機械学習にチャレンジしてみたい、自分のもっているデータを使って機械学習してみたらどうなるか確認してみたい、という方はいらっしゃると思います。実際に機械学習をやってみて、よい結果が出ると、さらに機械学習をするモチベーションになるかもしれません。
ただ、とりあえず機械学習を試してみるといっても、
- 使用するツールの使い方を調べる必要がある (けっこう複雑なツールだったりすることも・・・)
- プログラミングにより機械学習を実行するときは、プログラミングを学ばないといけない
といった感じで、特にプログラミング未経験者やパソコンが苦手な方々にとって、ハードルは高めです。
また、ちょっと機械学習を試してみるにしても、間違って解析してしまって悪い結果が出たら、それで諦めてしまいもったいないです。逆に、よい結果が出ても、それが間違えによってよい結果になっていたとしたら、それに気付くまでの時間がもったいないです。たとえば、モデルの適用範囲 (Applicability Domain, AD) を考慮せずに、物凄い外挿を予測していて、その予測結果を真として信じてしまい、後に実測値が合わないことに気付く、といった感じです。

つまり、
簡単に、正しく機械学習を試してみる
ことが求められているわけです。
そこで今回は、機械学習の中でも回帰分析を対象にして、クリックだけで機械学習を試せるアプリ 「DCE tool」 を作りました。なお Windows 10 Pro でのみ動作確認をしており、特に macOS では使用できないと思います。ご注意ください。
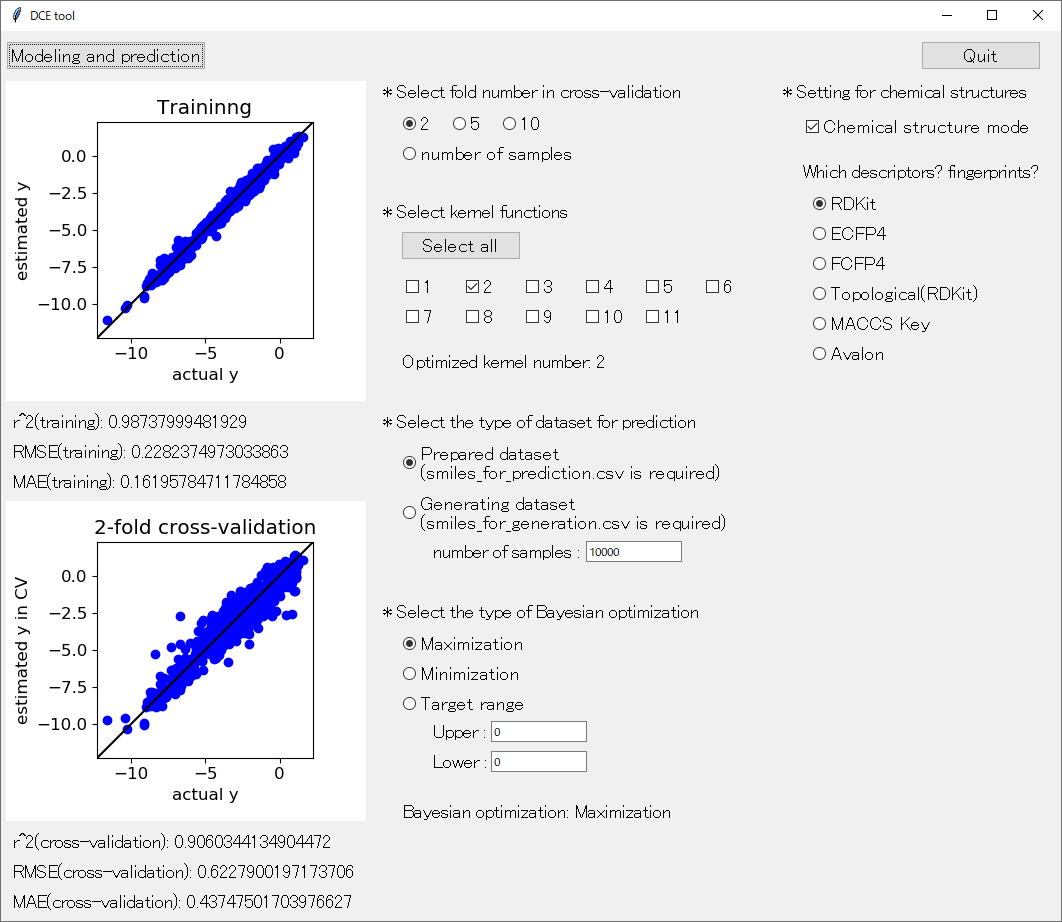
なお、「DCE tool」には機能が追加されました。以下の説明を読んだ後に、こちらもご覧ください。
搭載されている手法は、ガウス過程回帰 (Gaussian Process Regression, GPR) です。
カーネル関数は以下のサイトの 2 番目のものです。

この GPR により以下の 3 つのことができます。
- 目的変数 Y と説明変数 X との間で回帰モデル Y = f(X) を構築する
- クロスバリデーションによりそのモデルの推定性能を評価する
- Y の値がわからないサンプルにおける X の値を回帰モデルに入力して、Y の値、およびその標準偏差を予測する
Y の予測値と一緒に、その標準偏差も出力されますので、予測値の信頼性、すなわち AD も考慮できるわけです。
それでは今回のアプリ DCE tool の説明をします。まず以下から zip ファイルをダウンロードし、解凍してください。
解凍しましたら、その dcetool フォルダの中で、dcetool.exe を探してください (ファイルの数が多くてすみません。。。)。下図のように見つかると思います (拡張子を表示しない設定ですと、「dcetool」 しか表示されないかもしれません)。
見つかりましたら、dcetool.exe (もしくは dcetool) をダブルクリックしてください。少し時間が経った後に、下のようなウィンドウが開くと思います。
同時に以下のような黒いウィンドウも開きますが、気にしなくて構いません (不具合が起きたときの原因探索に役立ちますが、問題ないときは特に使用しません)。
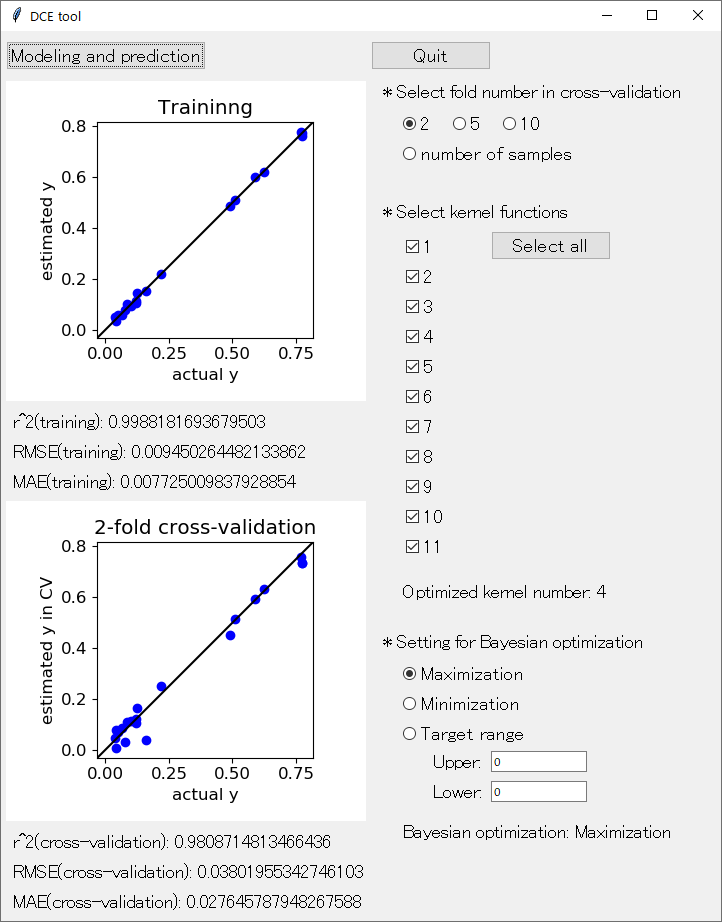
次に、「Modeling and prediction」 と書かれたボタンをクリックしてください。少し時間が経った後に、下の画面になると思います。
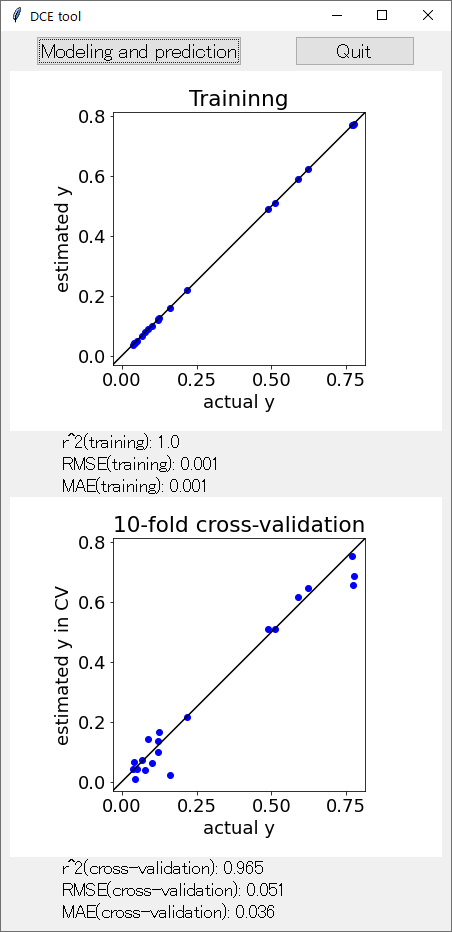
これで、このアプリでできるすべての解析が終了します。どんな解析をしているか、上の図の意味はなんなのか、説明します。
DCE tool ではまず、同じフォルダにある以下の 2 つのデータセットを読み込みます。
- training_data.csv : トレーニングデータ。このデータを用いて GPR モデルを構築します
- x_for_prediction.csv : 予測用のデータ。構築された GPR モデルに入力して、Y の値およびその標準偏差を予測します
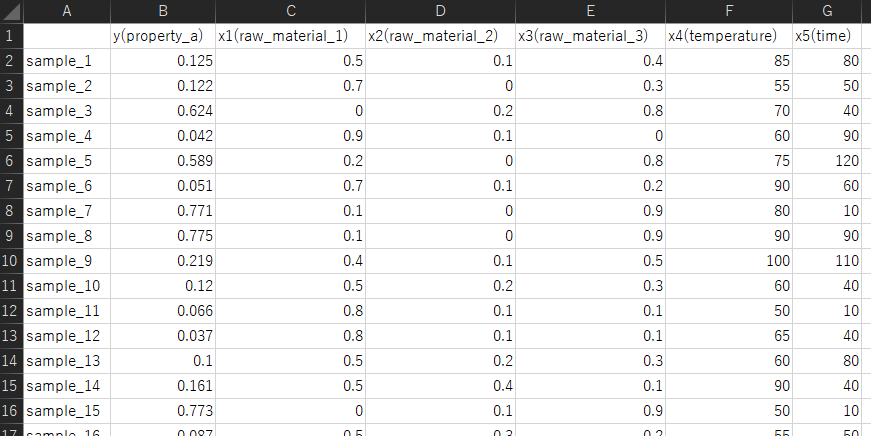
今回は、サンプルデータセットとして、以下の図のような training_data.csv と x_for_prediction.csv があります。
training_data.csv
↓
x_for_prediction.csv
↓
training_data.csv は、一番左の列がサンプル名、次の列が Y、その次からが X です。一番上の行が変数名で、その下からが実際のデータセットです。x_for_prediction.csv は、一番左の列がサンプル名、次の列からが X です (Y はありません)。一番上の行が変数名で、その下からが実際のデータセットです。
training_data.csv で GPR モデルを構築し、同じ training_data.csv の Y の値を推定した結果が、上の実測値 (actural y) vs. 推定値 (estimated y) のプロットと、r^2(training), RMSE(training), MAE(training) です。r2, RMSE, MAE についてはこちらをご覧ください。

GPR モデルなので、この結果の推定誤差はほとんど 0 になると思います。では、新しいデータに対する予測精度はどれくらいか?、ということで、10-fold クロスバリデーションをします。クロスバリデーションについてはこちらをご覧ください。
クロスバリデーションによって Y の値を推定した結果が、下の実測値 (actural y) vs. 推定値 (estimated y in CV) のプロットと、r^2(cross-validation), RMSE(cross-validation), MAE(cross-validation) です。
その後、構築されたGPRモデルに x_for_prediction.csv の X の値を入力し、サンプルごとの Y の値およびその標準偏差を推定します。
モデル構築や予測の結果は、同じフォルダに results フォルダが作成され、そこに以下の 4 つの csv ファイルと、2 つの png ファイルして保存されます。
- statistics.csv : r^2(training), RMSE(training), MAE(training), r^2(cross-validation), RMSE(cross-validation), MAE(cross-validation) [ウィンドウに表示されている値と同じです]
- estimated_y_in_detail.csv : 上の実測値 (actural y) vs. 推定値 (estimated y) のプロットに対応する結果。サンプルごとに、実測値 (actual_y)、推定値 (estimated y), 推定誤差 (error_of_y(actual_y-estimated_y) が並んでいます
- estimated_y_in_cv_in_detail.csv : 下の実測値 (actural y) vs. 推定値 (estimated y in CV) のプロットに対応する、クロスバリデーションの結果。サンプルごとに、実測値 (actual_y)、推定値 (estimated y), 推定誤差 (error_of_y(actual_y-estimated_y) が並んでいます
- predicted_y_in_x_for_prediction.csv : x_for_prediction.csv に対する Y の予測結果。サンプルごとに、予測値(predicted y)、予測値の標準偏差(std of predicted y)が並んでいます
- yy_plot_in_training.png : 実測値 (actural y) vs. 推定値 (estimated y) のプロット [ウィンドウに表示される図と同じです]
- yy_plot_in_cross_validation.png : 実測値 (actural y) vs. クロスバリデーション推定値 (estimated y) のプロット [ウィンドウに表示される図と同じです]
予測値が望ましい値であり、かつ標準偏差が小さい (予測値が確からしい) サンプルが望ましいといえます。
なお終了するときは、「Quit」ボタンか右上の × ボタンをクリックしてください。
ご自身のデータセットを、training_data.csv, x_for_prediction.csv と同様の形式で整理していただければ、このアプリで解析することができます。Y の数は 1 つにする必要がありますが、X の数およびサンプル数はいくつでも構いません。ただし、training_data.csv の X の変数名と x_for_prediction.csv の X の変数名とは、まったく同じにしてください。
以上が本アプリの説明になります。ぜひご活用いただき、さらなるデータ解析・機械学習のためのモチベーションにつなげていただければと思います。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。
