目的変数が複数あるときの、Gaussian Mixture Regression による直接的なモデルの逆解析、材料設計![金子研論文] 金子研の論文が Materials & Design に掲載されましたので、ご紹介します。タイトルはDirect inverse analysis based on Gaussian mixture regression for multi... 2020.09.27 ケモインフォマティクスケモメトリックスデータ解析研究室論文
「線形代数キャンパス・ゼミ」 機械学習の線形の手法を理解するための線形代数を学びたい方へ 馬場敬之, 「線形代数キャンパス・ゼミ」, マセマ出版社, 2023 (改訂11)マセマ出版社: Amazon: 線形代数についてわかりやすく学べる本です。たとえば以前に紹介した 「マンガでわかる線形代数」 を読んだ後に、さらに学びたい方に... 2020.09.20 データ解析研究室
新たな3D-QSARを開発しました![金子研論文] 金子研の論文が Molecular Informatics に掲載されましたので、ご紹介します。タイトルはTwo‐ and three‐dimensional quantitative structure‐activity relation... 2020.09.20 ケモインフォマティクスデータ解析研究室論文
「マンガでわかる線形代数」 ベクトルって何?行列って何?から、線形代数の基礎を学びたい方へ 高橋 信, 「マンガでわかる線形代数」, オーム社, 2008オーム社: Amazon: タイトルにある通り、マンガでわかりやすいです。「マンガで・・・」 と書いてあると内容が薄そうに感じられるかもしれません。もちろん、いわゆる線形代数の専... 2020.09.13 データ解析研究室
モデルの予測精度を上げるための考え方・方針 目的変数 Y と説明変数 X との間で、回帰分析やクラス分類を行い、モデル Y = f(X) を構築します。もちろん予測精度の高いモデルが望ましいですので、モデルの予測精度を上げるために、いろいろと工夫をします。その工夫の方針は、以下の 5... 2020.09.13 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
データ解析・機械学習における、よくある誤解 4 選 共同研究やコンサルティングなどで、いろいろな方々とお話していると、データ解析・機械学習に関連した誤解があることに気づきます。確かに、一見妥当そうな内容ですので、誤解するのは仕方ないと思いますし、実際、中にはわたしも昔に同じことを考えており、... 2020.09.06 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
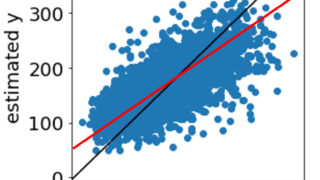
目的変数の実測値vs.予測値プロットが横になってしまう(寝てしまう)ときは非線形手法を検討しよう データセットを用いて、目的変数 Y と説明変数 X との間で回帰モデル Y = f(X) を構築し、そのモデルに X の値を入力することで Y の値を予測することがあります。その予測結果を、下の図のような Y の実測値 vs. 予測値のプロ... 2020.09.06 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
回帰分析からクラス分類に変換したり、クラス分類から回帰分析に変換したりするメリット・デメリット 説明変数 X と目的変数 Y との間でモデル Y = f(X) を構築することがあります。Y が連続値の変数のときは回帰分析、Y がカテゴリー変数のときはクラス分類です。回帰分析、つまり Y が連続値の変数のとき、Y をカテゴリーの情報にす... 2020.08.30 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
材料設計の限界(モデルの逆解析の限界)は分かるのか? 材料設計において、材料の物性 Y と実験条件 X との間で回帰モデル Y = f(X) を構築し、そのモデルに基づいて Y が望ましい値であったり、目標の値であったり、目標の範囲に入ったりするような X の値の提案を行います。いわゆるモデル... 2020.08.23 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
ガウス過程による潜在変数モデル(Gaussian Process Latent Variable Model, GPLVM)で非線形性を考慮した潜在変数を計算しよう! ガウス過程による教師なし学習である Gaussian Process Latent Variable Model (GPLVM) について、pdfとパワーポイントの資料を作成しました。infinite Warped Mixture Mode... 2020.08.23 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室