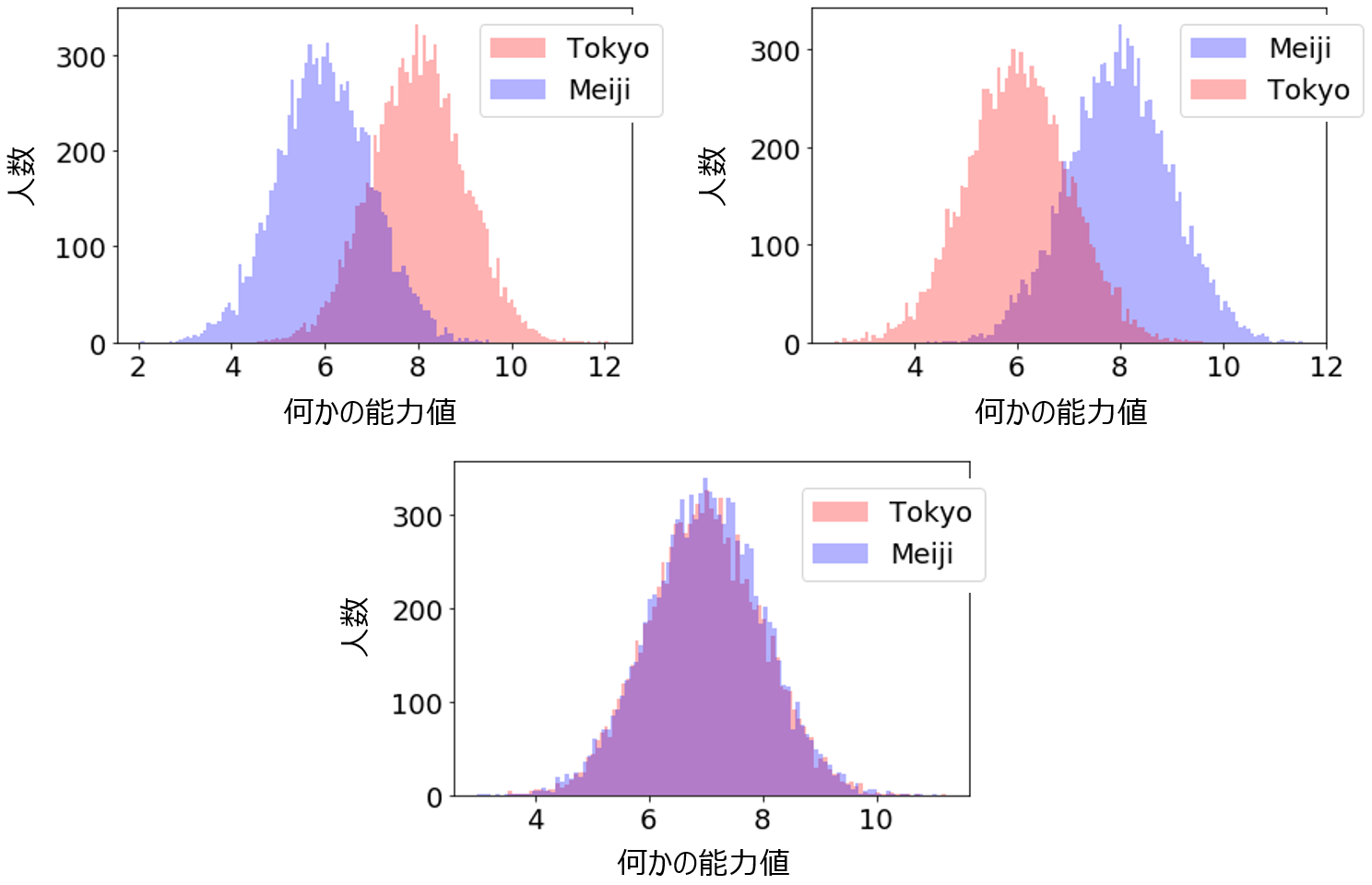
いろいろと共同研究やコンサルティングをしていますと


やはり多いのは、モデルの逆解析です。


新たな分子を設計したり、新たな材料を作るための実験レシピやプロセスを設計したり、装置を設計したりといった話です。
モデルの逆解析をするためには、もちろんモデルが必要です。データベースを用いて、説明変数 (設計変数・記述子) X と目的変数 Y との間で、たとえば回帰モデルを構築します。構築されたモデルに基づいて、新たな分子や、新たな材料を作るための実験レシピ・プロセス条件や、シミュレーション条件などを提案します。
モデルを構築するとき、もちろんモデルの推定性能は高い方がよいです。さらに、適応的実験計画法において、基本的にベイズ最適化をすることが多く、
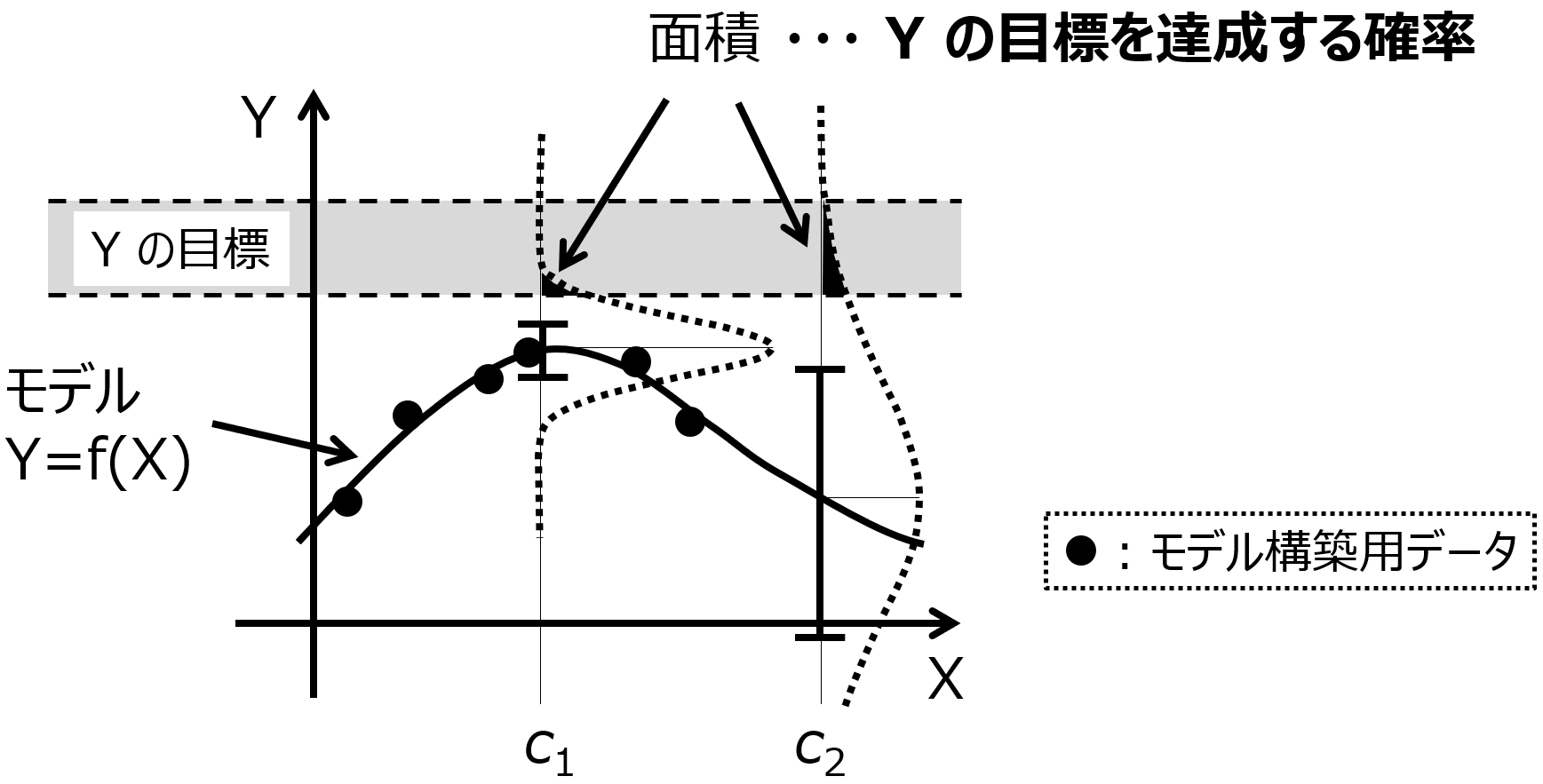
新たな候補を提案するときに、たとえば Y の目標を達成する確率は高いほうがよいです。
ただ、モデルの推定性能がように上がらなかったり、新たに提案された候補における Y の目標を達成する確率が小さくなってしったりすることもあります。このときに、モデルやモデルの逆解析を行った結果が、何の役にも立たないかというと、そうではないのです。
モデルの逆解析するとき、基本的には乱数で新しい化学構造や新しい実験レシピ・プロセスの候補を発生させます。

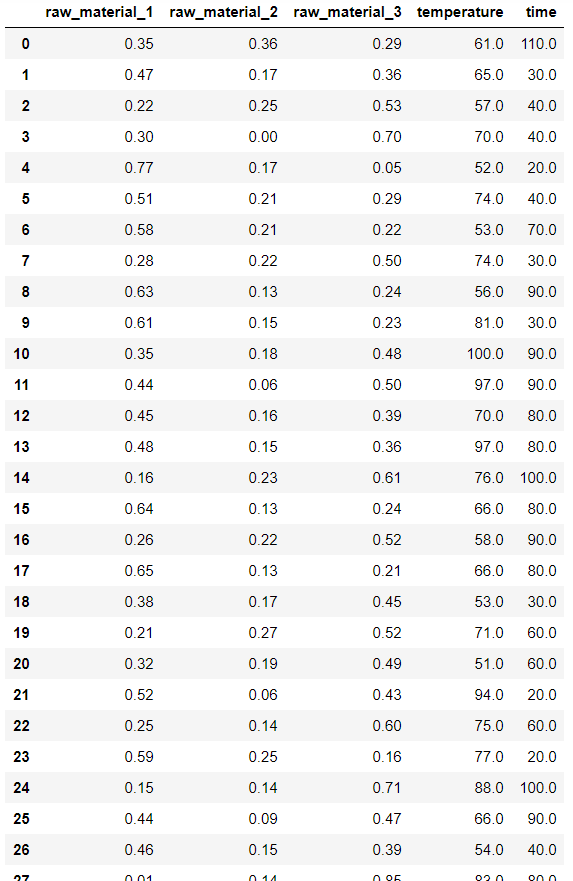
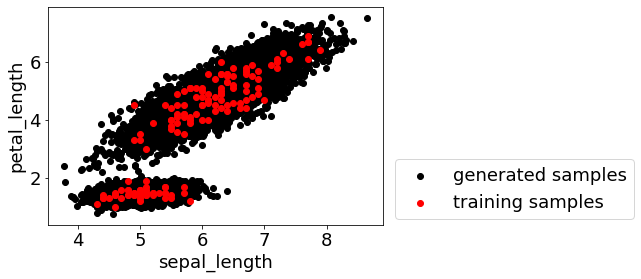
これが、けっこう役に立ちます。
一つは過去の実験を総括するのに役立つケースあります。たとえば、乱数に基づいて生成した候補について Y の値を推定し、その推定値がよい候補とか悪い候補とかを実際に見て確認します。そうすると、よいときはこんな実験条件で、悪いときはこんな実験条件だったのか、といったように、頭の中で整理ができます。
もう一つは、新たな発想が出てきたり、インスピレーションが湧き上がるのに役立つケースがあります。これまで似たような実験条件で実験してたり、同じようなパターンで実験していたり、ある範囲内でのみ実験することが多かったりすると、それを逸脱できない状況があったりします。モデルの逆解析では、新たな候補は基本的に乱数に基づいて発生されますので、これまで考えていなかったような実験条件も出てきます。このような候補を実際に見ることで、こんな実験条件もありだね、とか、こんな実験条件で実験してみてもいいかもね、といった新たな発想につながります。
以上のように、モデルの逆解析そのものにメリットがありますので、モデルの推定精度がよくなかったから止めてしまったりとか、ベイズ最適化における Y の目標を達成する確率が低かったから提案するのを止めてしまったりとかはもったいないです。実際に、当事者や現場の方に見てもらうのが、とてもよいと思います。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。