
金子研の論文が Chemometrics and Intelligent Laboratory Systems に掲載されましたので、ご紹介します。タイトルは
Clustering method for the construction of machine learning model with high predictive ability
です。
はじめに断っておきますが、この手法はモデルの逆解析専用の手法です。モデルの順解析、すなわち x から y の予測はできません。それでも、もし興味がございましたら、以下をお読みください。
分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y = f(x) を構築します。構築したモデルに x の値を入力して y の値を予測したり、y が目標値となる x の値を設計したりします。後者はモデルの逆解析で、今回の論文で対象にします。
予測精度の高いモデルを構築するため、様々な回帰分析手法が検討されたり、y を説明するための x が設計されたりしています。ただ一方で、例えば特徴量エンジニアリングをしたとしても、y を説明するためのすべての情報が x に含まれるわけではありません。y を説明するための情報が x に不足しているとき、どんな回帰分析手法やクラス分類手法を用いても、予測精度の高いモデルを構築することはできません。下の図は、同じデータセット内に x (図におけるx1) と y の関係が異なるサンプルが存在する例です。
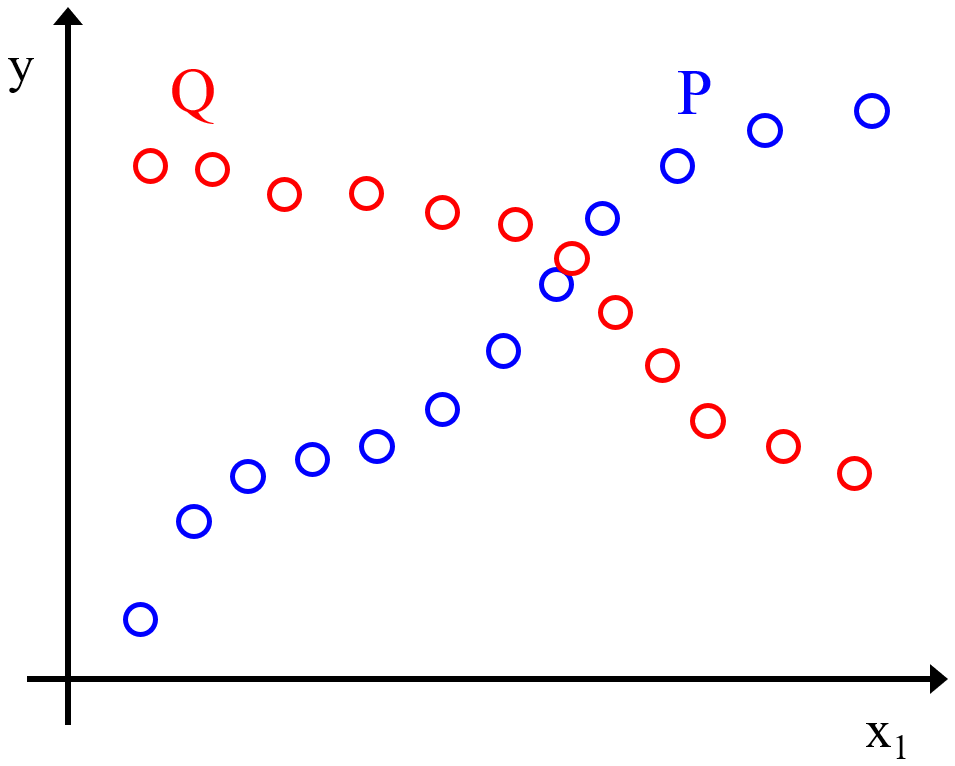
図のサンプルでは、x1 と y の関係が一貫していないため、予測的なモデルを構築することができません。例えば、x1 がある値のときに y の値が複数存在し、x1 から y を的確には予測できません。
もちろん、データセットの物理的・化学的背景を用いた特徴量エンジニアリングにより、図の x1 に新たな特徴量 x2, x3, … を追加して、x と y との関係が一貫するようにすることが最も良い解決策の一つです。しかし、データセット (材料や実験系) によっては、必ずしも x2, x3, … が見つかるとは限りません。
本研究では、上図のような状況において、新たな x2, x3, … を追加できないときに、クラスタリングした後にクラスターごとに機械学習モデルを構築することに着目します。図の P のサンプル郡、Q のサンプル郡それぞれでモデルを構築すれば、新たな特徴量を追加しなくても、x1, y の一貫した関係をモデル化できます。
クラスターごとのモデルが存在することは、新しいサンプルにおいて x から y を予測するときにどのクラスターのモデルで予測するか選択する必要があることを意味します。上図のように、クラスターごとに x と y の関係が異なることから、新しいサンプルにおける x と y の関係が分かっていないと、モデルを選択することはできません。そのため、y の値が不明なサンプルに対して、適切なクラスターを選択することはできません。
本研究では、新しいサンプルにおける x から y の予測を対象としません (x から y を予測しません)。では何を対象にするかというと、y から x の予測です。提案手法は、分子設計、材料設計、プロセス設計で使用することを想定して、モデルの逆解析、すなわち y から x の予測のみを対象とします。モデルを逆解析することを目的とすると、すべてのクラスターのモデルを用いて、y の目標値からモデルごとに x を予測します。クラスターの数、すなわちモデルの数だけ x を提案することになります。これらの x の候補をすべて実験することで、そのなかに y の目標値を達成する候補が出てきます。
本研究では、モデルの逆解析を志向して、クラスターごとに予測精度の高いモデルが構築できるクラスタリング手法を提案しました。もちろん各サンプルを精度良く予測できるように、各クラスターおよび各モデルを作り込んでいきます。提案手法の詳細は論文をご覧ください。
分子や材料やスペクトルなどの様々なデータセットを用いて提案手法の検証を行いました。その結果、データセット全体でモデルを構築したときのモデルの予測精度や、既存のクラスタリング手法を用いて得られたクラスターごとにモデルを構築したとこのモデルの予測精度と比較して、提案手法により大幅にモデルの予測精度を向上することを達成しました。
興味のある方は、ぜひ論文をご覧いただければと思います。どうぞよろしくお願いいたします。
以上です。
質問やコメントなどありましたら、X、facebook、メールなどでご連絡いただけるとうれしいです。

