分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y = f(x) を構築し、構築したモデルに x の値を入力して y の値を予測したり、y が目標値となる x の値を設計したりします。
データセットの低次元化、可視化、クラスタリング、モデルの適用範囲の設定などはいわゆる教師なし学習であり、

それを実施する時には、回帰分析やクラス分類の y のような正解はありません。各手法を実行して、その結果を活用したり、人が結果を解釈したりすることになります。そのため、例えばデータセットの可視化をする時にどの手法を用いるのが最適か、クラスタリングをする時にクラスター数はいくつが最適かといったことを自動的に決めるのは困難です。
適した手法やそのハイパーパラメータは、試行錯誤しながら、基本的には結果に基づいて解析者が判断することになります。ただ、教師なし学習を、教師あり学習と組み合わせることができれば、すなわち y を活用したり、準備したりすることができれば、それらの最適化は可能です。例えば、データセットを可視化する最適な手法を決めたい時には、様々な手法でデータを二次元に低次元化した後、その二次元のパラメータと y との間で回帰分析やクラス分類をして、そのモデルの予測性能が最も良好となる可視化手法として、可視化手法を選択します。これにより、y をなるべく説明可能な二次元のパラメータを計算できる、可視化手法を選択できます。
クラスタリングとクラス分類を組み合わせてクラスター数を最適化することもできます。
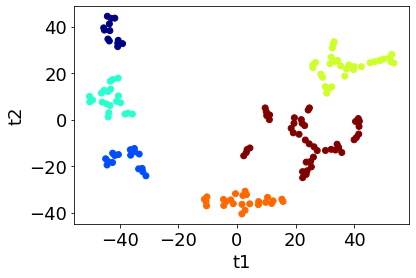
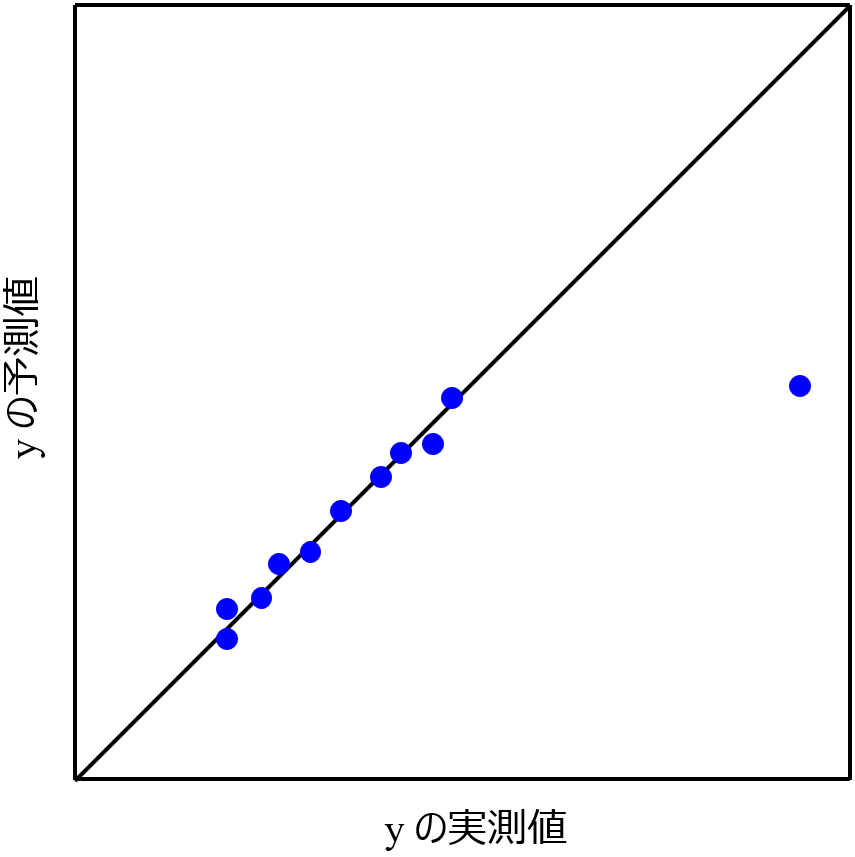
回帰分析により、クラスター数の最適化を含めたクラスタリングをすることもできます。
モデルの適用範囲の手法やそのハイパーパラメータを回帰分析と組み合わせて最適化することもできます。

これらの例のように、回帰分析やクラス分類など教師あり学習を使用できる状況であれば、それをうまく活用して教師なし学習の手法やそのハイパーパラメータを適切に決めると良いでしょう。
以上です。これらの特徴や注意点を踏まえて、是非メタヒューリスティクスを活用していただければと思います。
以上です。
質問やコメントなどありましたら、X, facebook, メールなどでご連絡いただけるとうれしいです。