
回帰モデルやクラス分類モデルにおけるハイパーパラメータを最適化するため、scikit-learn の GridSearchCV を使用する人がいらっしゃると思います。特に複数の種類のハイパーパラメータがあるとき、GridSearchCV を使えば 1 行でクロスバリデーションとグリッドサーチをしてくれて、とても便利です。ただ、特にサンプル数が小さいとき、GridSearchCV でハイパーパラメータを選択した後にモデルを構築し、テストデータを予測したら悪い結果になってしまった人もいるのではないでしょうか。例えば回帰分析のテストデータの予測結果においてこんな感じです↓
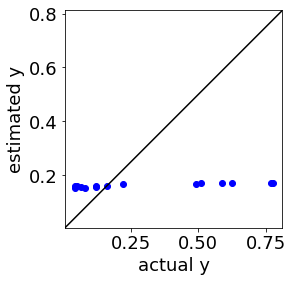
このようなハイパーパラメータの最適化に失敗してしまったとき、GridSearchCV の設定や GridSearchCV そのものに原因があるかもしれません。今回は GridSearchCV 関係の原因とその対処法についてお話しします。
原因1:GridSearchCV の cv に数値を入力しただけではサンプルがシャッフルされない
GridSearchCV で例えば 5-fold クロスバリデーションをするとき、パラメータの cv を 5 とする (cv=5 とする) と思います。もちろんこれで 5-fold クロスバリデーションをしてくれるのですが、5つのグループ (fold) に分割するとき、ランダムに分割するわけではありません。サンプルを上から順番に 5 分割します。例えば、目的変数の値の大きい順、もしくは小さい順にサンプルを並べていたり、測定時刻や測定日など何か規則性をもってデータセットのサンプルを並べていたりすると、シャッフルされず偏りのある結果になってしまいます。もっとも、train_test_split でトレーニングデータとテストデータにランダムに分けてから、トレーニングデータでハイパーパラメータを最適化するときであれば、すでにトレーニングデータ内でサンプルがシャッフルされていますので、GridSearchCV においてトレーニングデータを上から順番に分けても問題ありません。ただ、テストデータで各解析手法を評価した後に、全サンプルでモデルを (改めて) 構築するときに、シャッフルしないまま cv=5 として GridSearchCV を使用してしまうと、シャッフルされないクロスバリデーションになってしまいます。
原因1の対処法:KFold や StratifiedKFold で cv を設定する
対処法としては、事前に回帰分析でしたら KFold で、クラス分類でしたら StratifiedKFold で、cv を設定しておきます。5-fold クロスバリデーションをしたいとき、例えば回帰分析ではこんな感じです↓
from sklearn.model_selection import KFold cv_shuffle = KFold(n_splits=5, shuffle=True)
クラス分類ではこんな感じです↓
from sklearn.model_selection import StratifiedKFold cv_shuffle = StratifiedKFold(n_splits=5, shuffle=True)
そして、GridSearchCV で cv=cv_shuffle とすれば、クロスバリデーションのときにランダムに分割してくれます。なお、KFold や StratifiedKFold のパラメータで random_state を設定しておけば、ランダムとはいえ再現性を担保できます。
原因2:GridSearchCV ではクロスバリデーションの fold ごとに r2 や正解率などを計算して、それらの平均値を指標にしているため、サンプル数が小さいとき不安定
GridSearchCV におけるクロスバリデーションでは、例えば 5-fold では 5 つに分割したあとに、4 つの fold でモデルを構築し、残りの fold を予測し、この fold のみで r2 や正解率などを計算します。そして最後に、5 つの r2 や正解率を平均して、評価値としています。この評価値が最も高いハイパーパラメータを選択します (best_params_ にしています)。ベストバランスにしていますサンプル数がある程度大きく、分割数をある程度小さくしているときには問題にならないのですが、例えば 10 サンプルしかないときに、10-fold クロスバリデーションをしてしまうと、(最後に平均するとはいえ) 1 サンプルで r2 や正解率を計算するという、おかしなことになります。これで評価値が不安定になり、適切にハイパーパラメータの評価ができなくなってしまいます。
原因2の (根本的ではない) 対処法:分割数を小さくする (さらに下に、GridSearchCV を使わない根本的な対処法も示します!)
対処法としては、分割数を小さくします。例えば分割数を 2 にすれば、10 サンプルでも 5 サンプルで r2 や正解率を計算するようになりますので、1サンプルよりは安定して評価値を計算できます。
ただこれは、根本的な対処法ではありません。サンプルが少ないときは、5 サンプルでモデル構築をすることになりますので、(10-fold のときの) 9 サンプルでモデルを構築する場合と比べても、モデルの安定性は低下してしまいます。やはり、10-fold クロスバリデーションを用いて、9 サンプルでモデルを構築して 1 サンプルを予測することを 10 回行ったあと、10 個の予測値を統合して一回 r2 や正解率を計算することが望ましいです。しかし GridSearchCV では、このようなクロスバリデーションの評価を行う設定はできません。
GridSearchCV における不安定なクロスバリデーションの評価ではなく、クロスバリデーションの予測値をすべて合わせて一回 r2 や正解率を計算するやり方は、cross_val_predict を用いることでできます。ただ、グリッドサーチの部分は自分で (for 文などを用いて) コードを書かなければいけません。ちなみに、cross_val_predict でも、原因1で指摘したようにクロスバリデーションのときにサンプルがシャッフルされませんので、KFold や StratifiedKFold で cv を設定しましょう。
DCEKit に適切なクロスバリデーション + グリッドサーチの機能を搭載!
そこで、DCEKit にクロスバリデーションで適切に評価値を計算し、グリッドサーチでハイパーパラメータを最適化する機能 DCEGridSearchCV を作りました!この機能は最初の原因1にも対処しております。

クロスバリデーションにおいて各 fold の予測値を統合して一回 r2 や正解率を計算しますし、cv=5 としてもクロスバリデーションにおいてランダムに分割してくれます。
使い方は GridSearchCV と同じです。GridSearchCV を DCEGridSearchCV に置き換えるだけで、原因1も原因2も根本的に解決したクロスバリデーションで評価して、最適なハイパーパラメータ (best_params_) を求めてくれます。
ちなみに before (GridSearchCV) → after (DCEGridSearchCV) で、こんな感じになった結果もあります↓
before (GridSearchCV)
↓
after (DCEGridSearchCV)
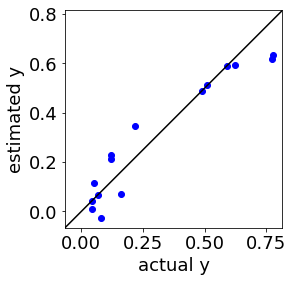
DCEKit にデモンストレーションのプログラム↓もありますので、ぜひ活用していただけますと幸いです。
- demo_DCEGridSearchCV_classification.py
- demo_DCEGridSearchCV_regression.py
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

