今回は、Sparse Generative Topographic Mapping (SGTM) という、GTM のアルゴリズムを改良することで、データの可視化をすると同時に、クラスタリングも一緒に実行できる手法についてです。この手法を開発し、QSPR 解析・QSAR 解析を行った論文が、Journal of Chemical Information and Modeling に掲載されましたので紹介します。

金子研オンラインサロン内ではこの論文を共有しています。ちなみに提案手法を実行できるコードはこちらにあります。
GTM は基本的にデータの可視化手法であり、自己組織化マップ (Self-Organizing Map, SOM) の上位互換の手法としても知られています。詳しくはこちらをご覧ください。
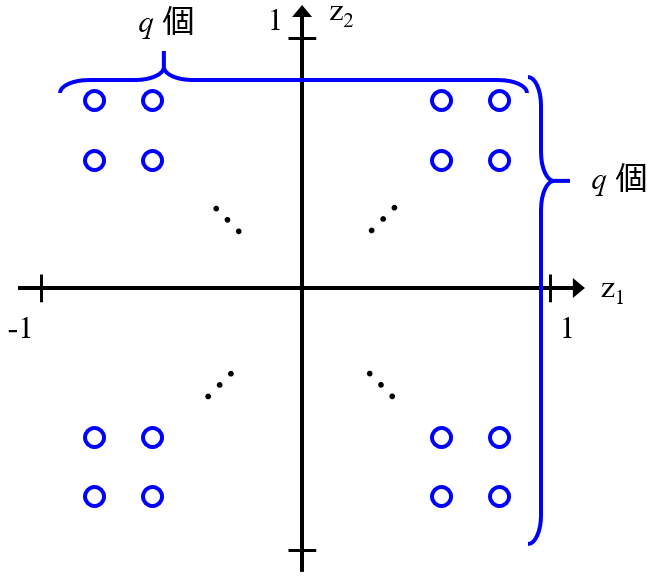
この GTM のアルゴリズムを少し改良して、モデルを sparse にすることで、データの可視化だけでなくクラスタリングも一緒にできてしまうんです。Sparse Generative Topographic Mapping (SGTM) と名付けました。
SGTM を思いついた背景に、GTM が混合ガウスモデル (Gaussian Mixture Model, GMM) と似ていることがあります。GMM についてはこちらをご覧ください。
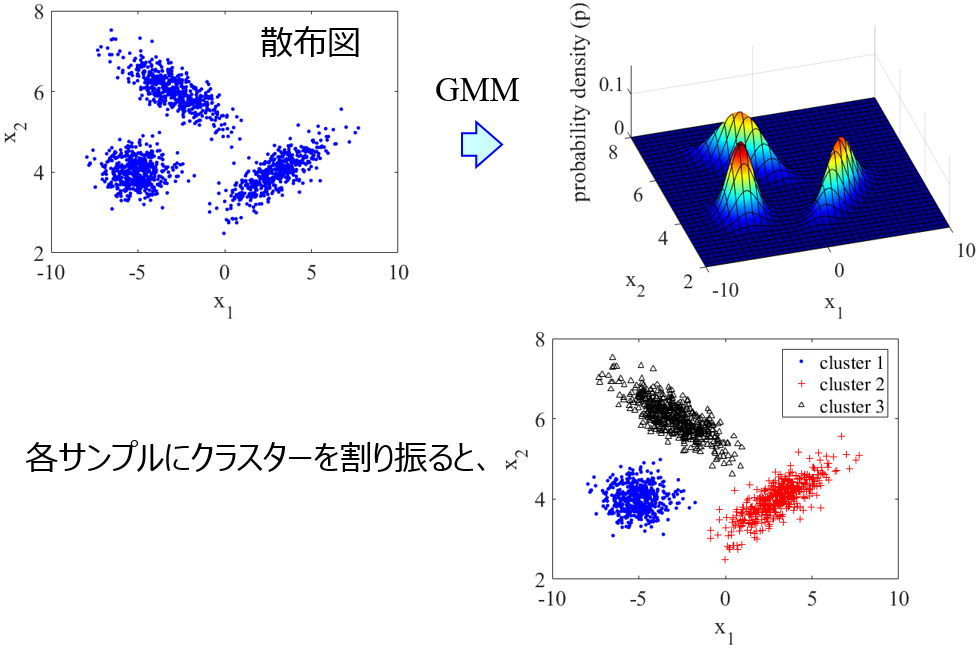
実は GTM は、混合係数 (負担率) πk を 1 / (GTMマップのグリッド数) ですべて同じとし、共分散を 0, 分散をある値に固定した GMM のことなんです。この GMM を低次元 (だいたい二次元) に落とし込んだのが GTM ということです。
GMM はクラスタリングの手法です。これは、混合係数 πk が可変であることに由来します。GTM では混合係数に相当するものを 1 / (マップサイズ)2 に固定していましたので、クラスタリングはできませんでしたが、これを可変にすればクラスタリングもできるだろう、というわけです。そして実際に可変にして、W, β と一緒に Expectation-Maximization (EM) アルゴリズムで πk を最適化する手法を開発しました。
ちなみに、クラスター数も自動できまります。このやり方は、GMM と同じで ベイズ情報量基準 (Bayesian Information Criterion, BIC) を用います。GTM でもデータセットを確率密度関数として表せるので、BIC を使って最適クラスター数を推定できるわけです。
QSPR のデータセットや QSAR のデータセットを解析したところ、データの可視化の性能を表す指標 k3n error の値もほとんど変わることなく、つまり GTM と同様に可視化ができ、さらにクラスタリングも可能であることを確認しました。各サンプルに自動的にクラスターが割り当てられますので、色付きのサンプルとして二次元にプロットされて、とても見やすくなります。具体的な図は論文をご覧ください。
ちなみに、以前に GTM でデータの可視化・回帰分析・モデルの適用範囲・モデルの逆解析を一緒に実行する方法を開発した話をしました。

SGTM はこちらに応用することもできます。つまり、
- データの可視化
- クラスタリング
- 回帰分析
- モデルの適用範囲
- モデルの逆解析
が同時にできるわけです。
興味のある方は、論文をご覧になっていただけると幸いです。金子研オンラインサロン内ではこの論文を共有しています。また DCEKit をインストールしていただければ SGTM を実行できます。ぜひお試しいただければと思います。

以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

