
モデルの逆解析 (Inverse Analysis) について、

ベイズ最適化 (Bayesian Optimization, BO) と一緒にお話しいたします。
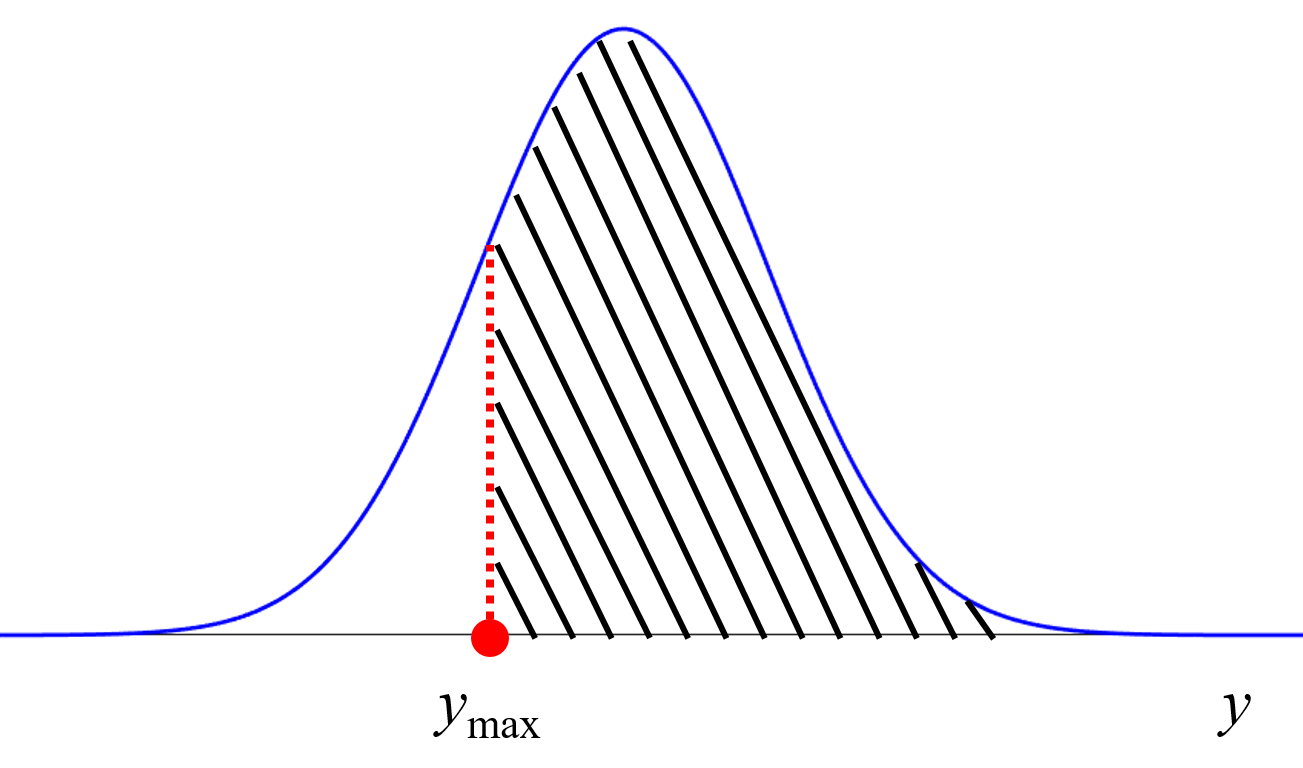
データセットがあるとき、いろいろな回帰手法を検討して、推定精度の最も高い回帰モデルを選びます。そのモデルの適用範囲 (Applicability Domain, AD) を設定してから、

モデルを使用します。つまり、AD 内の説明変数 x の値をモデルに入力し、目的変数 y の値を推定します。
たとえばモデルの逆解析では、y の値が目標の範囲内になるような、x の値の組み合わせを獲得しようとします。モデルの逆解析を達成するための、一つのやり方として、順解析を繰り返す方法があります。x の値の組み合わせの候補を多数準備して、それらをモデルに入力して y の値を推定し、AD と一緒に y の推定値を議論します。
議論の仕方の一つは、AD 的に信頼度の高い順に、y の推定値が目標範囲に入る x の候補を選択することであり (一般的なモデルの逆解析)、もう一つがベイズ最適化 (Bayesian Optimization, BO) です。BO でも一般的なモデルの逆解析と同じで、AD を考慮して x の候補を選択します。ただし、AD 外の x の候補が選択されることもあります。
x の値をモデルに入力して y の値が推定されたとき、たとえ x の値が AD 内でも、y の推定値はあくまで “推定” された値なので、実際の値を検証する必要があります。たとえば x が何らかの実験条件であり、y が実験の結果であるとき、x の値で実験して、その結果としての y の値を検証します。
BO で前提としているのは、そのような実験 (実際の y の値を検証すること) を繰り返し行うことです。ある x と y のデータセットがあったときに、BO で y の値が目標を達成する可能性がもっとも高い x の値の候補を選択し (BO の獲得関数によって、いろいろな選び方があります)、y の値を検証して目標を達成できなかったら、その新たな x と y の組をデータセットに追加して、再度 BO により x の値の候補を選択し、といったことを繰り返します。
この繰り返し回数が、BO では一般的なモデルの逆解析と比べて小さくなります。そのため、たとえば繰り返し実験をする回数を減らしたく、そのような実験が可能な環境があるのであれば、BO を使うのがよいと思います。
ただし、そのような目的ではないとき、一般的なモデルの逆解析で攻めるか、BO をするかは判断が分かれるところです。データ解析の目的やモデルを用いた何らかの設計でやりたいことと、モデルの逆解析で可能なことや BO における各獲得関数の目的を考慮して、決めるとよいでしょう。
構築されたモデルを詳細に解析しながら x の設計をしたいとき、たとえば x の値をいろいろと変化させてモデルに入力し、y の推定値がどう変わるかを検証して、モデルの x に対する感度も確認しながら x の設計をしたいときは、BO ではなく y の推定値を使ったモデルの逆解析のほうがよいです。BO では獲得関数により、y の推定値が確率や期待値のような値になってしまうため、x の値を変化させたときの y の推定値の変化は追えません。
回帰モデルの推定性能も考慮したほうがよいですね。BO では基本的に回帰モデル構築手法はガウス過程回帰 (Gaussian Process Regression, GPR) になります。
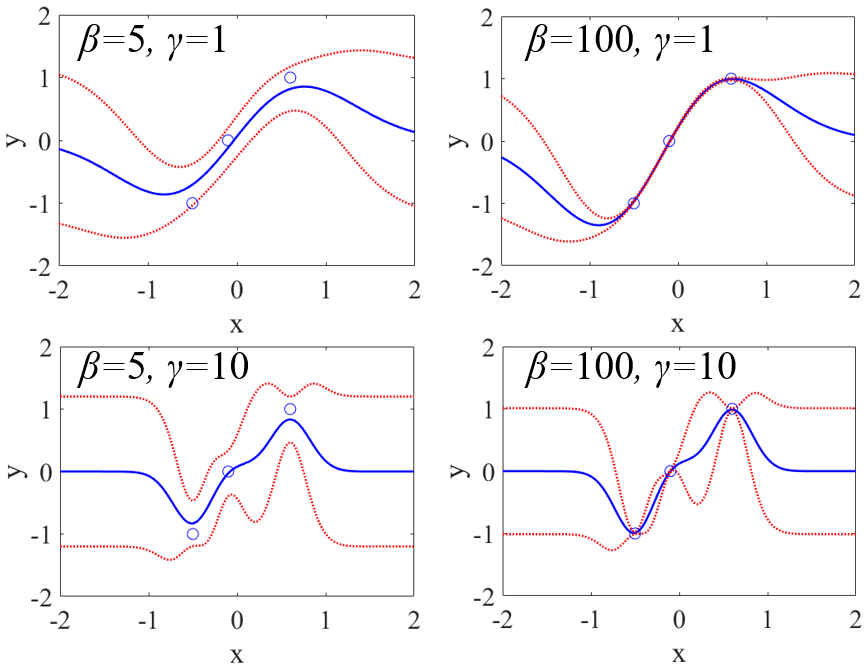
GPR でいくらカーネルを設計しても、

他の回帰分析手法と比べて、推定性能の低いモデルしか構築できないとき、BO ではなく GPR 以外の回帰分析手法を用いた一般的なモデルの逆解析のほうがよい可能性があります。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

