現することによって,化学構造を数値化することができます(第 12 章参照).化合物群が数値データになるわけです.数値データにはたくさんの変数があるため,どの化合物同士が似ているか,似ていないかといった化合物の間の近接関係を見ることはできません.数値データを低次元化,すなわち少ない数(たとえば 2 つ)のパラメータに圧縮し,パラメータ間で化合物の散布図を見ることで,化合物群の全体の様子を見える化できます(第 6 章参照).これをデータの可視化と呼びます.数値データを用いれば,化合物群を意味のある集団(クラスター)ごとに自動的に分割することも可能です.これをクラスタリングと呼びます.データの可視化とクラスタリングの結果を見ることで,化合物間における化学構造の類似性と物性値の類似性とを同時に議論できるようになります(第 7 章参照).
回帰分析・クラス分類(第 8 章参照)により,化学構造を数値化した変数と物性との間に潜む関係性をデータから導きモデル化することも可能です.このモデルを用いれば,化合物を合成したり合成後に物性値を測定したりする前に,化学構造から物性値を推定できます.モデルを用いるというのは,仮想的な実験室で実験するようなものです.この実験室では実験に費用や時間はほとんどかかりません.実際に合成しようと思っても費用や時間の観点から現実的ではない何千・何万という数の化学構造でも物性値を推定できるため,良好な物性値をもつ化学構造を効率的に設計可能になります(第 8,12 章参照).
高機能性材料を開発する際には,材料そのものだけでなく製造条件を改善することで,材料特性などの製品品質を向上できます.製造条件とその製造の結果としての製品品質を用いて,回帰分析やクラス分類により製造条件と製品品質との間の関係をモデル化します.モデルを利用することで,望ましい品質を達成するための製造条件を探索可能です(第 9〜11 章参照).
高機能性材料を製造するときには,化学プラントを適切に制御して管理することが,高い品質の製品を製造し続けるのに必要不可欠です.プラントにおけるプロセス制御およびプロセス管理を困難にしている要因の 1 つに,製品品質を代表する濃度・密度などのプロセス変数の測定に時間がかかったり頻繁には測定されなかったりすることが挙げられます.製品品質を迅速に制御したり効率的にプロセスを管理したりするため,プラント運転時のセンサーなどの測定データや製品品質の測定データを活用します.データを用いて回帰分析やクラス分類をすることにより,センサーなどで容易に測定可能なプロセス変数と測定が困難なプロセス変数との関係をモデル化します.プラント運転時にこのモデルを用いることで,センサーなどによる測定結果から製品品質の値をリアルタイムに推定できます(第 8,9 章参照).実測値のように推定値を用いることで,迅速かつ安定に製品品質を制御できるようになります.
プラントのオペレーションにはこれまで広くデータが活用されてきましたが,プラントのさらなる高度化や省力化のため,新たな高機能性材料やその合成プロセス・製造プロセスの効率的な開発のため,研究開発の現場や製造現場に蓄積されているデータを解析・分析できることが強力な武器になります.
本書では,Python(パイソン)というプログラミング言語でデータの前処理・データの可視化・クラスタリング・回帰分析・クラス分類・モデルの解析を自分の手でできるようになることをねらいとします.
本書がプログラミング未経験者でも挫折しにくい理由
Python というプログラミング言語は,文法を単純化することでプログラムを読みやすく書きやすくなるように設計されています.プログラミングを初めて学ぶ人でも直感的に理解しやすいといわれています.
Python はデータ解析・機械学習の分野で注目されているため,統計処理・機械学習・科学技術計算などを行うための多くのソフトウェア(ライブラリ)が過去に Python で開発され,それらを無料で利用できます.既存のソフトウェアを活用することで,必要最低限のプログラミング技術のみでデータ解析を始められます.
プログラムを実行したり実行結果の確認・図示・保存をしたりするため,本書では Jupyter Notebook(ジュピター・ノートブック)という,ウェブブラウザを利用した無料の実行環境を使います.Jupyter Notebook では 1 行ずつ対話的にプログラミングでき,実行した出力結果をその都度確認しながら解析を進められるため,エラーが出ても対処しやすいでしょう.データ解析を進めながら簡単にメモを残せることも便利な点です.
本書では,読者がデータ解析・機械学習をできるようになるという目的のもと,Python プログラミングを体系的に学ぶのではなく,データ解析・機械学習に必須となることのみ学ぶようにしています.さらに,実行環境やソフトウェアの使い方およびデータ解析・機械学習を効率的に学ぶためのサンプルプログラムを配布します.本書を読むだけでなく,サンプルプログラムを実行しながら,データ解析・機械学習を学ぶことができます.サンプルプログラムと同種のデータ解析はすぐに実施できますし,新たなプログラムをゼロから書けるようにならなくてもサンプルプログラムの一部を変更して用いることで,自分のデータに合った解析を行えるようになります.このように,データ解析・機械学習を始めやすい言語と便利な実行環境を用い,学習内容をデータ解析・機械学習に特化したものに絞り,具体的なサンプルプログラムを活用しながら学習することにより,プログラミング未経験者でもデータ解析の学習に挫折しないように本書を執筆しました.
本書の内容
第 1 章から第 3 章までは,実行環境・ソフトウェアの使い方などの Python の基礎を学んで,データセットを読み込んだり,確認したり,保存したりできるようになります.
第 4 章では,データがどのようなものであるか概観したり,基本的な統計解析ができたりするようになります.
第 5 章から第 10 章までは,データ解析・機械学習の具体的な手法について学びます.第 5 章はデータの前処理を,第 6 章はデータの可視化を扱います.変数の数が多いデータにおいてもサンプル全体の様子を可視化できるようになります.第 7 章はクラスタリングを扱います.類似したサンプルごとに自動的にグループ分けできるようになります.第 8 章はクラス分類や回帰分析を扱います.新しいサンプルの目的変数(たとえば化合物の物性・特性・活性)を推定したり,推定結果を評価したりできるようになります.また繰り返し処理や条件分岐によって効率的にクラス分類・回帰分析ができるようになります.なお第 8 章は,データ解析・機械学習の鍵となる重要な内容を含むために,多くのページ数を割きました.第 9 章はモデルの適用範囲を扱います.クラス分類や回帰分析の推定結果の信頼性を議論できるようになります.第 10 章ではモデルの逆解析を扱います.クラス分類モデルや回帰モデルを運用して,目的変数が望ましい結果となる説明変数を設計できるようになり,材料設計やプロセス設計などの設計問題に応用できるようになります.
第 11 章では実験計画法と回帰分析により,実験計画を組んだり,既存の実験結果から目標を達成するための次の実験条件を探索したりします.
第 12 章は化学構造を扱います.化学構造を数値化できるようになることで,化学構造のデータを用いてクラス分類や回帰分析などの解析ができるようになります.
本書の内容は,高校卒業程度の数学の知識があることを前提としています.その他,数学的な用語にはその都度補足説明を入れたり,参考文献を紹介したりしています.なお,著者のウェブサイト[1] には,データ解析・機械学習に必要な数学の基礎や統計の基礎を学ぶための,著者がお薦めする本の紹介があります.
本書の読み方・進め方
本書ではサンプルプログラムを用います.本書を読みながらサンプルプログラムを実行しましょう.本文の説明がわからないと感じたときは,まずサンプルプログラムを実行してみて,そのあとに本文を読み直してみたり,ウェブ検索などでわからない単語の意味を補ってみたりするとよいでしょう.サンプルプログラムには練習問題もあります.学んだ内容を練習問題で確認しましょう.
サンプルプログラムを実行するために必要なサンプルデータセットも一緒に配布します.たとえば,仮想的な樹脂材料のデータのような,データの数が小さかったり,モデルで推定したい変数が 2 つあったり,その変数の値が存在しなかったりする,実際の状況を想定したサンプルデータも扱います.まだデータをお持ちでない方もご安心ください.
本書のサンプルプログラムやサンプルデータは,すべて以下の GitHub のウェブサイトからダウンロードできます.
ウェブサイトにおける(緑色の)“Code” をクリックしたあとに,“Download ZIP” をクリックしてください.
本書を読み進めるにあたっては,サンプルプログラムやサンプルデータ以外は以下の 3 点しか必要としません.
- PC(Windows,macOS,Linux など)
- ウェブブラウザ(Chrome,Safari,Firefox など)
- 第 1 章でインストールする Anaconda(アナコンダ)
ウェブブラウザに関して,特に設定を変更していない方は追加の設定をする必要はありません.
それでは,本書をお楽しみいただけますと幸いです.
謝 辞
本書は,化学工学会の学会誌「化学工学」において 2019 年 8 月(Vol. 83 No. 8)から 2020 年 6 月(Vol. 84 No. 6)まで全 12 回連載した「プログラミング未経験者のためのデータ解析・機械学習」に加筆・修正をしたものです.連載におきまして内容の精査および原稿の推敲・校閲などで多大なご協力をいただきました化工誌編集委員の皆様に心より感謝申し上げます.
本書の原稿の確認やサンプルプログラムの検証について,明治大学のデータ化学工学研究室(金子研究室)の石田敦子さん,畠沢翔太さん,江尾知也さん,山田信仁さん,岩間稜さん,谷脇寛明さん,山影柊斗さん,山本統久さん,杉崎大将さん,高橋朋基さん,池田美月さん,今井航彦さん,金子大悟さん,中山祐生さん,本島康平さん,湯山春介さん,吉塚淳平さんにご助力いただきました.ここに記し,感謝の意を表します.ありがとうございました.また,自宅で執筆していても温かく見守ってくれた妻の藍子と,おとなしくしてくれた娘の瑠那と真璃衣に感謝します.
2021 年 3 月
金子弘昌
目次
1. 必要なソフトウェアをインストールして,Jupyter NotebookやPythonに慣れる
1.1 Anaconda のインストール
1.2 Jupyter Notebook の使い方
1.3 Jupyter Notebook の起動
1.4 セルおよびセルのタイプとモード
1.5 セルの実行
1.6 おもな操作方法
1.7 キーボードショートカット
1.8 Jupyter Notebook の終了
2. Pythonプログラミングの基礎を学ぶ
2.1 数値や文字などの扱い
2.2 数値や文字の集合の扱い
2.3 組み込み関数による効率的な処理
3. データセットの読み込み・確認・変換・保存ができるようになる
3.1 データセットの読み込み
3.2 データセットの中身の確認
3.3 データセットの保存
4. データセットの特徴を把握する
4.1 行列形式によるデータセットの表現
4.2 ヒストグラムによるデータの分布の確認
4.3 おもな基礎統計量を計算することによる特徴量間の比較
4.4 散布図による特徴量間の関係の確認
4.5 相関係数による特徴量間の関係の強さの確認
5. データセットを前処理して扱いやすくする
5.1 特徴量のスケールの統一化
5.1.1 データセットの行列・ベクトルによる表現
5.1.2 特徴量の標準化
5.2 ばらつきの小さい特徴量の削除
5.3 類似した特徴量の組における一方の特徴量の削除
6. データセットの見える化(可視化)をする
6.1 主成分分析
6.2 t-distributed Stochastic Neighbor Embedding (t-SNE)
7. データセットを類似するサンプルごとにグループ化する
7.1 クラスタリング
7.2 階層的クラスタリングの基礎
7.3 階層的クラスタリングの実行
7.4 化学・化学工学での応用
8. モデルy=f(x)を構築して,新たなサンプルのyを推定する
8.1 クラス分類(クラス分類とクラスタリングとの違い,教師あり学習と教師なし学習)
8.2 k-NN によるクラス分類とクラス分類モデルの推定性能の評価
8.2.1 k-NN によるクラス分類
8.2.2 クラス分類モデルの推定性能の評価
8.2.3 k-NN によるクラス分類の実行
8.3 回帰分析
8.4 k-NN や最小二乗法による回帰分析と回帰モデルの推定性能の評価
8.4.1 k-NN を使った回帰分析
8.4.2 OLS 法を使った回帰分析
8.4.3 回帰モデルの推定性能の評価
8.4.4 k-NN,OLS 法による回帰分析の実行
8.5 モデルの推定性能を低下させる要因とその解決手法(PLS)
8.5.1 オーバーフィッティング
8.5.2 多 重 共 線 性
8.5.3 PLS 法の基礎
8.5.4 PLS 法による回帰分析の実行
8.6 さまざまな解析の自動化・効率化
8.6.1 CV に基づくハイパーパラメータの決定方法
8.6.2 外部バリデーションと内部バリデーション
8.6.3 for 文によるハイパーパラメータの決定
8.6.4 if 文による複数の手法を用いたデータ解析
8.7 非線形の回帰分析手法やクラス分類手法
8.7.1 サポートベクターマシン
8.7.2 サポートベクター回帰
8.7.3 決定木
8.7.4 ランダムフォレスト
8.8 ダブルクロスバリデーション
8.9 化学・化学工学での応用
9. モデルの推定結果の信頼性を議論する
9.1 目的変数の推定に用いる最終的なモデル
9.2 モデルの適用範囲
9.2.1 範囲
9.2.2 平均からの距離
9.2.3 データ密度
9.2.4 アンサンブル学習法
9.2.5 ADの設定
9.3 One-Class Support Vector Machine (OCSVM)
10. モデルを用いてyからxを推定する
10.1 仮想サンプルの生成
10.2 仮想サンプルの予測および候補の選択
11. 目標達成に向けて実験条件・製造条件を提案する
11.1 実験計画法
11.2 応答曲面法
11.3 適応的実験計画法
12. 化学構造を扱う
12.1 RDKit のインストール
12.2 化学構造の表現方法
12.2.1 SMILES
12.2.2 Molfile
12.3 化合物群の扱い
12.4 化学構造の数値化
12.5 化学構造のデータセットを扱うときの注意点およびデータセットの前処理
おわりに
参考資料
索引
1. 必要なソフトウェアをインストールして, Jupyter NotebookやPythonに慣れる
1.1 Anacondaのインストール
Anaconda(アナコンダ)は,統計処理・機械学習・科学技術計算などを行うためのソフトウェアの集まりであり,Python(パイソン)でデータ解析・機械学習をする環境を無料で簡単に構築できます.python.jp サイト[2] から,各自の OS に合わせて Windows,macOS,Linux などを選択したあとに,Python 3.x version をダウンロードしてインストールしてください.
Windows 利用者でユーザ名に半角英数字記号以外の日本語などを使っている方は,インストール後に不具合を起こす可能性があるため,デフォルトのインストール先フォルダ(C:¥Users¥[ユーザ名])にではなく,日本語を含まないフォルダ(たとえば C:¥python)を作成し,そこにインストールするとよいでしょう.
1.2 Jupyter Notebookの使い方
“まえがき”でそのメリットを説明したように,Python でプログラミングをしたり,実行した結果の確認・図示・保存をしたりするため,Jupyter Notebook(ジュピター・ノートブック)を使います.Anaconda をインストールしたときに,Jupyter Notebook も一緒にインストールされています.Python プログラミングを効率的に行うためには,そのための実行環境である Jupyter Notebook を使いこなせるようになることが近道です.
Jupyter Notebook を起動する方法を説明したあとに,Jupyter Notebook の使い方を丁寧に説明します.Jupyter Notebook を起動できたら,説明を読みながらサンプルプログラムで説明の内容を確認しましょう.
1.3 Jupyter Notebookの起動
以下の説明で Jupyter Notebook を起動できなかった場合は,こちらのウェブサイト[3] をご覧ください.補足の説明も記載されているため,不明点のある方も参照するとよいでしょう.
Windows の方は,スタートボタン → Anaconda3(64-bit)(32-bit OS の方は Anaconda3) → Jupyter Notebook で起動できます.macOS の方ははじめにターミナルを起動しましょう.Launchpad → その他 → ターミナルで起動できます.ターミナルにて,jupyter notebookと入力して,Enter キーを押すことで実行しましょう.これにより普段使っているブラウザ上にて,図 1-1 のように Jupyter Notebook が起動されます.
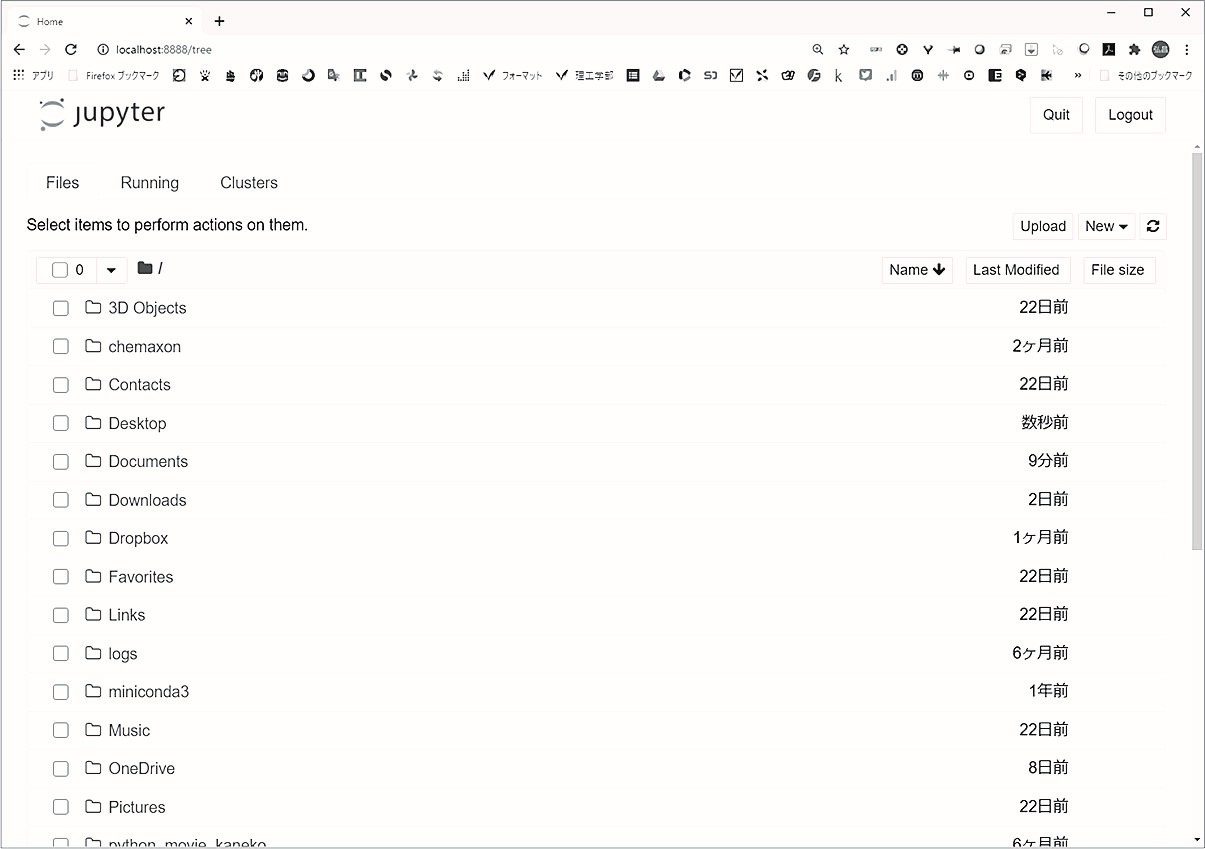
図1-1 Jupyter Notebook の起動画面(Notebook Dashboard)ブラウザとして Chrome[4]を使用.
特に設定を変更していない方は,Windows では C:¥Users¥[ユーザ名] において,macOS では Users/[ユーザ名] において Jupyter Notebook が起動されるしょう.本書では,このフォルダ(Windows では C:¥Users¥[ユーザ名],macOS では Users/[ユーザ名])に作業用フォルダを作成します.python_scej という名前のフォルダを作成しましょう.基本的にはこのフォルダ(ディレクトリ)で作業します.本書で用いるファイルはこのフォルダに置きましょう.
本章のサンプルプログラム(サンプル Notebook)sample_program_1.ipynb は GitHub のウェブサイト[5 https://github.com/hkaneko1985/python_chem_chem_eng/] にあります.他のサンプル Notebook やサンプルデータセットと一緒に zip ファイルでダウンロードし,解凍しましょう.ダウンロードは,ウェブサイトにおける(緑色の)“Code”をクリックしたあとに,“Download ZIP” をクリックしてください.万が一 zip ファイルを解凍できない方はこちらのウェブサイト[6,7] を参照ください.すべてのファイルを作業用フォルダ内に置いてください.
Jupyter Notebook の起動画面(図 1-1)において,作業用フォルダ python_scej をクリックするとそのフォルダに移動できます.sample_program_1.ipynb などのファイルが表示されたでしょうか? sample_program_1.ipynb をクリックすることでサンプル Notebook を開きましょう.図 1-2 のような表示画面になることを確認してください.

図1-2 サンプル Notebook の表示画面(Notebook Editor)
Jupyter Notebook 上ではなく,Windows エクスプローラや macOS Finder のフォルダ上で sample_program_1.ipynb をダブルクリックなどしても,Notebook を開くことはできないため注意しましょう.
1.4 セルおよびセルのタイプとモード
Jupyter Notebook では,“セル” と呼ばれる領域に Python プログラムの命令(ソースコード,あるいは単純にコード)やテキストを記入します.開いているサンプル Notebook で,“Python で気軽に化学・化学工学” と書いてある領域,“このサンプル Notebook を〜” と書いてある領域をクリックすると,それぞれ異なる領域がアクティブになり,異なるセルに内容が記載されていることがわかると思います.コードやテキストが記述されたセルを実行することで,その内容を実現できます.Jupyter Notebook では複数のセルを用いて,セルへのコードの記入と実行とを繰り返しながら Python プログラミングを進めます.
セルには Code セルと Markdown セルの 2 タイプがあり,それぞれに編集モードとコマンドモードがあります.Python プログラミングを効率的に行うため,まずはセルのタイプとモードを理解しましょう.
Code セルはコードを書き,それを実行するためのセルです.サンプルプログラムにおける “#Code セルの例” とある 3 つ目のセルをクリックしてください.
Code セルの左には “In[ ]: ” と記載されており,セルを実行すると実行したコードの順番が[ ]の中に表示されます.# を書くとそれより右側はコメントとして扱われ,実行されません.コメントの数字や文字は緑色の斜体で表示されます.コメント以外のコードは基本的に半角英数字記号を使います.
Markdown セルは,プログラムを見やすくしたり,説明を加えたり,実行結果に関するメモを残したりしたいときに,セルにテキストを書くためのもので,日本語も使えます.サンプル Notebook における 1 つ目,2 つ目や 4 つ目のセルが Markdown セルの例です.Markdown 記法[8] と呼ばれる記法により,文字を * で囲むことで斜体にしたり,** で囲むことで太字にしたりなど装飾することもでき,実行することで装飾が反映されます.サンプル Notebook における 1 つ目のセルでは Markdown 記法の # を使用して見出しにしています.セルをダブルクリックして編集モードにすることで # が出ることを確認しましょう(図 1-3).
Run ボタン(図 1-3)を押すと実行され,装飾が反映された状態に戻ることを確認しましょう.同じ # でも Code セルと Markdown セルとで意味が異なるため注意してください.Markdown 記法で装飾したい場合は,こちらのウェブサイト[9] を参考にするとよいでしょう.
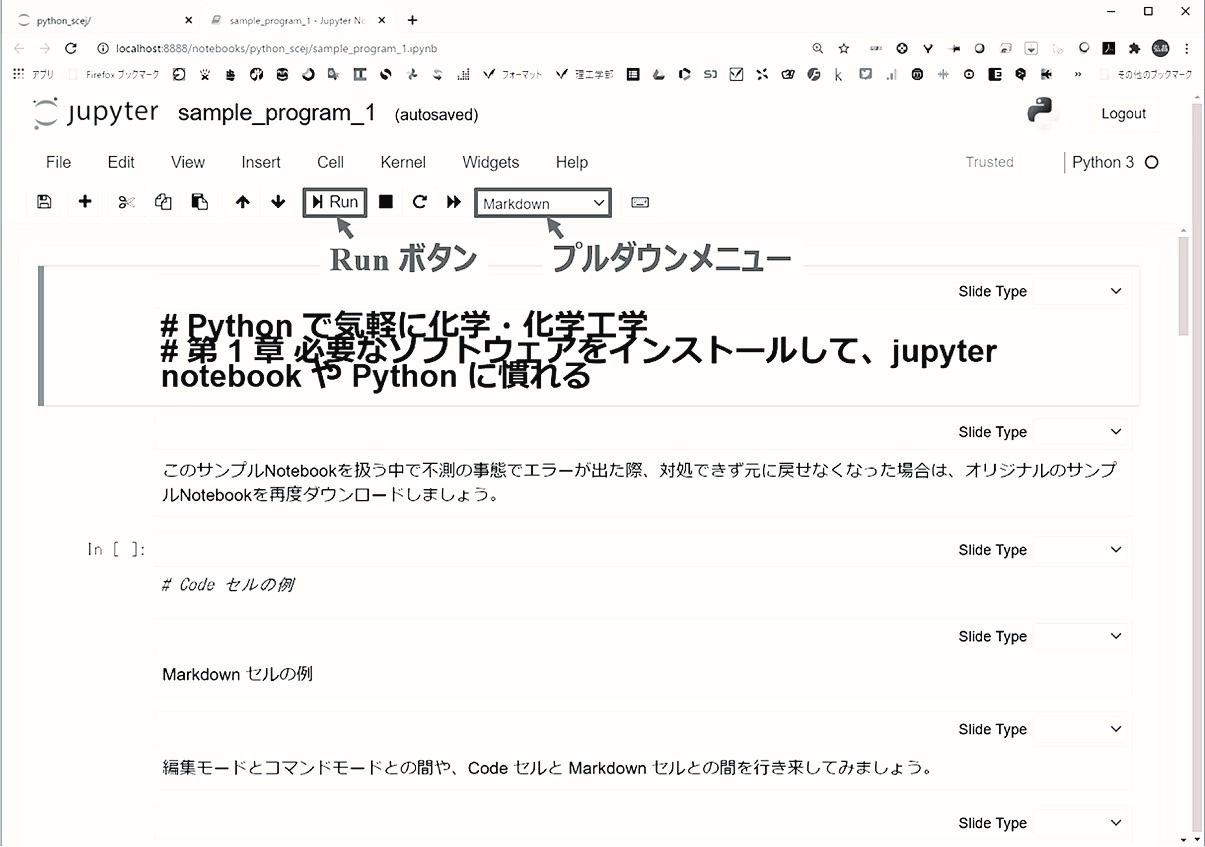
図1-3 Markdown セルの編集モード
Code セルと Markdown セルには,それぞれ編集モードとコマンドモードがあります.編集モードでは対象のセルにおける外枠の左側が緑色になり,コードやテキストを書き込めます.コマンドモードでは対象のセルにおける外枠の左側が水色になり,カーソルキー上で上のセルに,カーソルキー下で下のセルに移動できます.モードとタイプの変更の仕方を説明します.セルをクリックして対象のセルに移動しましょう.セルの左端をクリックするとコマンドモードに,記述がある領域をクリックすると編集モードに移行できます.実行後の Markdown セルでは編集モードに移行するために記述がある領域をダブルクリックする必要があります.プルダウンメニュー(図 1-3)で Code を選ぶと Code セルに,Markdown を選ぶと Markdown セルに対象セルのタイプを変更できます.
サンプル Notebook の 5 つ目のセルにおいて,編集モードとコマンドモードとの間や,Code セルと Markdown セルとの間を行き来しましょう.
1.5 セルの実行
1.4 節において Markdown セルを実行したように,セルがどのタイプやモードであっても Run ボタンを押すと,そのセルの内容を実行できます.Code セルではコードが実行され,Markdown セルでは文字の装飾が反映されます.
実行のショートカットキーは Ctrl+Enter キー(Ctrl キーを押しながら Enter キーを押す)です.Shift+Enter キーにより,セルの内容を実行して下のセルに移動できます.連続するセルの内容を続けて実行したいときに便利です.
Markdown セルとして作成した,Python コードが記述されていないセルを,Code セルに変更して実行すると,内容が Python コードでないためエラーとなりますので注意しましょう.
サンプル Notebook における 6 つ目以降の足し算・引き算・掛け算・割り算・余り・べき乗の例を実行してください.足し算であれば図 1-4 のように,Code セルの下に “Out[2]: 137” など,計算結果が表示されることを確認しましょう.
Code セルにおいてコードを変更したあと,再度実行しないと “Out[ ]: ” の結果は更新されません.注意しましょう.

図1-4 足し算の実行結果
1.6 おもな操作方法
その他,Jupyter Notebook でよく使う操作は以下のとおりです.
- 1 つ下に空のセルを挿入:メニューの Insert → Insert Cell Below
- セルを削除:メニューの Edit → Delete Cells
- セルをコピー:メニューの Edit → Copy Cells
- セルを切り取り:メニューの Edit → Cut Cells
- セルを下に貼り付け:メニューの Edit → Paste Cells Below
これらの操作方法を参考にして,新たなセルを挿入し,そのセルを削除してみましょう.
再び新たなセルを挿入し,四則演算を組み合わせた計算をするためのコードを書いてください.そのセルを実行し,計算結果が正しいか確認しましょう.たとえば,身長 172 cm で体重 58 kg の人の BMI の値(体重 [kg]÷身長 [m]÷身長 [m])を計算してみましょう.およそ 19.6 と計算されたでしょうか? ちょっと痩せぎみですね.自身の BMI についても計算してみましょう.
1.7 キーボードショートカット
Jupyter Notebook で Python プログラミングするときに便利なキーボードショートカットがあります.セルを実行するときに用いた Ctrl+Enter キーや Shift+ Enter キーもその 1 つです.キーボードショートカットを駆使することで,キーボードのみで効率的に Python プログラミングができるようになります.サンプル Notebook の最後のセルに “Jupyter Notebook の有用な操作方法のまとめ” があります.ぜひご活用ください.
1.8 Jupyter Notebookの終了
上書き保存の仕方は,メニューの File → Save and Checkpoint もしくは,Ctrl+ S キー(Word や Excel などと同じ)です.こまめに保存しながら進めるようにしましょう.
最後に,サンプル Notebook を閉じて,Jupyter Notebook を終了する方法を説明します.まず,サンプル Notebook の表示画面(図 1-2)において,File タブ→ Close and Halt でサンプル Notebook を閉じます.次に,Jupyter Notebook の起動画面(図 1-1)において Quit をクリックすることで Jupyter Notebook を終了できます.最後に,ブラウザの Jupyter Notebook のタブを閉じましょう.
2. Pythonプログラミングの基礎を学ぶ
第 1 章では,Python プログラミングを行うためのソフトウェア Jupyter Notebook の使い方を学び,Python で四則演算をしました.本章では,Python プログラミングの基礎を学びます.
本章ではサンプル Notebook の sample_program_2.ipynb を用います.GitHub のウェブサイト[5 https://github.com/hkaneko1985/python_chem_chem_eng/] からダウンロードして,第 1 章のサンプル Notebook と同じ作業用フォルダ(ディレクトリ)に置いてください.Jupyter Notebook でサンプル Notebook を開き,今回の内容に対応するタイトルが Markdown セルに記載されており,必要に応じて Code セルにコードが記載されていることを確認してください.
2.1 数値や文字などの扱い
多くのプログラミング言語では,変数を宣言して作成したり,変数に数値や文字などを代入したり,それを使用したりします.Python では,事前に変数を宣言する必要はありません.たとえば x = 1 は,x という名前の変数を作成し,数値 1 を x に代入することを意味します.x = 1 と記載されているセルを実行すると x に 1 が代入され,x とだけ書いてある次のセルを実行すると 1 と表示されます.その次のセルを実行すると答えは 3 と表示されます.
数値や文字を代入した変数に,別の数値や文字を代入すると変数の値が置き換わります.ここまで,x は 1 でしたが,x = 3 とすれば,x の値は 3 になります.x だけ書かれた次のセルを実行すれば 3 と表示されるでしょう.この状態で x = x + 6 とあるセルを実行すると 9 と表示されます.ここで,x + 6 の計算をしたあとに,その計算値を x に代入するので,このセルの実行後は x の値は 9 になります.次の 3 つのセルを実行することで,x,y,z の変数を用いた計算の結果を確認しましょう.なお,Code セルの最後の行が,変数名だけや変数を用いた計算だけのときには,そのセルを実行すると実行結果が表示されます.
Code セルにおいてコードを変更したあと,再度実行しないと変数の内容は更新されません.セルの内容を変更したら,忘れずに実行するようにしましょう.
変数名を単に a とか b とかにすると,他の人や時間が経ったあとの自分が見たときに理解しにくい Python コードになります.わかりやすい変数の名前に設定する習慣を身につけることが重要です.
多くの変数を作成したあと,作成したすべての変数名を一字一句間違わずに思い出すことは容易ではありません.そのようなときには whos コマンドで存在する変数を表示できます.whos と記載されたセルを実行すると,これまでに作成した変数の情報が表示されることを確認してください.表示される情報は,Variable,Type,Data/Info で,それぞれ変数名,データ型,変数の値を意味します.データ型については後述します.
whos で存在する変数を確認できるといっても,変数が多すぎると煩雑になってしまいます.不要になった変数は del で消去できます.delx とあるセルと whos とあるセルをそれぞれ実行し,x が削除されていることを確認してください.del y,z のように変数名をカンマで区切って並べることで,複数の変数を同時に消去できます.すべての変数を消去するには,reset を実行します.その際,“Once deleted, variables cannot be recovered. Proceed (y/[n])? ” と聞かれますので,削除して問題なければ y を(半角で)入力して Enter キーを押すと実際にすべての変数が消去され(n を入力あるいは何も入力しないで Enter で取り消し),whos の実行結果は,“Interactive namespace is empty.” となります.ここまで対応するセルを逐次実行しましょう.
変数操作の基本を理解したかどうかの確認のため,実際にコードを書いてみましょう.密度 998 kg/m3,粘度 0.001 005 Pa・s の流体が,内径 0.030 m の円管を流束 0.10 m/s で流れています.まず,密度・粘性係数・内径・流束の変数をわかりやすい名前で作成し,値を代入してください.その際,スラッシュは割り算を意味するため,変数名に使うことはできないことに注意しましょう.変数に値を入力した後,密度 [kg/m3]×流束 [m/s]×内径 [m]÷粘度 [Pa・s]でレイノルズ数を計算するコードを書いてみてください.コードの例はサンプル Notebook の一番下にあります.
2.2 数値や文字の集合の扱い
ここまでは変数に数値を代入しましたが,文字列などを代入することもできます.数値や文字列などのデータの種類をデータ型と呼びます.前節で whos を実行した際に Type と出力された列がデータ型を意味しています.Python でよく使うデータ型は以下のとおりです.
- 数値型 int,float
- シーケンス型 str,tuple,list
数値型は数値を扱うデータ型で,int は整数(integer)に,float は小数を含む数(浮動小数点数)に対応します.変数に代入するときには,データ型を気にする必要はありません.変数に整数を代入すればその変数のデータ型は int 型に,小数を代入すれば float 型になります.ある変数のデータ型を知りたいときには,type(変数名) と入力します.サンプル Notebook では reset で一度変数を削除していますので,height_cm = 172.2 とあるセルを実行することで変数に数値を代入し,その後 type(height_cm) と書かれたセルを実行してデータ型を確認してください.
シーケンス型は順番のある要素の集合を扱うデータ型です.その 1 つである str では文字列(strings)を扱います.ʻ(シングルクオテーション)もしくは “(ダブルクオテーション)で囲むと文字列になります.変数に文字列を代入すればその変数のデータ型は str 型になります.last_name =ʻkanekoʼ とあるセルを実行することで変数に文字列を代入し,中身を表示して確認してから,type(last_name) と書かれたセルを実行してデータ型を確認してください.その後の 3 つのセルで,ダブルクオテーションで文字列を作る例がありますので実行して確認しましょう.
53.5 のデータ型は float 型であり,ʻ53.5ʼ のデータ型は str 型です.サンプル Notebook にあるように type(53.5) や type(ʻ53.5ʼ) と type( ) に直接数値や文字列を入力することで,そのデータ型を出力させることもできます.
tuple(タプル),list(リスト)は,数値や文字列といった要素を複数扱うときに用います.中の要素を初期の値から変更できないようにしたいときには tuple を用い,変更したいときは list を用います.原子量などの物理量をまとめた変数を tuple 型で作成すれば,プログラム中で不用意に変更される心配はありません.
tuple の要素は ( ) で囲み,カンマで要素を区切ります.numbers =(1,2,3,4,5) とあるセルを実行することで変数に tuple を代入し,その後 numbers とあるセルを実行して中身を確認してください.tuple 型の変数では,[ ]の中に要素の順番を入れて中の要素を選択します.Python では順番が 0 から始まることに注意してください.numbers[0] を実行すると 1,numbers[2] を実行すると 3 と表示されます.[ ]の中を−1 とすると一番最後を選択でき,−2,−3,… はそれぞれ最後から 2,3,… 番目を意味します.numbers[-1] を実行すると 5,numbers[-2] を実行すると 4 と表示されます.
tuple の変数の要素を変更しようとするとエラーになります.numbers[0]= 6 とあ る セ ル を 実 行 す る こ と でêTypeError:ʻtupleʼ object does not support item assignmentòというエラーが表示されることを確認しましょう.先に説明したように tuple では中の要素を初期の値から変更できないことがエラーの内容からもわかります.
list の要素は[ ]で囲み,カンマで要素を区切ります.characters =[ʻaʼ,ʻbʼ, ʻcʼ,ʻdʼ] とあるセルを実行することで変数に list を代入し,その後 characters とあるセルを実行して中身を確認してください.list 型の変数でも,tuple 型の変数と同様にして中の要素を選択します.characters[0] を実行すると ʻaʼ が表示されます.list 型の変数は中の要素を変更可能です.characters[2]=ʻeʼ と書かれたセルを実行してから characters の中身を表示すると [ʻaʼ,ʻbʼ,ʻcʼ,ʻdʼ] となります.
2.3 組み込み関数による効率的な処理
関数とはプログラム上で定義された複数の処理がまとめられたものです.関数は入力される値(引数:ひきすう)に基づいて関数内で処理をして,その結果(返値:かえりち)を出力します.Python にあらかじめ実装されている関数(組み込み関数)の中では,以下の 3 つをよく使います.
- print( )
- len( )
- sum( )
print( ) は ( ) 内の数値や文字列などを表示する関数です.print(ʻHello Worldʼ) とあるセルを実行すれば,Hello World という文字列が表示されます.繰り返し計算をするときに,print( ) で繰り返し回数を表示させることで,計算の進捗状況を把握できます.
len( ) は( )内の str,tuple,list などのベクトルの長さを返す関数です.文字列では文字数を,tuple や list では要素の数を取得します.len(ʻHello Worldʼ) とあるセルを実行すると半角スペースを入れた文字数が,len(numbers) や len (characters) とあるセルを実行すると,それぞれ tuple や list の要素数が表示されることを確認しましょう.prices =[ ] と書かれたセルを実行して空の list の変数を作成すると,要素数は 0 ですので,len(prices) とあるセルを実行すると 0 になります.
sum( ) は ( ) 内の要素の総和を返す関数です.sum(numbers) を実行すると, 1,2,3,4,5 の総和である 15 が表示されます.数値のみが格納されている tuple, list しか入力できないため注意しましょう.sum(characters) を実行するとエラーになります.
len( ) や sum( ) を用いて,数値を要素とする list の変数の平均値を計算できます.平均値は要素の総和を要素数で割った値です.たとえば,numbers =[4,3,1, 5,2] の平均値を計算してみましょう.3.0 と計算されたでしょうか? コードの例はサンプル Notebook の 1 番下にあります.
データ解析・機械学習を行うための Python プログラミングの基礎は以上であり,その他の必要なプログラミング技術については今後の各節の中でその都度扱います.さらにプログラミングを学習したい方は Python の入門書[10] が参考になります.
3. データセットの読み込み・確認・変換・保存ができるようになる
第 2 章では,Python プログラミングの基礎を学びました.本章では,解析を行うためのデータセットの読み込みや,データセットの確認・変換・保存ができるようになることを目標とします.
本章ではサンプル Notebook の sample_program_3.ipynb を用います.GitHub のウェブサイト[5 https://github.com/hkaneko1985/python_chem_chem_eng/] からダウンロードして,作業用フォルダ(ディレクトリ)に置いてください.
本書では,データを扱うときに csv ファイルを用います.文字化けを防ぐ観点から,csv ファイルの名前や csv ファイルの中身は半角英数字に限定しています.ご了承いただくとともに,csv ファイルにおいて日本語をお使いの方は半角英数字に変換をお願いします.
3.1 データセットの読み込み
今回の説明に用いるサンプルデータ iris_with_species.csv は Fisher の論文[11] にあるあやめのデータセット(Fisherʼs Iris Data)[12] です.iris_with_species.csv は GitHub のウェブサイト[5] にサンプル Notebook と一緒にあります.150 個のあやめについて,がく片長(Sepal Length),がく片幅(Sepal Width),花びら長(Petal Length),花びら幅(Petal Width)が計測されており,csv 形式で格納されています.ダウンロードしたファイルを Excel などで一度中身を確認してください.
本書では iris_with_species.csv のように,サンプルが縦に,サンプルを表現するための特徴量(変数のほうが一般的な呼び方ですが,プログラミングにおける変数と区別するため特徴量と表現します)が横に並ぶ形式の数値や文字列の集まりをデ ー タ セ ッ ト と 呼 び ま す.デ ー タ セ ッ ト に お い て,iris_with_species. csv の sample1,sample2 のような 1 番左の列はサンプルの名前,Species,Sepal.Length のような 1 番上の行は特徴量の名前として,データセットの中身とは別に扱います.あるサンプルのある特徴量の中身は,数値でも文字列でも構いません.
csv ファイルのデータセットを読み込むため,第 1 章でインストールした Anaconda のパッケージ内にある pandas[13] というプログラム群(ライブラリ)を Jupyter Notebook 上で使用します.pandas はデータ解析をサポートするライブラリの 1 つです.pandas を活用することでデータの読み込み・操作・保存といった基本的なデータの扱いや,基礎統計量の計算などができます.
pandas 自体はすでにインストールされていますが,そのままでは利用することができません.Jupyter Notebook で importpandas というコードを実行することで,pandas を取り込んで利用できるようになります.
データセットの読み込みには,pandas.read_csv( ) を用います.( ) 内における index_col = 0 は csv ファイルの 1 番左の列は各行の名前(サンプルの名前)とすることを,header = 0 は 1 番上の行は各列の名前(特徴量の名前)とすることを意味します.dataset = pandas.read_csv(ʻiris_with_species.csvʼ,index_ col = 0,header = 0) が記述されたセルを実行することで,データセットを読み込み dataset という変数に格納しています.dataset とあるセルを実行することで,Jupyter Notebook 上で dataset を表示すると,図 3.1 のようになることを確認してください.
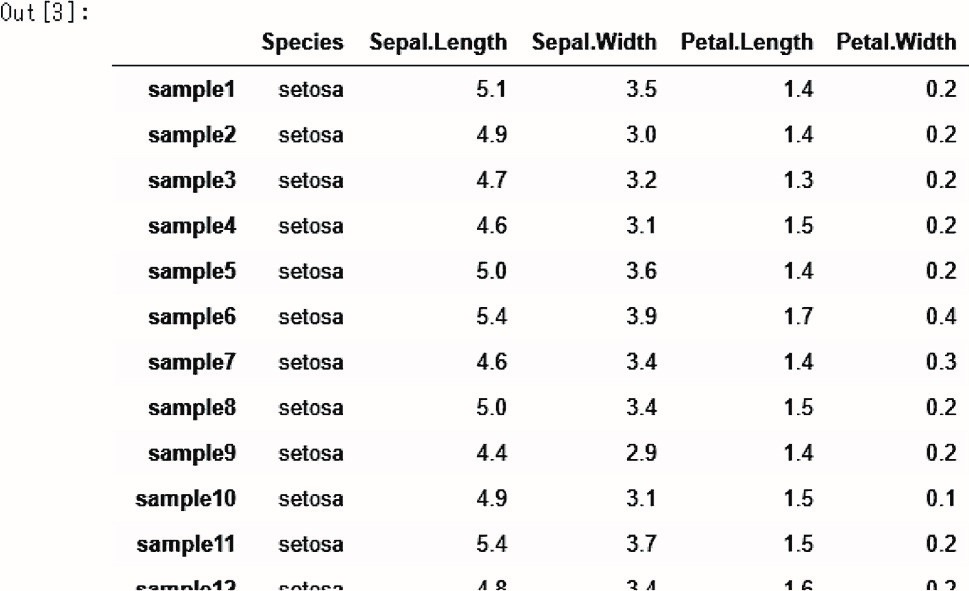
図3-1 あやめのデータセットの一部
csv ファイルを Jupyter Notebook で読み込んだあとに表示.
先 ほ ど import pandas で pandas を 取 り 込 み ま し た が,一 般 的 に は import pandas as pd と,名前を pd と名付けて取り込みます.プログラム内で pandas と長い名前を使わずに pd と短くすることでライブラリ内の関数を扱いやすくします.データセットの読み込みも dataset = pd.read_csv(ʻiris_with_species. csvʼ,index=0, header=0) となります.サンプル Notebook における次の 3 つのCode セルを実行し,データセットを読み込めることを確認しましょう.
type(dataset) で dataset のデータ型を確認すると,“pandas.core.frame.DataFrame” と表示されます.これを略して DataFrame 型と呼びます.
3.2 データセットの中身の確認
データセットの大きさを調べるためには shape を使います.DataFrame 型の変数では,変数名.shape とすることで,大きさを取得できます.dataset.shape とあるセルを実行することで “(150,5)” と表示されることを確認しましょう.dataset.shape[0],dataset.shape[1] とあるセルを実行すると,それぞれ“150”,“5” と表示されます.あやめのデータセットは,行の数(サンプルの数)が 150,列の数(特徴量の数)が 5 であることがわかります.
DataFrame 型の変数では,変数名.index とすることで行の名前(サンプルの名前)を,変数名.columns とすることで列の名前(特徴量の名前)を取得できます. dataset.index や dataset.columns とあるセルを実行することで,それぞれサンプルの名前や特徴量の名前が表示されることを確認しましょう.“length=150“は行の数(サンプル数)が 150 であることを,”dtype=ʻobjectʼ“ は中身が文字列であることを表しますが,特に気にしなくて構いません.
dataset.index,dataset.columns ともに,tuple,list と同様にして [ ] の中に要素の順番を入れることで,対象の番号の要素のみを選択できます.dataset. index[0],dataset.columns[0] とあるセルを実行することで,それぞれ最初のサンプルの名前,最初の特徴量の名前が表示されます.順番を[2,4]のように list で与えることで,各要素の順番に対応した複数個の要素を選択できます.たとえば, dataset.index[[2,4]] としたセルを実行すると,(0 番目から数えて)2 番目と 4 番目のサンプル名(すなわち,dataset.index[2]および dataset.index[4])を表示できます.dataset.index[[5,10,3]] とあるセルも実行して結果を確認しましょう.dtype=ʻobjectʼは中身が文字列であることを表しますが,特に気にしなくて構いません.i 番目から j 番目までのすべての要素を参照したいときは,dataset.index[i:j + 1] とします.dataset.index[31:35] とあるセルを実行すると,31 番目から 34 番目までのサンプル名が表示されます.[ ] の中を−1 とすると一番最後を参照でき,−2,−3,… はそれぞれ最後から 2,3,… 番目を意味します.dataset.index[-1],dataset.columns[-1] とあるセルを実行すると,それぞれ最後のサンプル名,最後の特徴量の名前が表示されます.余裕のある方は,サンプル Notebook においてセルを追加し,適当な順番のサンプル名や特徴量名を出力して,csv ファイルのサンプル名や特徴量名と等しくなることを確認しましょう.
DataFrame 型の変数では,変数名.iloc[i,j] とすることで,i 番目の行(サンプル)における j 番目の列(特徴量)の要素を選択できます.dataset.iloc[0,0] のセルを実行すると “ʻsetosaʼ”,dataset.iloc[2,3] のセルを実行すると “1.3” と表示されます.また,i 番目のサンプルにおけるすべての特徴量の要素を選択したいときは dataset.iloc[i,:],j 番目の特徴量におけるすべてのサンプルの要素を選択したいときは dataset.iloc[:,j] とします.複数の要素を指定する方法は, index,columns の方法と同じです.次の 6 つのセルを実行することで結果を確認しましょう.
あやめのデータセットにおける 0 番目の特徴量の中身は,あやめの種類 setosa, versicolor,virginica を表す文字列です.機械学習では,このようなカテゴリーを表す文字列を 0,1 のみで表される変数(ダミー変数)として扱うことがあります.あやめの種類は setosa,versicolor,virginica それぞれに対応する 3 つのダミー変数で表され,たとえば setosa のサンプルでは,setosa に対応するダミー変数だけ1 となり,それ以外の 2 つのダミー変数は 0 になります.
カテゴリー変数をダミー変数に変換するには,pd.get_dummies( ) を使います.( ) 内に変換したい変数を入力して実行します.dummy_dataset = pd.get_dummies (dataset.iloc[:,0]) と記述されたセルを実行することで,あやめのデータセットにおける Species をダミー変数に変換してから dummy_dataset という変数に代入します.dummy_dataset とあるセルを実行することで中身を表示し,カテゴリー変数が 0,1 で表現されたことを確認しましょう.
3.3 データセットの保存
DataFrame 型の変数では,変数名.to_csv( ) とすることで,変数の中身をデータ セ ッ ト の サ ン プ ル の 名 前 や 特 徴 量 の 名 前 と 一 緒 に 保 存 で き ま す.dummy_ dataset.to_csv(ʻspecies_dummy.csvʼ) と書かれたセルを実行することで,ダミー変数に変換したデータセットを,species_dummy.csv という名前の csv ファイルに保存しましょう.そのあとに csv ファイルを Excel などで開き,3.2 節で表示したダミー変数のデータセットと同じようなデータセットが保存されていることを確認しましょう.
サンプル Notebook には,【参考】として DataFrame 型の変数を横につなげる方法に関する解説があります.よく読みながらサンプル Notebook を実行しましょう.
本章で学習した内容を確認するため,仮想的な装置のデータセット(virtual_ equipment.csv)を用いた練習問題がサンプル Notebook にあります.ぜひトライしてみましょう.
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。