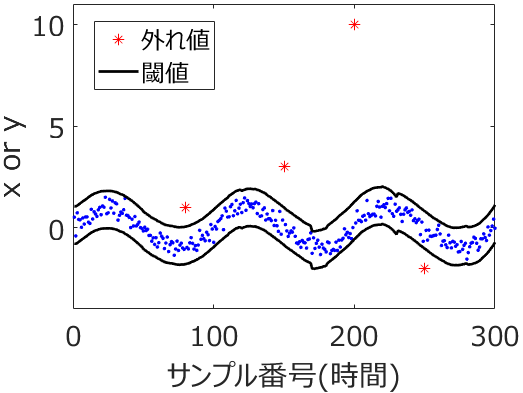
今回は外れサンプルを検出するお話です。外れ値ではなく外れサンプルです。外れ値は、他の値と (大きく) 離れた値のことであり、外れ値がデータ解析のときに悪影響を及ぼすことがあります。ただ、回帰分析のときには、大事なのは説明変数 X と目的変数 y との関係であって、y のデータの中に外れ値があっても、X のデータの中にも外れ値があり、かつ X と y との関係に それらの外れ値を含めて一貫性があれば、まったく問題ありません。問題なのは、他のサンプルと X と y との関係が異なる、外れたサンプルです。このサンプルのことを外れサンプルと呼びます。
外れサンプルを見つける手法はこちらの論文にあります。
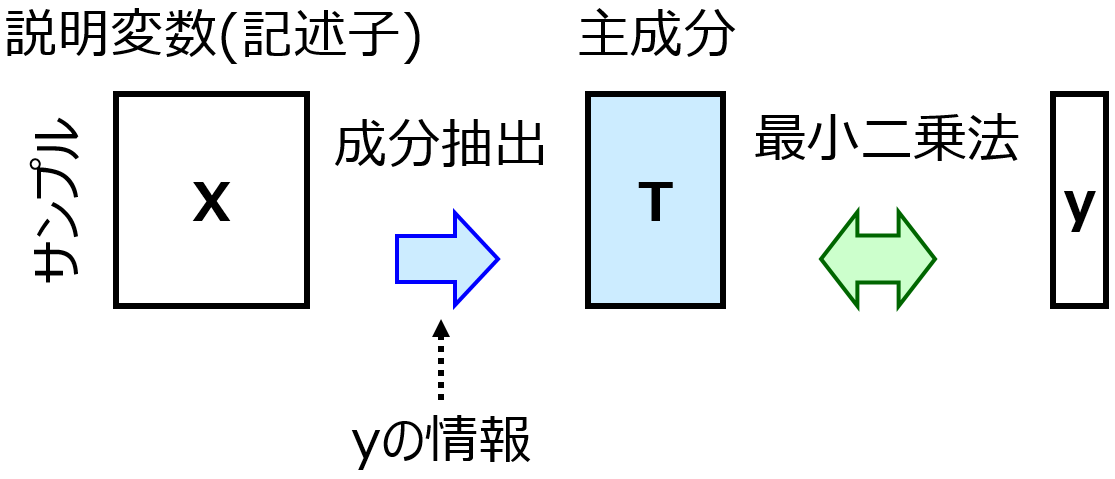
この手法は、回帰分析におけるアンサンブル学習と、中央値・中央絶対偏差といった、ロバストな (頑健な) 統計量にもとづきます。外れサンプルの見つけ方は以下の手順のとおりです。
- すべてのサンプルは外れサンプルではないとする
- 外れサンプル以外のサンプルで、サンプルをブートストラップ法でサンプリングするアンサンブル学習で、複数の回帰モデル (サブモデル) を構築する
- 外れサンプル以外のすべてのサンプルを用いて、すべてのサブモデルの推定値で中央絶対偏差を計算する (中央絶対偏差は 1 つの値になります)
- すべてのサンプルにおいて、目的変数の値を推定する。このとき推定値は、すべてのサブモデルにおける推定値の中央値とする
- すべてのサンプルにおいて、目的変数の実測値と推定値との間の誤差の絶対値が、3. の中央絶対偏差の 3 × 1.4826 倍を越えたとき、そのサンプルを外れサンプルとする
- 2. から 5. を繰り返し、外れサンプルが変わらなくなったら終了とする
以上の流れによって、あるデータセットが与えられたとき、他のサンプルと X と y との間の関係が異なるサンプルを、外れサンプルとして検出できるわけです。なお 5. において 1.4826 は、正規分布においては中央絶対偏差の 1.4826 倍が標準偏差に等しいことに、3 は 3 シグマ法の 3 に由来します。3 シグマ法についてはこちらをご覧ください。
論文では、2. におけるアンサンブル学習におけるサブモデルの数を 100 としています。
Python プログラムを公開します!
上で説明しました外れサンプルを見つける手法を実行する、Python プログラムを公開します。
[NEW] DCEKit でも外れサンプル検出の機能がついています。デモンストレーションもあります。

こちらの論文で数値シミュレーションとして用いたデータセットも一緒にありますので、とりあえず実行して外れサンプルを見つける様子を確認できます。実行しますと、外れサンプルが TRUE、外れサンプルではないサンプルが FALSE となるファイル outlier_sample_detection_results.csv が保存されます。回帰分析手法は、PLS と SVR に対応しています。PLS や SVR についてはこちらをご覧ください。

ぜひご活用ください。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。