
今回はデータ解析によって構築した回帰モデルやクラス分類モデルの使い方についてお話しします。使い道は大きく二つに分けられます。一つはモデルの逆解析、もう一つは目的変数 Y の評価です。
モデルの逆解析
モデルの逆解析では、Y の値が望ましい値になるように、モデルを用いて説明変数 X の値を設計します。詳細はこちらをご覧ください。


基本的にはモデルの適用範囲 (Applicability Domain, AD) 内で X の値を設計することになりますが、

例えば回帰分析においては、既存の Y の値を超越するような X の値を設計する必要があることもあります。その場合には、繰り返し実験することを前提としてベイズ最適化で X の値を設計するとよいでしょう。
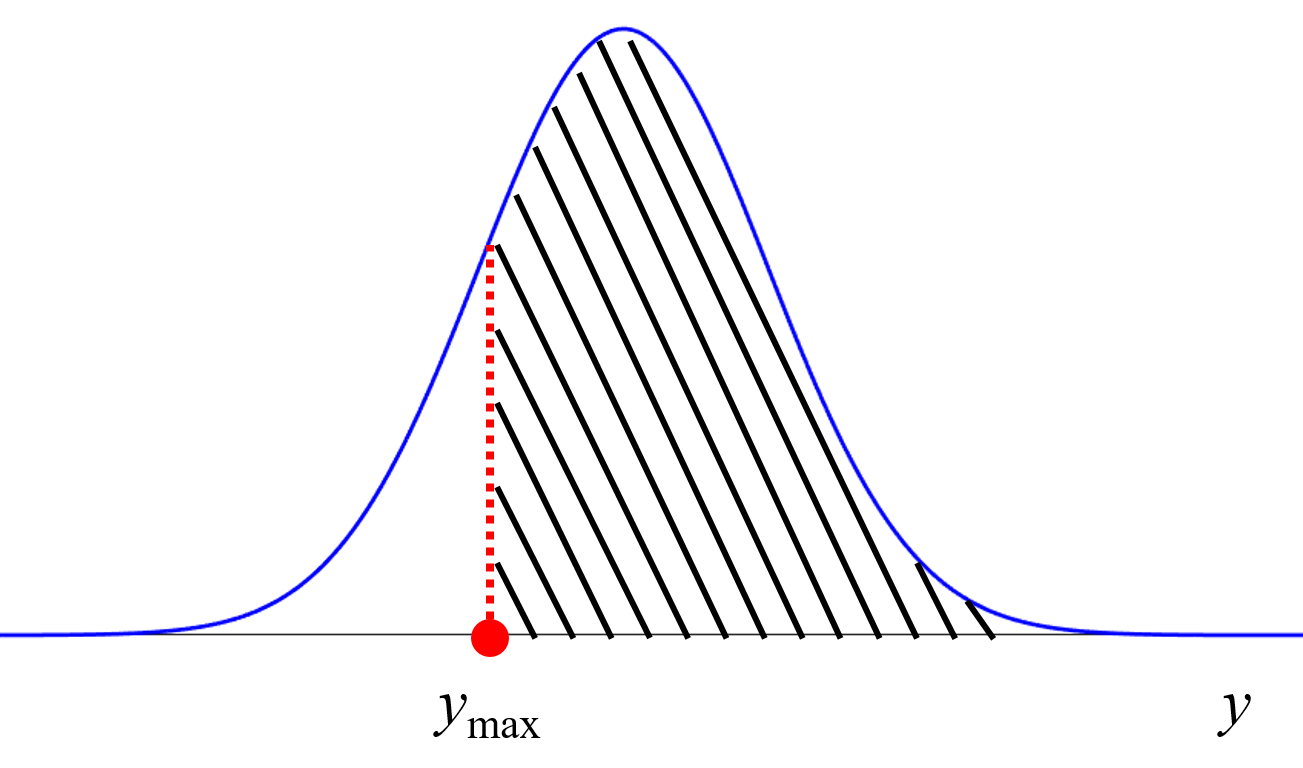
モデルの逆解析により、比較的に少ない実験回数で、効率的に X の値を設計できるようになります。AD 内で X の値を設計するのか、ベイズ最適化を利用するかについては、こちらの記事をご覧ください。

目的変数 Y の評価
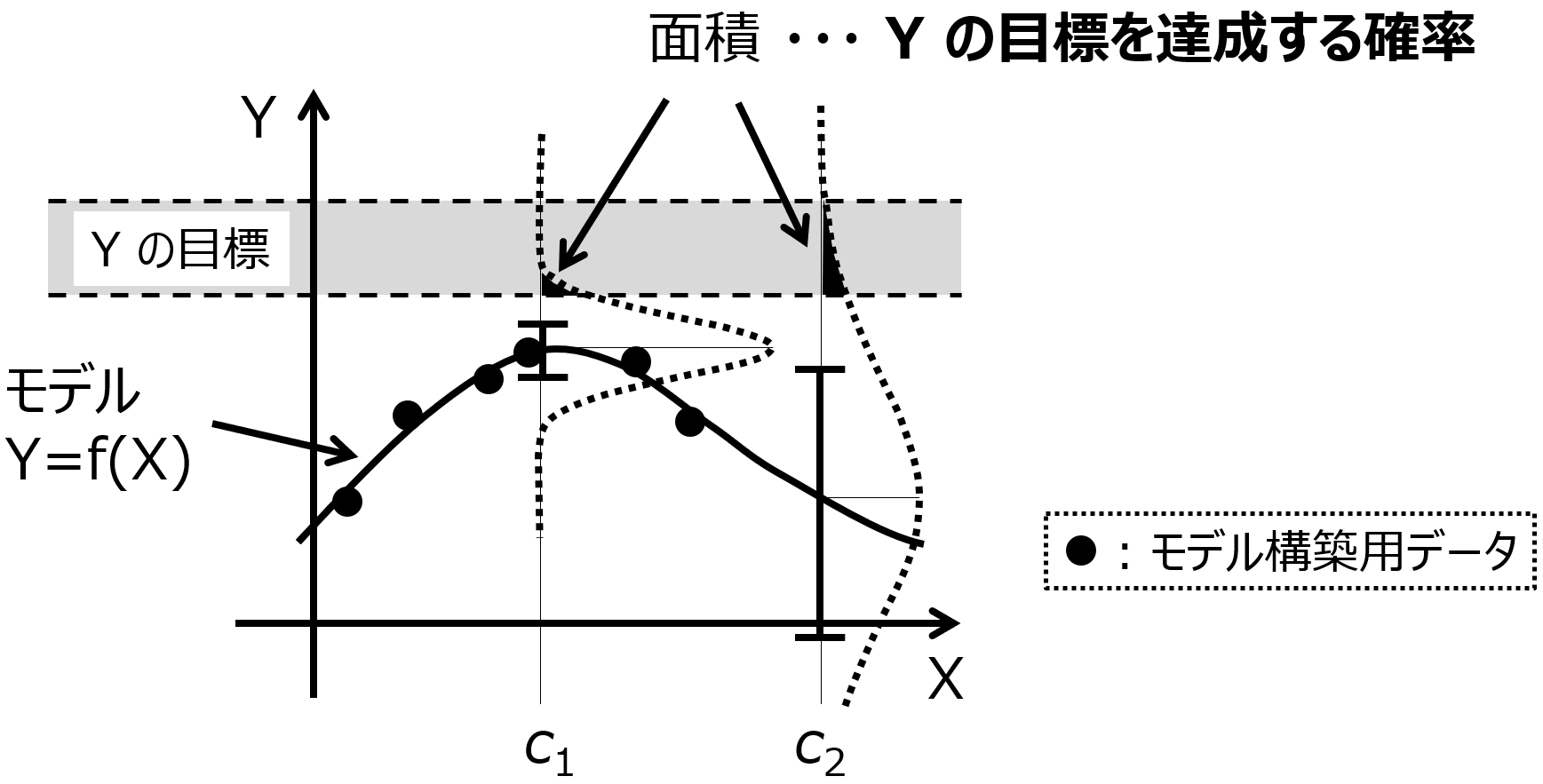
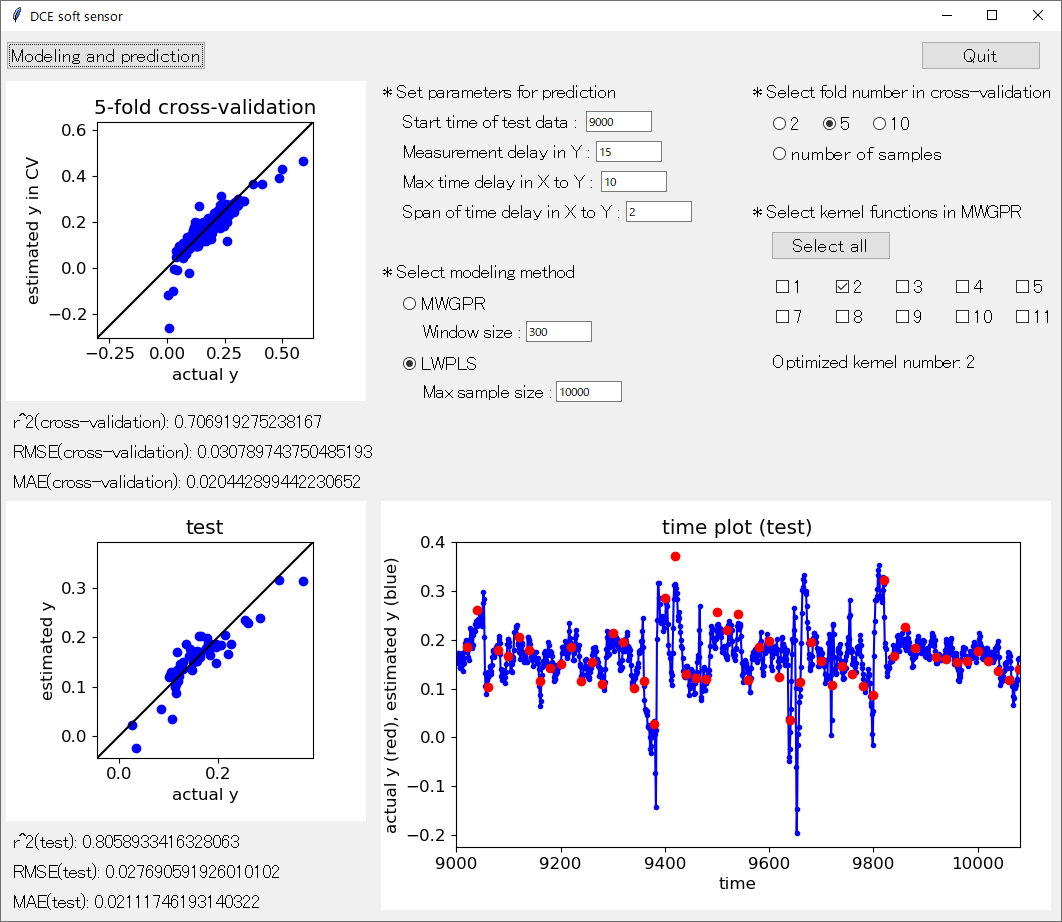
もう一つのモデルの使い方としては、Y の値の評価です。例えば、ある化合物がどの程度の毒性をもつか評価したり、他にも材料などの物性や特性の値が規格内かどうか評価したりします。ソフトセンサーも Y の値の評価ですね。
もしくは、ある実験条件の値から少し値がズレたときに、どの程度 Y の値がばらつくか、といったことも評価にあたります。なおモデルの逆解析のとき、この Y の値のばらつきについても考慮する方法についてはこちらに記載した通りです。
評価においては基本的に AD 内で議論をすべきです。 AD を超えた X の値に関しては、評価できないとか、評価された値には大きなばらつきがある、といった結果として考えるとよいと思います。
評価においても、本来であれば実験で評価するべきところをモデルによって評価することで、実験回数を減らすことができます。ある X の値付近での Y の値のばらつきの評価においても、そのための評価実験をすることなく評価できます。選挙において出口調査などの情報により開票率 0 % でも当確確定が出るようなことでしょうか。
以上のような、モデルを使うときに逆解析をするのか、Y の評価をするのか意識して使い分けると、それぞれにおいて適切な使い方ができ、必要なことが整理され、議論がスムーズになると思います。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。