金子研の論文が ACS Omega に掲載されましたので、ご紹介します。タイトルは
です。これは 2023 年 1 月現在、社会人ドクターの森下敏治さんが取り組んだ研究の成果です。
実験と、その結果である実験データを用いた機械学習による次の実験条件の提案を繰り返して、目標の物性値・活性値をもつ材料を効率的に開発するとき、ベイズ最適化が用いられます。

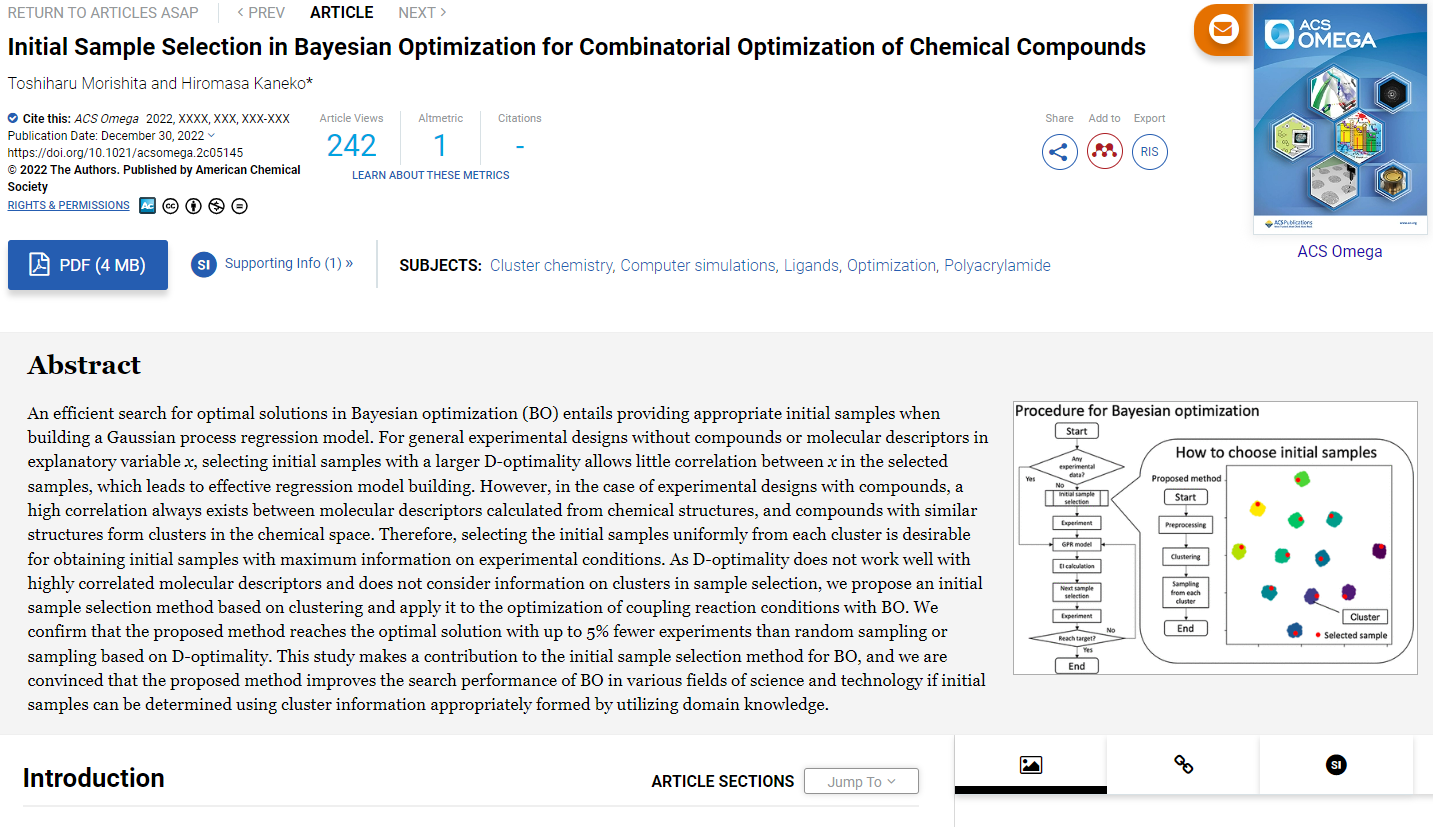
ベイズ最適化で次の実験条件を効果的に探索するためには、ガウス過程回帰 (Gaussian Process Regression, GPR) モデルを適切なサンプルで構築することが重要です。本研究では特に、まだ実験データがないときに、初期サンプルを作成することに着目しました。
実験前なので、物性や活性といった目的変数 y や、y と実験条件である説明変数 x との関係は、まだわかりません。そのため、x の情報のみを用いて初期サンプルの x の候補を作成する必要があります。一般的には、実験計画法によって、D最適基準が大きくなるように初期サンプルの x の候補を選択します。
これにより、実験条件同士に相関がないような初期サンプルの x の候補を選択でき、GPR モデルの構築のための初期サンプルの実験データが効率よく得られます。
一方で、x である実験条件に化合物を含むとき、初期サンプルの x の候補を選択することは、化合物の組み合わせを選択することを含みます。そのため x には、化合物の化学構造から計算される分子記述子が含まれます。このような化合物や分子記述子を扱うとき、他の実験条件とは状況が異なります。
まず、他の実験条件とは異なり、x のサンプル候補をどのように選択しても分子記述子には必ず相関関係があります。例えば、RDKit で計算される、分子量と水素原子以外で計算される分子量の間には相関があります。次に、化合物の種類は限られますので、選択される化合物の種類ごとに、サンプルがクラスターを形成します。
そのため、実験条件が類似しないような x の初期サンプルの候補を作成したいとき、各クラスターから まんべんなく選択されることが望ましいですが、D最適基準ではクラスターの情報は考慮されていません。また、x 間に必ず相関関係があるため、相関がなくなることを目指すD最適基準による選択では、適切なサンプルを選択できないと考えられます。
そこで、化合物の種類ごとにクラスターを形成するという特徴を考慮して、クラスター情報に基づいた x の初期サンプル候補の選択方法を提案しました。クラスタリングを行った後に、クラスターごとにD最適基準に基づいて x のサンプル候補を選択します。
論文では、化合物を含む実験条件として、カップリング反応の実験条件の最適化を対象にして、ベイズ最適化を実施しました。クラスタリングを行った後に、各クラスターから x の初期サンプルの候補を選択したところ、ランダムサンプリングによる候補の選択やD最適基準に基づく候補の選択を用いた場合と比較して、少ない実験回数で最適な実験条件に到達できることを確認しました。さらに、ベイズ最適化による実験条件の提案ごとに、実験できる数が小さいときほど、他の手法と比較して実験回数低減の効果が大きく、探索に要する実験回数が小さくなることがわかりました。
適切なクラスタリングとは、クラスターごとに所属するサンプル数が均一であり、y への寄与が大きいと考えられる実験条件でクラスターが形成できる場合のことといえます。ドメイン知識を活用して適切に形成されたクラスターを用いて初期サンプルの候補を決められれば、ベイズ最適化の探索性能をさらに向上させることが可能になります。
興味のある方は、ぜひ論文をご覧いただければと思います。どうぞよろしくお願いいたします。
以上です。
質問やコメントなどありましたら、twitter、 facebook、 メールなどでご連絡いただけるとうれしいです。