分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と材料の物性・活性・特性や製品の品質などの y との間で、データセットを用いて機械学習により数理モデル y = f(x) を構築します。構築したモデルを用いて、x の値を入力して y の値を予測したり、y の値が目標値となるような x の値を設計したりします。また、モデルを解釈して x と y の関係を議論したり、y が発現するメカニズムを解明しようとしたりすることもあります。もちろん、モデルの解釈は、あくまで「結果的に構築されたモデル」を解釈することになります。
以前に、非線形回帰モデルを局所的に解釈する手法を開発しました。
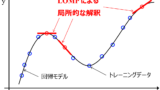
この論文にある Local Slope of Model Prediction (LOMP) を、DCEKit に追加しましたので紹介します。

LOMP により、どんな複雑な非線形モデルでも、局所的な x の寄与の大きさと方向を求めることができます。
DCEKit における以下のデモンストレーションも実行していただければ、LOMP を計算する様子をご覧いただけると思います。
- demo_lomp.py
調整可能なパラメータとして
- n_virtual_samples : LOMP を計算するときに生成する仮想サンプルの数
- rate_max_min : 仮想サンプルを生成する範囲を計算する際の、x の標準偏差の割合
がありますが、基本的にそのままで OK と思います。
非線形の回帰モデルを構築したあとに、あるサンプルの x 周りの LOMP を求めたいとき、そのサンプルの x の周りに、局所的に乱数で仮想的な x のサンプルを n_virtual_samples 個生成します。生成する x の範囲は、対象のサンプルの x ± rate_max_min×(x の標準偏差) です。生成したサンプルを回帰モデルに入力して y を予測します。生成した x と y の予測値との間で、最小二乗法による重回帰分析で線形モデルを構築し、その回帰係数を LOMP とします。なお、たとえ元のデータセットにおいて x の間に強い相関があっても、n_virtual_samples 個のサンプルはランダムで生成していますので x の間の相関は 0 であるため、多重共線性の影響はなく線形モデルの回帰係数を寄与度として信用できます。この信用できる局所的な回帰係数を、LOMP として用いて非線形の回帰モデルを局所的に解釈します。
ちなみに、同じ論文にある kNN-LOMP, kNN-LIME, kNN-SHAP も計算できます。
- demo_knn_lomp.py
- demo_knn_lime.py
- demo_knn_shap.py
ご参考になれば幸いです。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。