データ解析・機械学習を行うためには、データセットが必須です。エクセルファイルや実験ノートなどからデータを集めて、整理してまとめると思います。そのようにしてデータセットを作成するとき、注意することがあります。6つそれぞれ説明します。
1. xlsx ファイルではなく csv ファイルで作成する
エクセルでデータセットをまとめると思います。まとめたあとにファイルを保存するとき、デフォルトのファイル形式は xlsx 形式です。ただデータ解析・機械学習をするとき、このファイル形式ですとエクセルに由来する余計な情報も入ってしまい、扱いにくいです。扱いやすく、データセットの確認・修正もしやすいのは、csv 形式です。たとえばデータセットに不具合があったり余計な文字が入っていたりするとき、テキストエディタで csv ファイルを確認したり、ある文字を全部置換したりすることも簡単にサッとできます。データセットを保存するときは csv ファイルにしましょう。
2. サンプルを縦に、変数 (特徴量) を横に並べる
エクセルでデータセットをまとめるときは、縦の行と横の列をあまり気にしなくてよいと思いますが、たとえば Python でデータセットを扱うときは、基本的にサンプルが縦に、特徴量が横に並んでいることが前提となります。データセットをまとめるときも、その形式のほうが後々扱いやすいです。
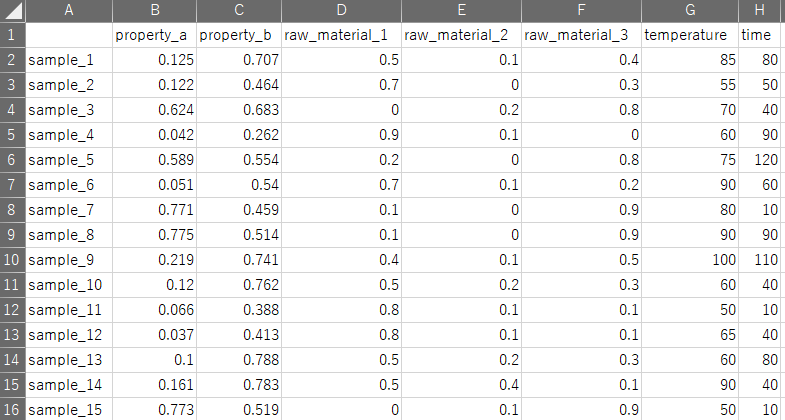
また、サンプルや変数を入れ子構造にしてデータセットをまとめると、非常に扱いにくくなってしまいますので、縦に並ぶのはすべてサンプル、横に並ぶのはすべて特徴量といったように、シンプルに整理しましょう。
3. 文字のデータの特徴量があってもよいが、数値のデータと混同させない
たとえば、ある列はすべて文字の列、というような特徴量があってもよいです。
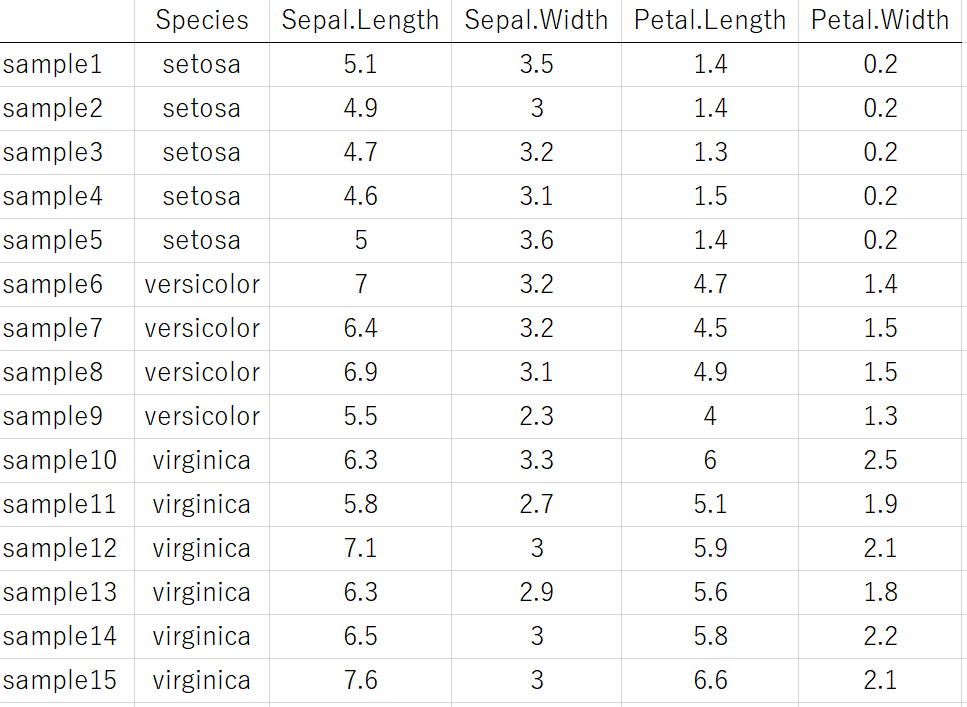
ただ同じ列で、数値のデータと文字のデータを混同させないようにしましょう。たとえば数値+単位とかでデータをまとめていると、一つのセルに数値と文字が混同することになります。これでは、データセットを読み込むときに文字として扱われてしまい、せっかくの数値の情報が無駄になってしまいます。他には、数値の範囲で 0.2 から 0.5 までを表すときに、「0.2-0.5」とか「0.2~0.5」のように 「-」 や 「~」 といった文字が数値と一緒にあると、すべて文字になってしまいもったいないです。このような場合は、最小値を入れる列と、最大値を入れる列の2つの列で整理するとよいと思います。
4. 空のセルがあってもよいが、意味を統一する
データセットをまとめるとき、穴あきでも問題ありません。
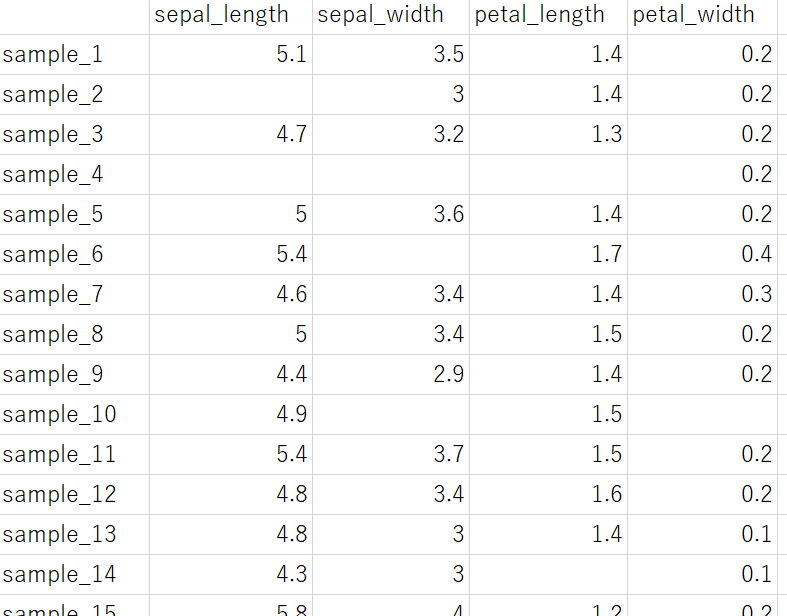
あとで補完できるためです。
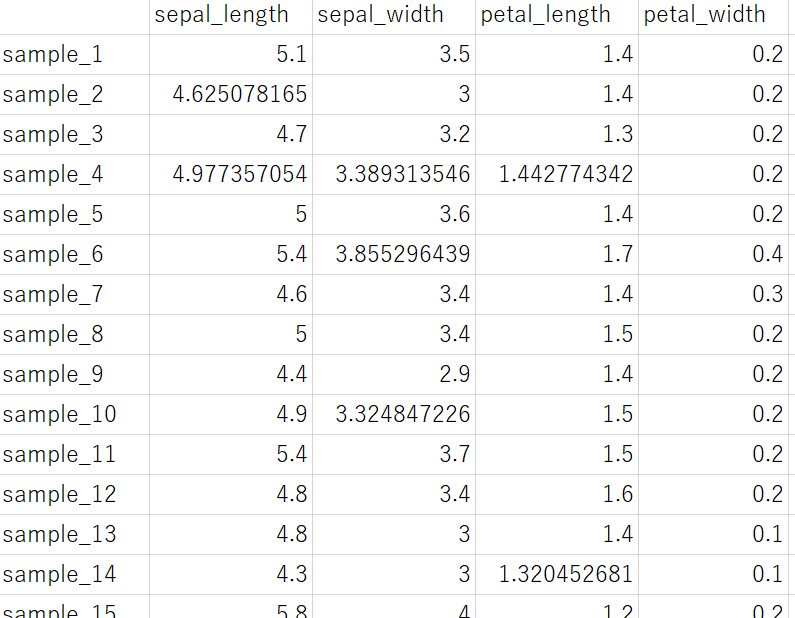

ただ、穴あきのデータセットの「穴(空白)」に対して、「測定されていないサンプル」のように一つの意味だけを用いるようにしましょう。たとえば、測定されていないサンプルも空白に、測定された結果が 0 のサンプルも空白にしてしまうと、データセットを読み込んで空白のときに、測定されていないのか測定値が 0 なのか、どちらの意味なのか分からなくなってしまいます。空白のセルには、一つだけの意味を当てはめることが大事です。
5. サンプル名をすべてのサンプルで異なるものにし、特徴量名をすべての特徴量で異なるものにする
異なるサンプルにもかかわらずサンプル名が同じであったり、異なる特徴量にもかかわらず特徴量名が同じであったりすると、データセットを解析するときに不具合が起きる可能性があります。すべてのサンプルにおいて異なるサンプル名にし、すべての特徴量で異なる特徴量名にしてください。
6. セルを統合しない
エクセルの機能でセルの統合機能があります。データセットをまとめるときに、これを使うとデータの読み込みができなくなってしまいます。サンプル名や特徴量名のところでセルの統合をしても同じことです。すべてのセルは、統合しないで扱うようにしましょう。たとえば、同じ意味合いの特徴量をまとめて、名前のセルを統合して表すことがあるかもしれませんが、統合せず、別々の名前にすうりょうにしましょう。また、時系列データのサンプルにおいて、測定頻度が異なるときに、測定頻度が低い特徴量に対してセルを統合することで表現するのではなく、一番測定頻度の高いデータにサンプルに合わせて、測定されてない時刻は何も書かないなどして整理するとよいです。サンプル名が2列になっても、特徴量名が2行になることはOKです。ただ前述した通り、すべてのサンプルで異なる名前の列が少なくとも一つあったり、すべての特徴量で異なる名前の行が少なくとも一つあったりするようにしてください。
その他、こちらも参考にするとよいと思います。

以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

