
回帰モデルやクラス分類モデルを構築したあとは、それを効果的に使用するため、モデルの適用範囲 (Applicability Domain, AD) を設定する必要があります。

モデルは、説明変数 x の値が入力されれば、それがどんな値でも、目的変数 y の値を出力します。ただ、その出力された値を信頼できるかどうかは、x の値に依存します。それを議論するための概念が AD です。例えば、この x の値をもつサンプルは予測しても信頼できないとか、この x の値をもつサンプルはある程度信頼できるといったことを見積もれます。モデルを運用するときには、必ず AD が必要です。
ただ、AD を設定しさえすればそれで OK、というわけではありません。そもそもモデルを用いる目的は、x の値を入力して y の値を的確に予測したり、y の値が望ましい値となる x の値を適切に設計したりすることです。つまり AD が広いほどモデルの利用価値が高まります。
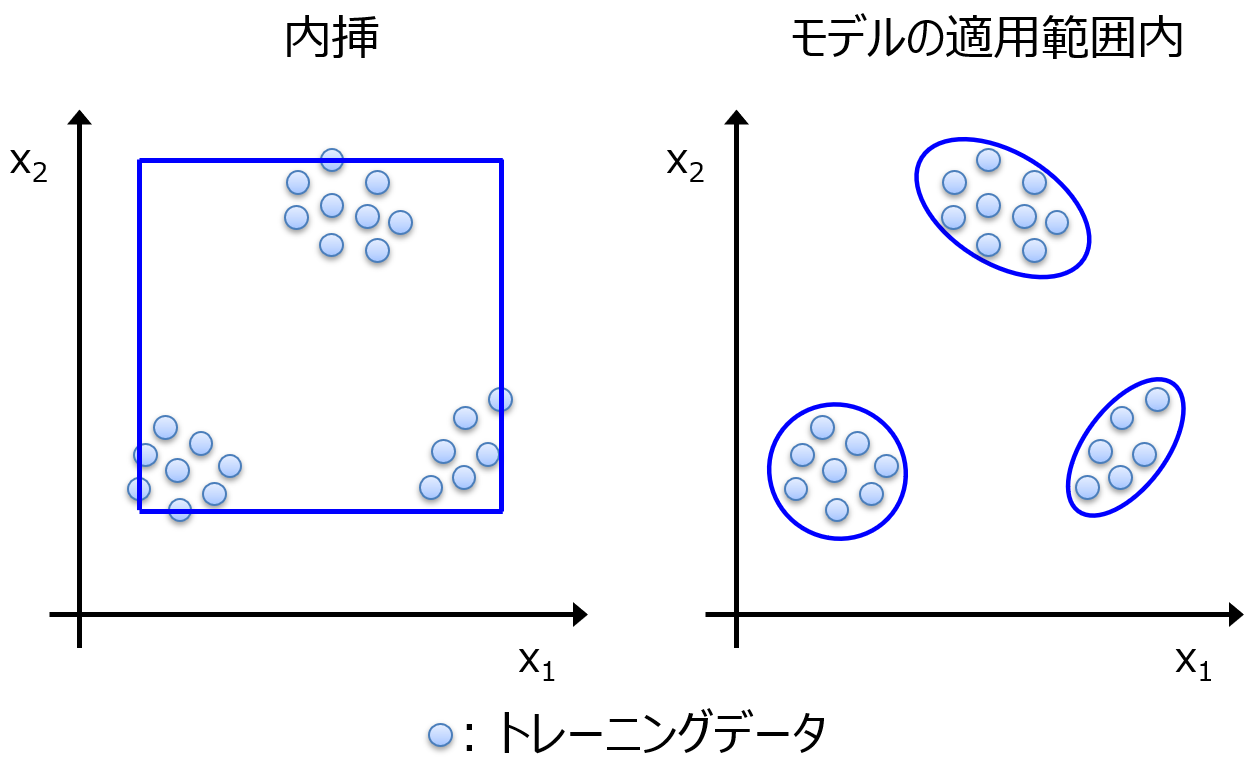
AD を広げる工夫も必要です。例えば外れ値が生じうる特徴量が x にあるとき、その特徴量に外れ値のあるサンプルが新たにモデルに入力されると、そのサンプルは AD 外となり、y の予測値は信頼できません。もし、その特徴量をモデル構築時に削除することができれば、同じサンプルを AD 内とできるかもしれません。これは AD が広がることを意味します。
このように、特徴量のセットを適切に選択することで、AD は広がる可能性があります。また、特徴量の複数のセットでモデルの構築と AD の設定を行い、それらの AD の和集合として、最終的な AD を計算することで、AD を広げることもできます。以下の論文のようなイメージです。
もちろん AD を設定することは必要であり、それ自体は大事なことですが、その後、次のステップとして AD を広げる工夫をしてみるとよいと思います。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

