応化先生と生田さんが論文 “Discussion on Regression Methods Based on Ensemble Learning and Applicability Domains of Linear Submodels” について話しています。
応化:今日は、Ensemble learning method Considering Applicability Domain of each Submodel (ECADS) についてです。
生田:なんすかそれ?
応化:アンサンブル学習の一つです。アンサンブル学習については以前にやりましたね。

生田:はい。データセットから、サンプルや説明変数を選択してサブデータセットをたくさんつくり、それぞれで回帰分析やクラス分類してサブモデルを構築して、推定するときにはサブモデルの推定値を平均したり多数決したりするんですよね。
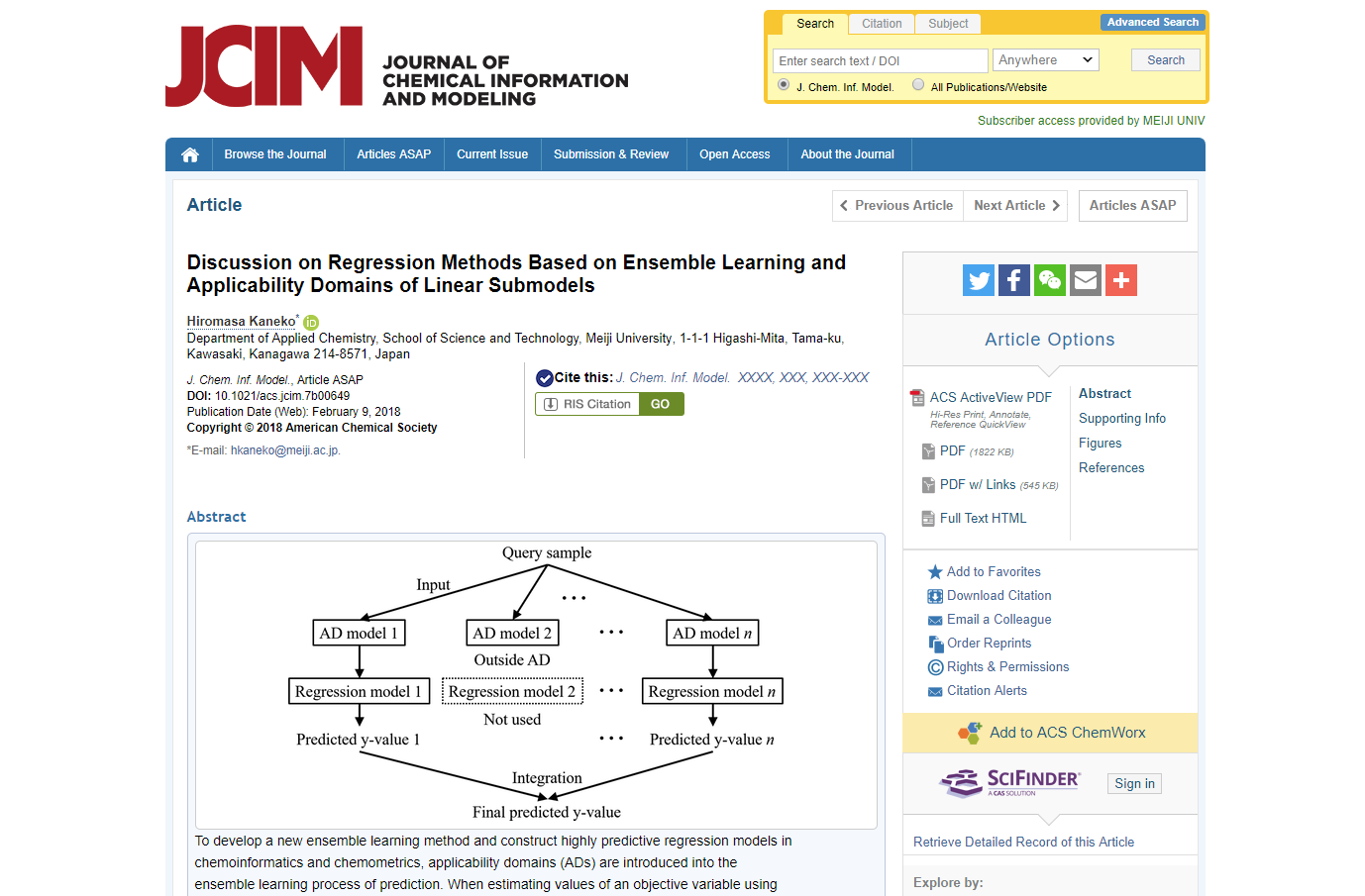
応化:その通りです。ECADSは、サブモデルそれぞれのモデルの適用範囲・適用範囲 (Applicability Domain, AD) を考慮して推定する方法です。ADについてはこちらをご覧ください。

生田:ADって、回帰モデル・クラス分類モデルが本来の推定性能を発揮できるデータ領域のことですよね。
応化:はい、そうです。
生田:アンサンブル学習のお話しのとき、メリットの一つに “3. 推定値の不確かさ (モデルの適用範囲・適用領域) を考慮できる。” がありました。サブモデルから得られた複数の推定値のばらつきによって、ADを考慮できるというものでした。これと違うのですか?
応化:違います。ECADSでは、各サブモデルのADを考えます。
生田:100のサブデータセットがあり、それによって100のサブモデルがあるときは、サブモデルごとにADがあるので100のADがあるってこと?
応化:そういうことです。
生田:今回はサンプルを選んでサブデータセットを作ったんですか?説明変数を選んでサブデータセットを作ったんですか?
応化:説明変数を選んで作りました。サンプルを選んでサブデータセットを作ると、サンプルが減るので各サブモデルのADは単純に小さくなるだけですが、説明変数を選ぶことで、サンプルが同じでも異なるADを作れます。
生田:100のサブモデルがあったら、異なる100のADってこと?
応化:その通りです。新しいサンプルの推定をするとき、各ADで100のサブモデルのどれがAD内でどれがAD外か判定します。AD内と判定されたモデルのみ用います。
生田:30個のサブモデルしかAD内でなければ、それらのサブモデルから計算された30個の推定値だけで平均値・中央値を計算するってこと?
応化:その通りです。70個のAD外のサブモデルを使ってしまうことを防げるので、推定性能が上がるわけです。
生田:推定性能が上がるのはいいですが、100個ともAD外のサブモデルだったら、推定できないわけですよね。推定できるサンプルが少なくなりませんか?
応化:いえ、逆に、推定できるサンプルは多くなるのです。ADが広くなります。
生田:どういうことですか?
応化:今回の手法では、推定したいサンプルごとに用いるサブモデルは異なりますが、全体のADは、100のADの和集合になります。この和集合の方が、全サンプルを用いて作られた1つのADより広いということです。
生田:なるほど!
応化:ECADSにより既存の手法より推定精度が上がることやADが広がることは、水溶解度データをもつ化合物や毒性データをもつ化合物の解析により確認されています。
生田:わかりました!アンサンブル学習するときに利用してみます!
応化:ECADSの詳細はこちらの論文にあります。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。
