
分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y = f(x) を構築し、構築したモデルに x の値を入力して y の値を予測したり、y が目標値となる x の値を設計したりします。
物性や活性が発現するメカニズムを解明するため、構築された回帰モデルを解釈し、y と x の間の関係を明らかにすることも重要である。SHAP や LIME では、あるサンプル点におけるモデルの形状の近似式を求めることで、そのサンプル点回りにおける y に対する x の寄与度の大きさを求めます。LOMPはモデルを用いたシミュレーションに基づいて局所的に y に対する x の寄与を計算されます。
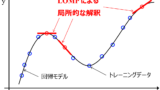
LOMPにより、y に対する局所的な x の寄与もしくは方向性を議論するために使用できます。例えば y が最大値を持つサンプルに対して、さらに値を向上させる x の方向を議論できます。
一方で、データセット全体におけるモデルの解釈をするため、変数重要度もしくは特徴量重要度が大いに役立ちます。Cross-Validated Permutation Feature Importance (CVPFI) を用いることで任意の回帰分析手法において特徴量重要度を計算できます。
CVPFI では、モデル構築と特徴量の評価をクロスバリデーションに基づいて繰り返し行うため、安定して適切な特徴量重要度を計算できます。さらに、x の相関関係に基づいて、評価の対象の特徴量以外の特徴量の値も変えるため、強い相関関係がある x でも独立した x と同様に適切に特徴量重要度を評価できます。
CVPFI により、x の相関関係を考慮した上で安定的に特徴量重要度を計算できますが、特徴量が多いとき、それに応じて重要度の値も多くなり、x と y の関係や y の発現メカニズムを検討することが困難になります。x の相関関係を考慮することで、多くの特徴量で有意な重要度の値が割り振られ、それ自体は妥当なことですが、モデルの解釈はしにくいといえます。
特徴量が多いときのモデルの解釈を考える前に、そもそも、ある特徴量の重要性は以下の三つを考えるとよいです。
- y を説明する情報をもつ
- 他の特徴量では表現できない
- 他の特徴量を説明する情報をもつ
そこで CVPFI に加えて、特徴量間の類似度を用いてモデルの解釈について議論することをオススメします。CVPFI の値が大きく、互いに類似している特徴量は、同様のモデルの解釈ができます。一方で、CVPFI の値がある程度しか大きくなくても、類似した特徴量がない場合は、y に対して不可欠な情報をもっていると考えられます。特徴量間の類似度として、例えば他の特徴量との間の相関係数の絶対値の最大値が挙げられます。
横軸を CVPFI、縦軸を特徴量間の類似度として特徴量をプロットしたとき、CVPFI が大きく類似度が小さい領域、すなわち右下の領域に位置する特徴量から解釈することが効果的です。
さらに、類似した特徴量同士は、こちらのように整理するとよいでしょう。
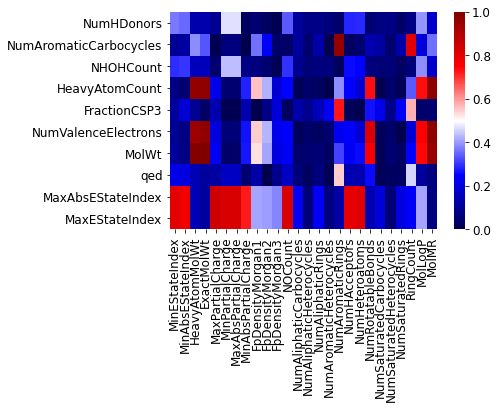
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

