
回帰分析やクラス分類のときに、アンサンブル学習をすることがあります。アンサンブル学習では、たくさんの回帰モデルやクラス分類モデルを構築します。一つ一つのモデルの予測精度は低くても、総合的にモデルを用いることで、予測精度を向上させることができます。

例えば、ランダムフォレストでは説明変数 x やサンプルをランダムに変えてたくさんの決定木を構築します。一つ一つの決定木の予測精度は低くても、それらを全て用いて予測し、回帰分析では予測値の平均値を、クラス分類では予測結果の多数決を最終的な予測結果とすることで、予測精度を向上させることができます。
アンサンブル学習では、x やサンプルをランダムに選択もしくはサンプリングするだけでなく、遺伝的アルゴリズムで選択することもできます。
また、たくさんのモデルを構築するとき、x やサンプルだけでなく回帰分析手法やクラス分類手法を変えてモデルを構築することもできます。このようにいろいろな手法で構築したモデルをすべて用いて予測するモデルを、特にコンセンサスモデルといいます。
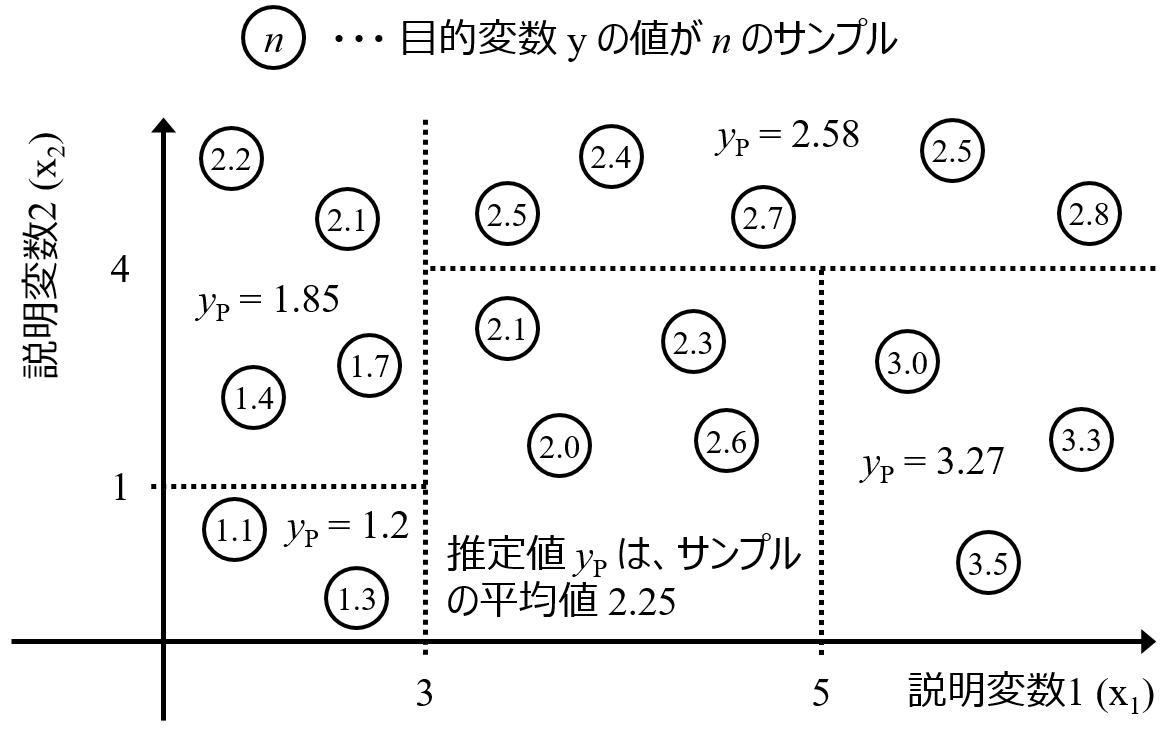
他には、あるデータセットにおける x と目的変数 y の間の関係が一つでは表せない場合、例えば化合物において物性を発現するメカニズムが複数あったり、プラントにおけるプロセス状態ごとに x と y の関係が変化したりする場合、x やサンプルを意図的に選んでモデルを構築することもできます。
以上のように、アンサンブル学習といってもいろいろな学習方法があります。最終的な予測結果を計算するとき、一般的なアンサンブル学習では、上で述べたように回帰分析では複数のモデルの予測値の平均値、クラス分類では複数のモデルの予測結果の多数決を用います。ただ、特にアンサンブル学習における一つ一つのモデルを意図的に工夫して構築した場合など、平均化すると当たりさわりのない予測結果になってしまい、予測精度が上がらないこともあります。
そんな時には、モデルごとに重みをつけるとよいです。例えば、クロスバリデーション後の予測値で計算した RMSE を RMSEcv としたとき、1 / RMSEcv2 を重みとすることで、クロスバリデーションの予測精度が高いモデルほど重みを大きくすることができます。
さらに、重みを予測するごとに変化させることで、x の値や予測している状態ごとに異なるモデルの重みを大きくすることができ、その x の値や状態が得意なモデルほど予測値を優先的に反映させることができます。例えばこちらの論文では、ソフトセンサーにおいて時間的に近いサンプルの予測値で計算された RMSE に基づいて、1 / RMSE2 を重みにすることで、直近のプロセス状態を予測できたモデルほど重みを大きくするようにしています。またこちらの論文では
モデルの適用範囲を利用することで、モデルの適用範囲内のモデルほど重みを大きくするような仕組みにしました。
以上のように、アンサンブル学習において重みを適切に設定することで、x と y の関係が複雑である場合でも柔軟にモデル設計をすることができます。ぜひ活用していただければと思います。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

