「Pythonで気軽に化学・化学工学」 をご購入いただき感謝申し上げます。売れ行きも好調のようで嬉しい限りでございます。データを持っていたり、収集する予定だったりする多くの方が、プログラミングが未経験でもデータ解析・機械学習をできるようになっていただきたいという思いで執筆した本であり、たくさんの方に本書を手にとっていただけますと幸いです。
そんな中、出版社経由や金子研オンラインサロンにおいて、すでにお読みいただいた方々から、ご質問やご指摘をいただいております。感謝申し上げます。そこでいただいたご指摘から、間違えがあることもわかりましたので、正誤リストとして以下にまとめます。申し訳ございませんが、よろしくお願いいたします。もちろん、間違いについては重版がかかるごとに修正してまいりますし、GitHub のサンプルプログラム https://github.com/hkaneko1985/python_chem_chem_eng は修正後の最新版になっております。
p.34 下から 1,2 行目
(誤) どちらかの特徴量を削除するかに関して、他の特徴量との相関係数の絶対値の総和が小さいほうとします
(正) どちらかの特徴量を削除するかに関して、他の特徴量との相関係数の絶対値の総和が大きいほうとします
p.71 上から 12-14 行目
(誤) 推定結果の r2 を metrics.mean_absolute_error(y_train, estimated_y_train) と書かれたセルを実行することでトレーニングデータにおける推定結果の r2 を計算し,表示できます。
(正) 推定結果の r2 を,metrics.mean_absolute_error(y_train, estimated_y_train) と書かれたセルを実行することでトレーニングデータにおける推定結果の MAE を計算し,表示できます。
p.79 (上から 4 行目)
(誤) p1 における i 番目の x に対応する値 p1(i) は x1 の誤差の二乗和が
(正) p1 における i 番目の x に対応する値 p1(i) は xi の誤差の二乗和が
p.92 式(8.45)
(誤)
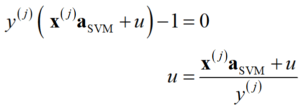
(正)
p.143 下から 2, 3 行目
(誤) 外れサンプルの割合は,ν 以上にはなりません.
(正) 外れサンプルの割合は,ν 以下にはなりません.
p.157 上から 18 行目
(誤) ② 特徴量を標準化したあとに D 最適基準を計算
(正) ② D 最適基準を計算 (特徴量の標準化は最初に一度実施)
p.163 下から 5 行目
(誤) Anaconda Prompt もしくはターミナルにて,”conda install -y-c rdkit rdkit” と
(正) Anaconda Prompt もしくはターミナルにて,”conda install -y -c rdkit rdkit” と
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。