
今回は決定木やランダムフォレストの活用方法についてです。
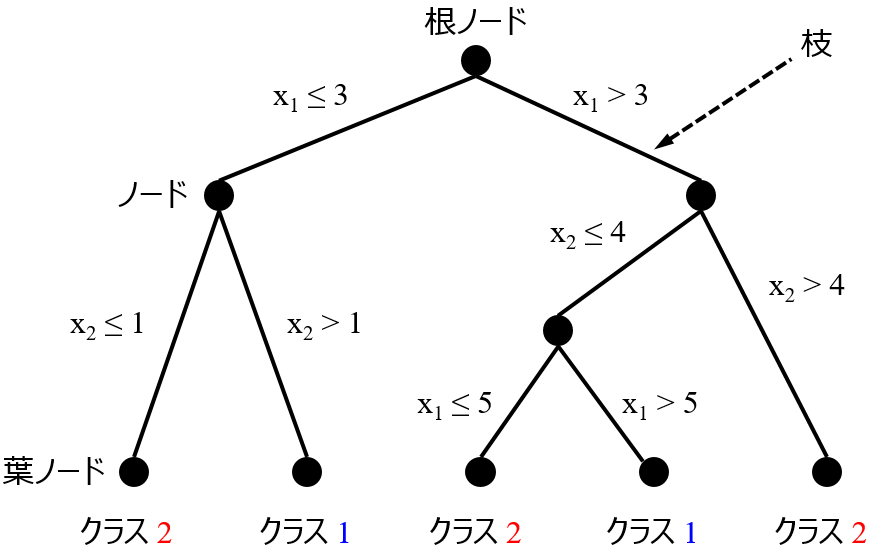
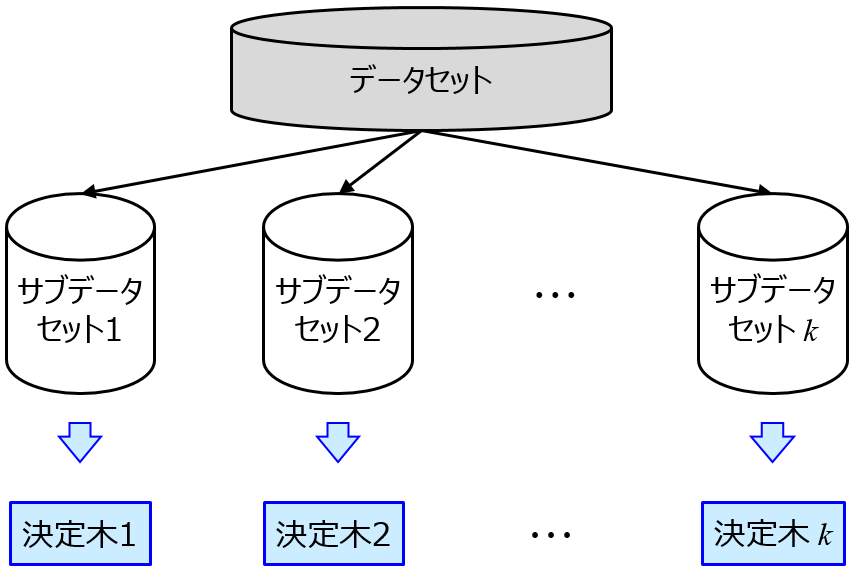
というのも、決定木やランダムフォレストをクラス分類に用いるときは特に関係ないのですが、回帰分析に用いるときは、決定木やランダムフォレストによって構築されたモデルの特徴の一つに、目的変数 y の予測値に関して、トレーニングデータにおける y の最小値の最大値の間 (範囲) にしか予測値が入らないことが挙げられます。どんな説明変数 x の値をモデルに入力しても、y の最小値を下回ることはありませんし、最大値を上回ることもありません。
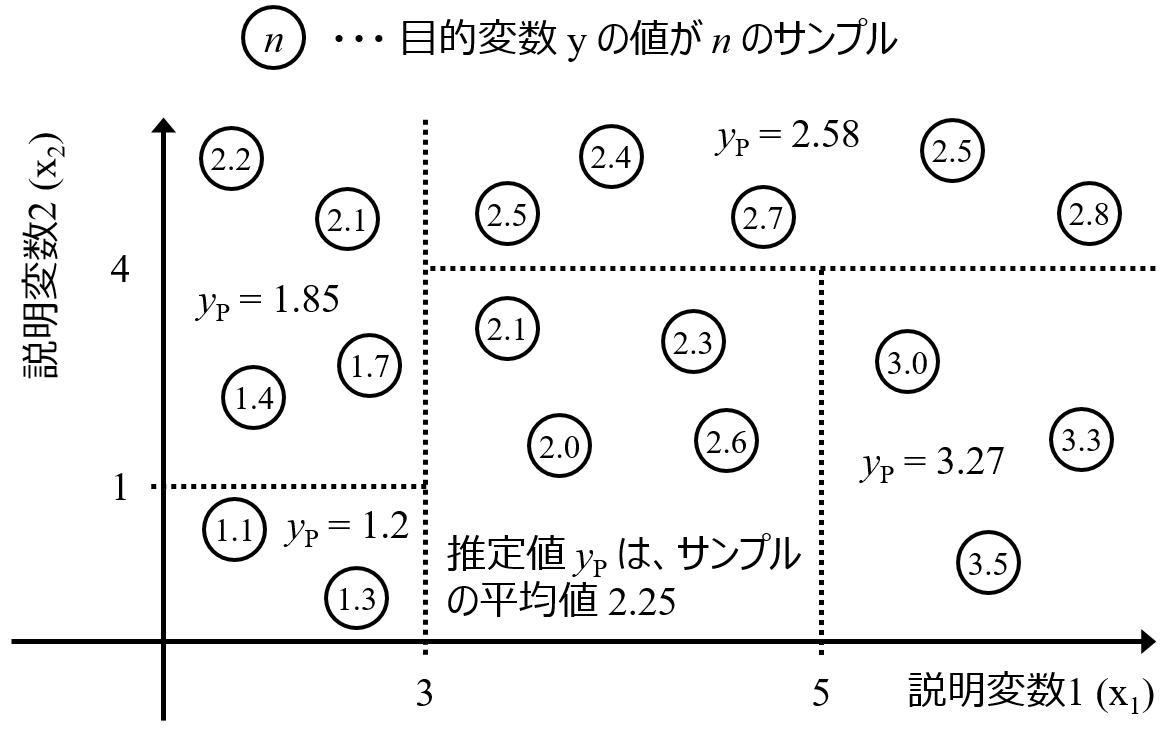
この特徴から、例えば分子設計や材料設計やプロセス設計において、既存の y の値を超える分子・材料・プロセスを設計したいときには、決定木やランダムフォレストは使用できません。
ただ、決定木やランダムフォレストが回帰分析のときに、まったく役に立たないかと言うと、そうではありません。今回は、上のような特徴をモデルがもつ決定木やランダムフォレストの活用方法について、大きく3つに分けて解説します。
一つ目は、y が複数あり、個別の y だけ見れば目標値をクリアしている一方で、すべての y の目標値を同時にクリアしているわけではないときの設計に使用します。y ごとにモデルを作って予測したとき、y は既存のデータにおける y の範囲を超えなくてもよいので、決定木やランダムフォレストを使用できます。複数の y がすべて目標に入るような設計であれば、決定木やランダムフォレストにより達成することは可能です。
二つ目は、設計ではなく評価に使用します。例えば物質を合成する前や合成した後に、(目標値があるわけではない) 物性を評価したいときや、装置やプラントにおけるソフトセンサーとして使用するときなどです。

このような場合は、物性・活性・特性等の y に目標値があるわけでなく、ある範囲内でどの値をもつのかを知ることが目的になりますので。決定木やランダムフォレストを使用できます。
三つ目は、x と y の関係を解釈したいときに使用します。決定木はモデルの構造的に x と y の間の関係の解釈がしやすいです。

またランダムフォレストでは特徴量の重要度を計算できます。このような情報を、x と y の間の関係の解明やメカニズムの解釈に活用できます。
以上のように決定木やランダムフォレストを活用する場面は多岐にわたります。目的に合わせてぜひ検討しましょう。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

