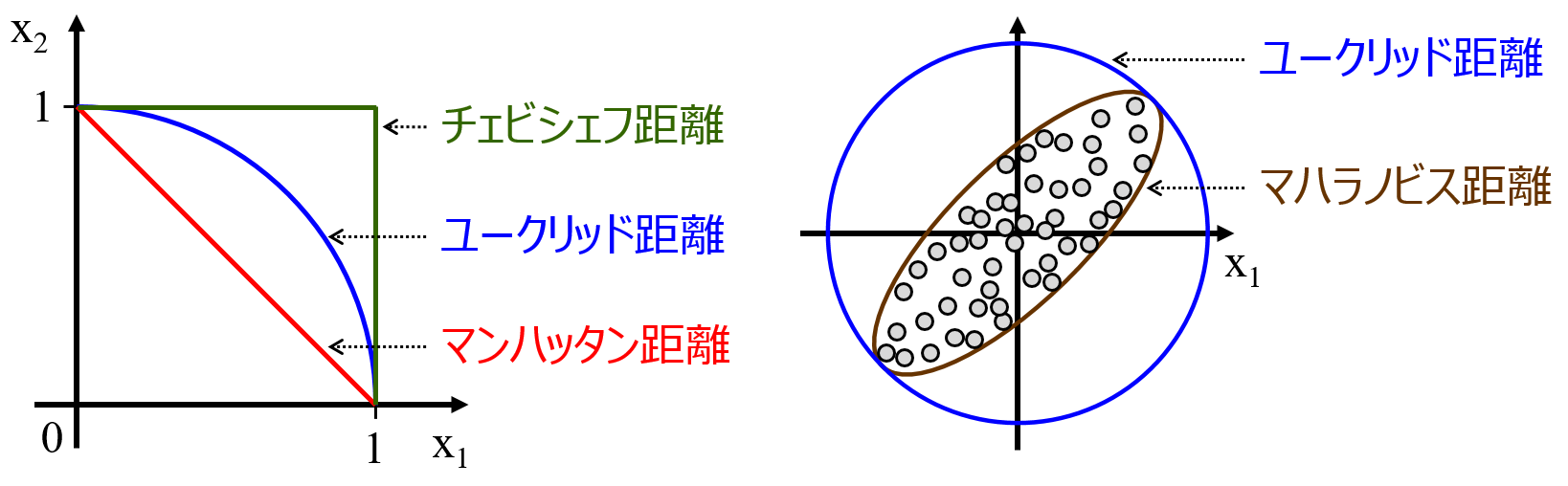
金子研オンラインサロンにおける話題の中から一つ。
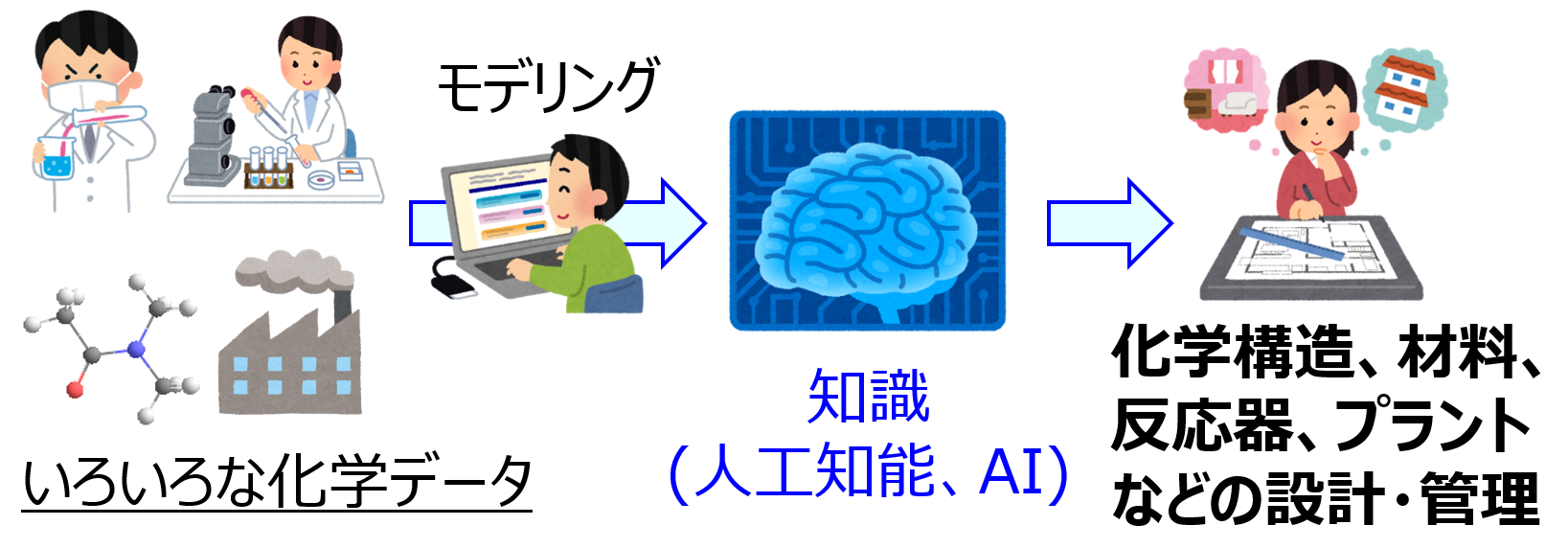
Slack で機械学習によって構築されたモデルの解釈に関する質問があり、わたしが回答しました。
質問や回答の詳細は伏せますが (興味のある方はオンラインサロンにご登録くださいw) モデルの解釈については、興味のある方も多いと思いますので、モデルの解釈に関するわたしの考え方やスタンスについてまとめておきます。
モデルの解釈の方針としては以下のどちらかになると考えています。
- 解釈可能な (シンプルな) モデルを構築し、それを解釈する
- 高精度な (複雑な) モデルを構築し、それを (工夫して) 解釈できるようにする
1. は決定木のようなものです。
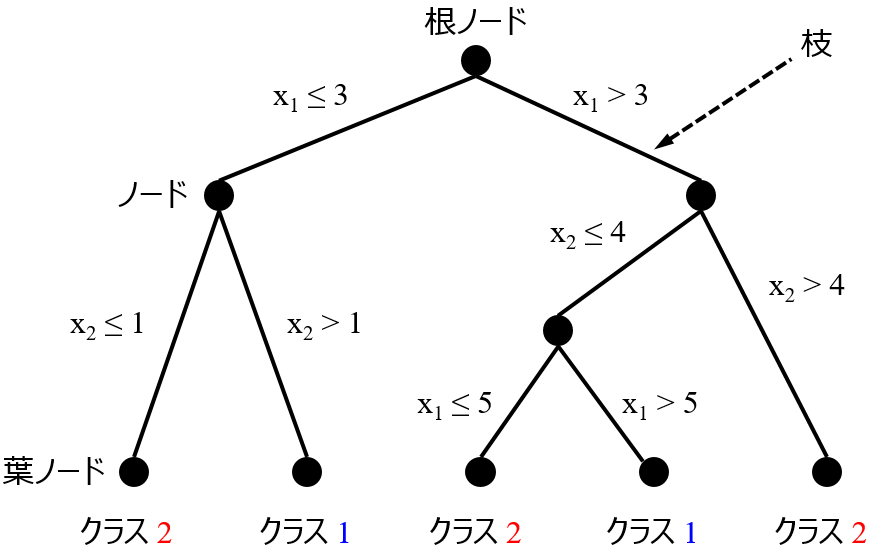
基本的には、モデルの推定性能と解釈可能性とはトレード・オフの関係です。
オーバーフィッティングが起こらないように気をつけながら、モデルを複雑にして推定性能を上げると、モデルの解釈は難しくなります。モデルをシンプルにして解釈可能性を上げると推定性能は下がります。
例えば、決定木によって構築されたモデルは解釈可能な一方で、モデルの推定性能は他の手法で構築されたモデルと比較して高くありません。決定木モデルの数を増やしていくと、アンサンブル学習により推定性能は上がる一方で、そのモデルを解釈することは、すべての決定木モデルを解釈してその内容をまとめることになりますので、解釈は難しくなります。ランダムフォレストや XGBoost のような決定木のアンサンブル学習では、推定性能に特化しており、解釈は難しいわけです。
あるデータセットがあったとき、決定木により十分に推定性能の高いモデルを構築できれば、構築された木を解釈することで問題ないと思います。しかし、決定木のようなシンプルな手法で、いつも推定性能の高いモデルを構築できるわけではありません。もちろん、決定木の推定性能が低くても、構築された木自体の解釈はできます。ただ、推定性能の低いモデルを解釈することに意味はあるのでしょうか。
そのような場合、わたしは、解釈可能とはいえ推定性能の低いモデルを構築するよりも、適当な非線形モデリング手法でもアンサンブル学習でもなんでもよいので、まずは 2. のような推定性能の高い (複雑な) モデルを構築するのがよいと考えています。
もちろん、このモデル自体の解釈は不可能です。ただ、目的変数の値を適切に推定できるモデルであれば、モデルの中に、説明変数と目的変数との間の (複雑な) 非線形関係が、モデルの解釈が難しいだけで、含まれているはずです。
そこで、構築された (複雑な) モデルを、数値実験することで、モデルの解釈を試みてはどうかと考えています。意図的に変化させた X の値をモデルに入力して、y の値が大きくなるのか、小さくなるのか、変わらないのか調べます。あたかもモデルを用いて実験室で “実験” するかのように、モデルにいろいろな数値を入力してその結果出力される値を見ることで、能動的にモデルを調査するわけです。たとえば、ある一つの説明変数の値だけ変えてみたときに、y の値が大きくなるのか、小さくなるのか、変わらないのかをみます。化学構造においては、たとえばある部分構造を変えたり追加したりしたときに、物性や活性はどうなるのか調べるわけです。このような、モデルの数値的な実験をしながら、モデルの解釈を試みます。
1.2. のいずれにしても、まずは推定性能が良好なモデルを構築することが先決です。いいかげんなモデルをいくら解釈しても意味がないわけですから。もちろん、モデルの解釈について諦めているわけではありません。推定精度の高いモデルを構築してから、モデルの解釈を検討する、というスタンスです。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。