非線形回帰モデルを解釈する[v2.12.1] (DCEKit) 分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と材料の物性・活性・特性や製品の品質などの y との間で、データセットを用いて機械学習により数理モ... 2023.01.01 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー研究室
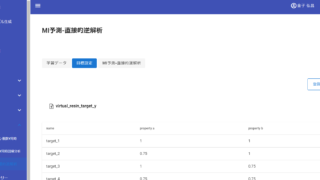
Datachemical LABで直接的逆解析ができるようになりました Datachemical LAB をご利用いただいている方が引き続き増えており、嬉しい限りでございます。これまでご紹介させていただいた通り、Datachemical LAB を使用することで、データの前処理・データの可視化・回帰分析・モデル... 2023.01.01 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー
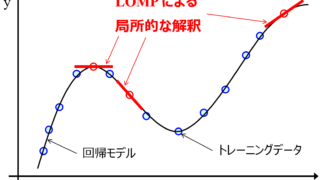
非線形回帰モデルを局所的に解釈する手法を開発しました [金子研論文] 金子研の論文が Digital Chemical Engineering に掲載されましたので、ご紹介します。タイトルはLocal interpretation of nonlinear regression model with k-ne... 2022.12.25 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室論文
深層学習に基づくニューラルネットワークのハイパーパラメータをベイズ最適化で高速に最適化する[v2.11.1] (DCEKit) 深層学習に基づくニューラルネットワークで回帰モデルを構築するときの話です。他の回帰分析手法と同様にして、scikit-learn でモデルを構築できると、何かと便利だったりしますので、今回は scikit-learn の MLPRegres... 2022.12.18 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー研究室
モデルの解釈は教師なし学習、データの可視化やクラスタリングと同じ位置づけとして実施しましょう! 分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と材料の物性・活性・特性や製品の品質などの y との間で、データセットを用いて機械学習により数理モ... 2022.12.18 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
清水亮太 氏を明治大学生田キャンパスにお招きして講演していただきました 2022年12月5日(月)に、東京工業大学で准教授をされている清水亮太 氏を明治大学生田キャンパスにお招きしまして、ゼオライトやその合成・設計・解析に関するご講演をしていただきました。清水先生が研究されているロボット-AIによる自律的物質・... 2022.12.11 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室講義
マテリアルズインフォマティクスとプロセスインフォマティックスを融合して材料の合成条件と製品のプロセス条件を同時に設計する手法を開発しました![金子研論文] 金子研の論文が ACS Omega に掲載されましたので、ご紹介します。タイトルはIntegration of Materials and Process Informatics: Metal Oxide and Process Desig... 2022.12.11 ケモインフォマティクスケモメトリックスデータ解析研究室論文
村岡恒輝 氏を明治大学生田キャンパスにお招きして講演していただきました 2022年10月24日(月)に、東京大学で助教をされている村岡恒輝 氏を明治大学生田キャンパスにお招きしまして、ゼオライトやその合成・設計・解析に関するご講演をしていただきました。村岡先生が研究されているゼオライトの計算科学や機械学習による... 2022.11.20 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
Datachemical LABで欠損値補完ができるようになりました Datachemical LAB をご利用いただいている方も増え続けており、嬉しい限りです。これまでご紹介させていただいた通り、Datachemical LAB を使用することで、データの前処理・データの可視化・回帰分析・モデルの逆解析・モ... 2022.11.20 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー
回帰モデルを運用するまでの、モデルの評価方法の整理 分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と材料の物性・活性・特性や製品品質 y との間で数理モデル y = f(x) を構築し、構築された... 2022.11.13 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室