分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y = f(x) を構築し、構築したモデルに x の値を入力して y の値を予測したり、y が目標値となる x の値を設計したりします。
y の予測や x の設計ももちろん重要ですが、モデルを解析することによるデータセットからの知見獲得、知識獲得も多くの分野で求められています。ここでは機械学習モデルを解析・解釈することでデータセットから知見・知識を獲得する5つの方針について説明します。
1. y と関係している x だけ選択する
Boruta, GAWLS, GAVDS などを用いて、y を説明するための重要な x を選択します。

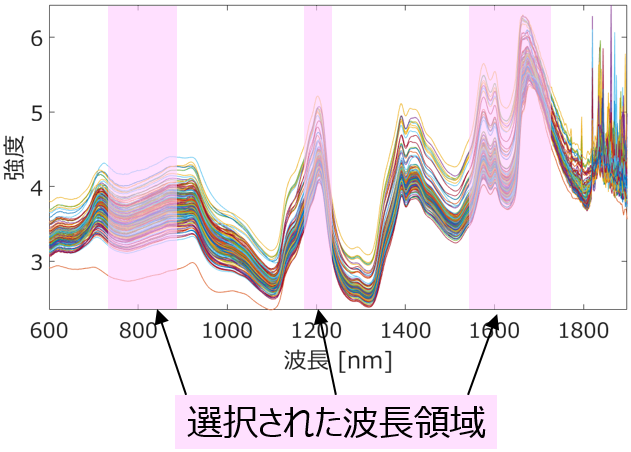
y を説明するために、どんな分子記述子が重要か、結晶構造のどんな特徴が重要か、スペクトルにおける重要な波長・波数はどこか、そして y に対してどのくらいの時間遅れで x が寄与しているか等を検討できます。
2. x の重要度を求める
CVPFI などを用いて、y に対する x の重要度を計算します。

y を説明するために、最も重要な分子記述子や結晶構造の特徴は何か、スペクトルにおける最も重要な波長・波数はどこか等を検討できます。
3. y に対する x の局所的な寄与を求める
LOMP などを用いて、y に対する x の局所的な寄与度を計算します。
ある (仮想的な) サンプル周りで、x の値をどのように変化させれば、y の値が大きくなったり小さくなったりするか、検討できます。なお、線形モデルの時はどんなサンプル周りでも同じ値です。

4. モデルを直接的逆解析して y が大きい値、中くらいの値、小さい値の時の x を求める
モデルの直接的逆解析では、y の値をモデルに入力することで、x の値を計算できます。


例えば y の大きめの値をモデルに入力して x を計算して、y の値を少し小さくしてモデルに入力して x を計算して、、、といったことを繰り返すことで、y の値を変化させる各 x の値の傾向や寄与の大きさを検討できます。
分子構造やプロファイルや画像など、サンプルが数値データとしての x で表現されていない場合は、直接特徴量化するプロセスを挟むことで、分子構造・プロファイル・画像として直接解釈することも可能です。


5. x を変化させてモデルに入力して y の予測値の変化を求める
ある (仮想的な) サンプルの x の値をモデルに入力して y の値を予測します。その後、着目した x の値のみ変化させて y の値を予測します。このときの y の予測値の変化を見ることで、着目した x を変化させることで y がどのように変化するか、検討できます。
分子構造やプロファイルや画像など、サンプルが数値データとしての x で表現されていない場合は、分子構造・プロファイル・画像を変化させてモデルに入力して y の予測値の変化を求めます。

以上です。
質問やコメントなどありましたら、X, facebook, メールなどでご連絡いただけるとうれしいです。
