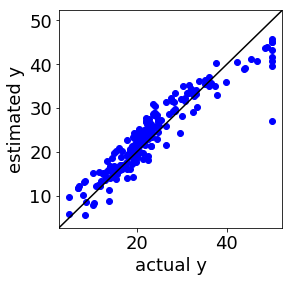
SVR (Support Vector Regression, サポートベクター回帰) で回帰モデルを構築したことのある方は、下の図のように、実測値 vs. 推定値プロットにおいて、対角線から一定に離れたところにサンプルが固まっている、つまり全く同じ誤差のサンプルがある、ことを経験しているのではないでしょうか。
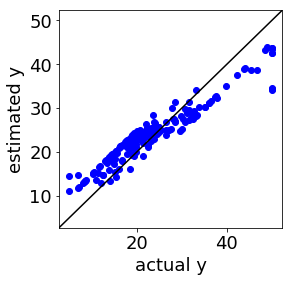
補助線を入れるとこんな感じでしょうか。赤い点線のところに、つまり ε チューブの境界に、サンプルが固まっています。
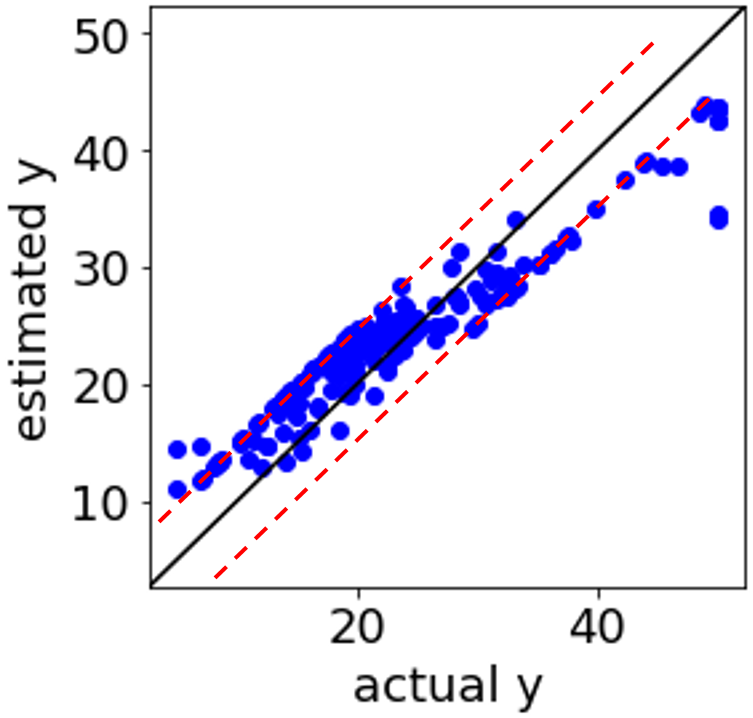
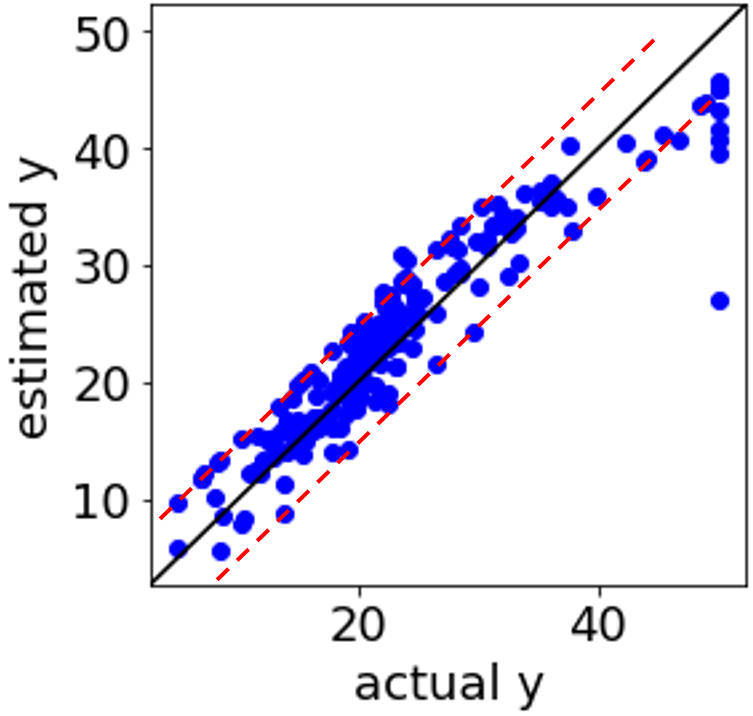
違和感のある実測値 vs. 推定値プロットですので、何か解析方法に問題があるのかと疑ってしまう方もいらっしゃるのではないでしょうか。実はこの現象自体にはまったく問題はありません。
今回は全く同じ誤差のサンプルがある理由を解説します。
SVR に関して、まずこちらをご覧ください。

SVR の式は
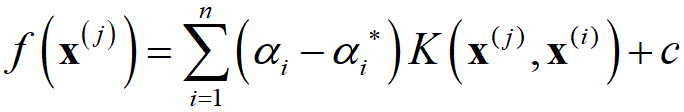
でして、αi, αi* は
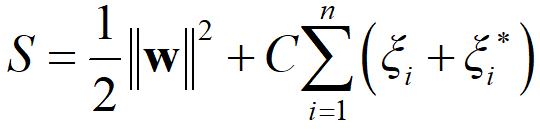
を最小にするようにして、ラグランジュの未定乗数法で最適化されます (他の記号については SVR の解説をご覧ください)。なお、0 ≤ αi, αi* ≤ C です。
αi, αi* の最適化の過程において、ラグランジュ乗数とそれと対応する制約式の積が0 となる条件である、カルーシュ・クーン・タッカー条件 (Karush-Kuhn-Tucker condition, KKT条件) が、以下の式で与えられます。

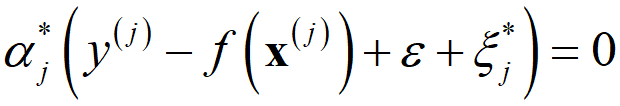
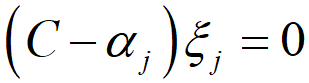

1 つ目の式より、αj が 0 以外の値となるのは、(f(x(j)) + ε + ξj − y(j)) = 0 つまり y(j) = f(x(j)) + ε + ξj となるサンプルのみであり、それらは ε チューブの上側の境界にあるサンプル (ξj = 0) か ε チューブの上側の外にあるサンプル (ξj > 0) です。2 つ目の式より αj* が 0 以外の値となるのは、(y(j) − f(x(j)) + ε + ξj*) = 0 つまり y(j) = f(x(j)) − ε − ξj* となるサンプルのみであり、それらはε チューブの下側の境界にあるサンプル (ξj* = 0) か ε チューブの下側の外にあるサンプル (ξj* > 0) です。
さらに (f(x(j)) + ε + ξj − y(j)) = 0 と (y(j) − f(x(j)) + ε + ξj*) = 0 に着目して両辺の和を取ると、2ε + ξj + ξj* = 0 となり、ε > 0, ξj ≥ 0, ξj* ≥ 0 からこの式は成り立ちません。よって (f(x(j)) + ε + ξj − y(j)) = 0 と (y(j) − f(x(j)) + ε + ξj*) = 0 が同時に成り立つことはないわけです。このことから、すべてのサンプル (y(j), x(j)) において、少なくとも αj = 0 もしくは αj* = 0 となります。
よって、1 つ目の式・2 つ目の式の話と組み合わせると、ε チューブの内側にあるサンプルでは、αj = αj* = 0 となります。このようなサンプルは、一番最初の SVR モデルの式にまったく寄与しません。それ以外のサンプル、つまり ε チューブ上のサンプルもしくはε チューブの外側のサンプルのことをサポートベクターと呼び、SVR モデルの式はサポートベクターのみによって決まります。
0 < αj < C となるサンプル (y(i), x(i)) は、4 つの式の 3 つ目より ξj = 0 です。よって y(i) = f(x(i)) + ε です。これらのサンプルは、誤差がちょうど ε ということです。また、0 < αj* < C を満たすサンプル (y(i), x(i)) は、4 つの式の 4 つ目より ξj* = 0 です。よって y(i) = f(x(i)) − ε です。これらのサンプルは、誤差がちょうど −ε ということです。
つまり、上の図の赤い点線上に固まっているサンプルは、モデル構築における最適化の段階で、0 < αj < C や 0 < αj* < C となったサンプルであり、特に問題はありません。
最後に αj, αj* の値ごとのサンプルの説明を下にまとめます。
- αj = 0, αj* = 0 : ε チューブの内側のサンプル。SVR モデルの式に寄与しない
- 0 < αj < C, αj* = 0 : 上側の ε チューブ上のサンプル。サポートベクター。定数項の計算に使用
- αj = 0, 0 < αj* < C : 下側の ε チューブ上のサンプル。サポートベクター。定数項の計算に使用
- αj = C, αj* = 0 : ε チューブの上側のサンプル。サポートベクター
- αj = 0, αj* = C : ε チューブの下側のサンプル。サポートベクター
よって、SVR の特徴として
- ε チューブの内側のサンプル、つまり誤差が小さいサンプルは、SVR モデルに影響しないため、SVR モデルはノイズの影響を受けにくい
- ε チューブの上側のサンプルやε チューブの下側のサンプル、つまり誤差が大きいサンプルは、どんなに誤差が大きくても、SVR モデルへの影響を C でコントロールできるため、SVR モデルは目的変数の外れ値の影響は受けにくい
があります。
参考文献
C. B. ビショップ, パターン認識と機械学習 下 (ベイズ理論による統計的予測), 丸善出版, 2012
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。