
分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y = f(x) を構築し、構築したモデルに x の値を入力して y の値を予測したり、y が目標値となる x の値を設計したりします。
最初に行う実験やシミュレーションの条件等の x を準備したり、モデルの逆解析をするための予測用サンプルを準備したりする際に、x の仮想サンプルを生成します。一般的には、乱数に基づいて大量の仮想サンプルを生成しますが、x 間に関係性がある場合には、それを満たす形で仮想サンプルを生成する必要があります。何らかの組成のように、一部の x の合計が 1、というような単純な数式で表現できる関係性の時には、乱数に基づいて生成した後に関係性を満たすように変換することが可能です。
一方で、時系列データとして自己相関といった関係性を持つ場合や、スペクトルデータやプロファイルデータとして x 間に強い相関関係がある場合や、化学構造もしくは SMILES といった数値データではない特徴を持つデータの場合には、単純な乱数では仮想サンプルの生成が困難です。
このような場合には、自己相関や x 間の相関、化学構造や SMILES の特徴を学習させた生成モデルを使用すると良いでしょう。例えば、混合ガウスモデル (Gaussian Mixture Models, GMM), 変分オートエンコーダ (Variational AutoEncoder, VAE), 敵対的生成ネットワーク (Generative Adversarial Networks, GAN), 拡散モデル (diffusion model) などです。これらにおいて、時系列データ、スペクトルデータ、プロファイルデータ、化学構造 (SMILES) データなどに内在するサンプルの特徴をモデルに学習させ、それに基づいて異なる仮想サンプルを大量に生成できます。なお、こちら↓で紹介した GMM に基づく仮想サンプル生成も、x 間の関係性が正規分布の重ね合わせで表現できるといった条件の生成モデルとして、仮想サンプルを生成しています。
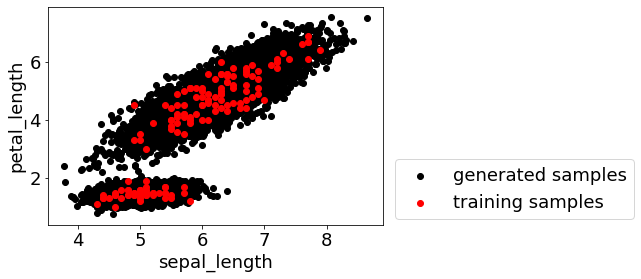
ちなみに、生成モデルを学習させるためのサンプルは、y がなくても OK です。例えば y は測定していない時間帯の時系列データを用いたり、PubChem や ChEMBL などに登録されている膨大な化学構造データを用いたりして、生成モデルを学習させることも可能です。
このような生成モデルで生成した仮想サンプルに基づいて、最初に実験するサンプルを選択したり、モデルの逆解析に入力するサンプルとして使用したりできます。もちろん、逆解析であれば直接的解析法により、上記の自己回帰や x の相関関係や化学構造や SMILES などの特徴を考慮して y の値から直接的に x もしくは時系列データ、スペクトルデータ、プロファイルデータ、化学構造を出力できます。

特徴のあるデータを用いる際はぜひ検討してみてください。
以上です。
質問やコメントなどありましたら、X, facebook, メールなどでご連絡いただけるとうれしいです。

